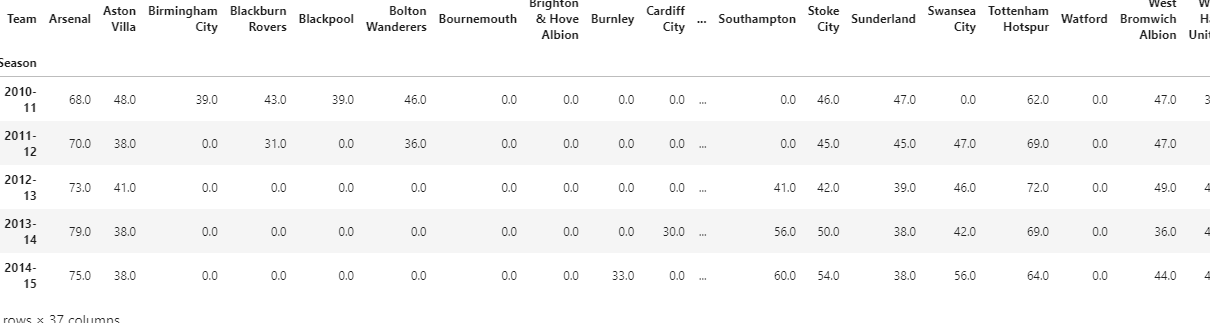
안녕하세요! ㅎㅎ
오늘은 folium을 이용해서 지리정보 시각화를 간단히 해 보려고 합니다.
그럼 시작하겠습니다!
Preview
step1. 데이터 준비하기
오늘 사용할 데이터는 서울 열린 데이터 광장의 '용산구 cctv 설치현황. csv'를 다운로드하여 시각화할 예정입니다.
아래의 링크를 눌러 csv파일을 다운로드 받아 주세요.
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
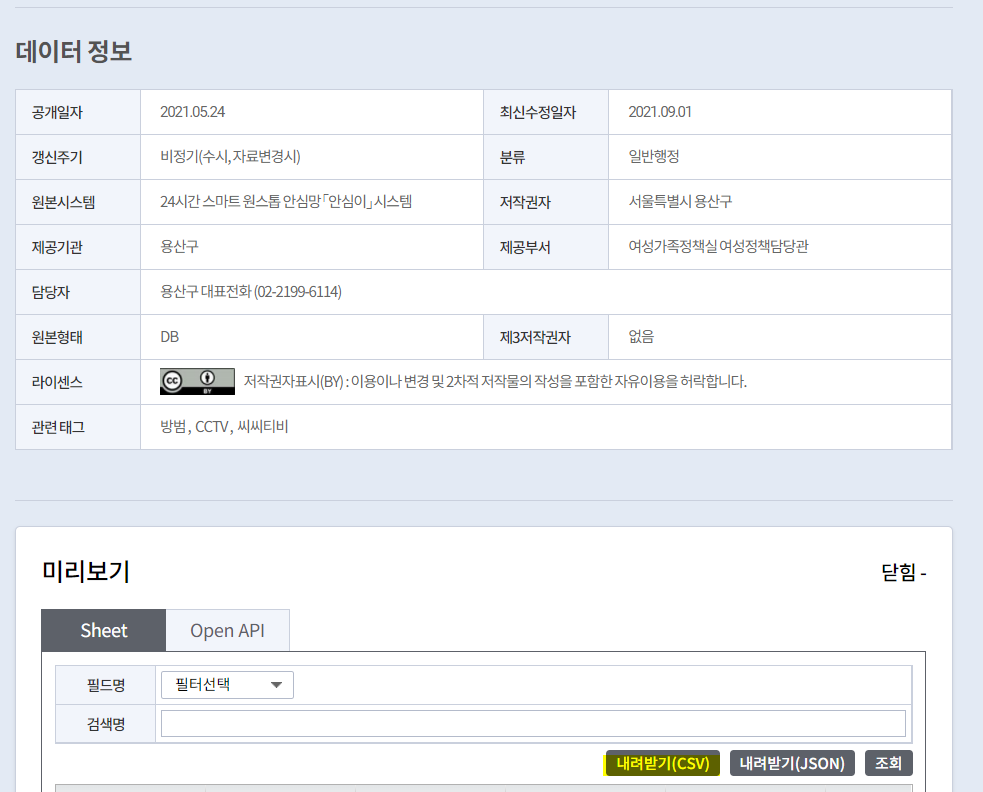
위의 내려받기(CSV)를 클릭하면 csv파일이 다운받아집니다:)
step 2. 위치정보 데이터 추출하기
위에서 다운로드하여준 csv를 열어 주고 내용을 확인해 보도록 하겠습니다.
항상 파일 위치를 열 때는 \를 //로 바꿔주어야 유니코드 오류가 뜨지 않고 잘 열 수 있습니다.
# CSV 파일 열기
import pandas as pd
file = r'C:\파일위치\yongsan_CCTV.csv'
file = file.replace('\\','//')
#print(file)
cctv_csv = pd.read_csv(file,encoding='cp949')
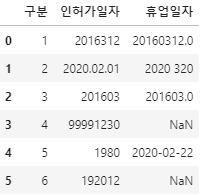
print(cctv_csv.head(5))출력:

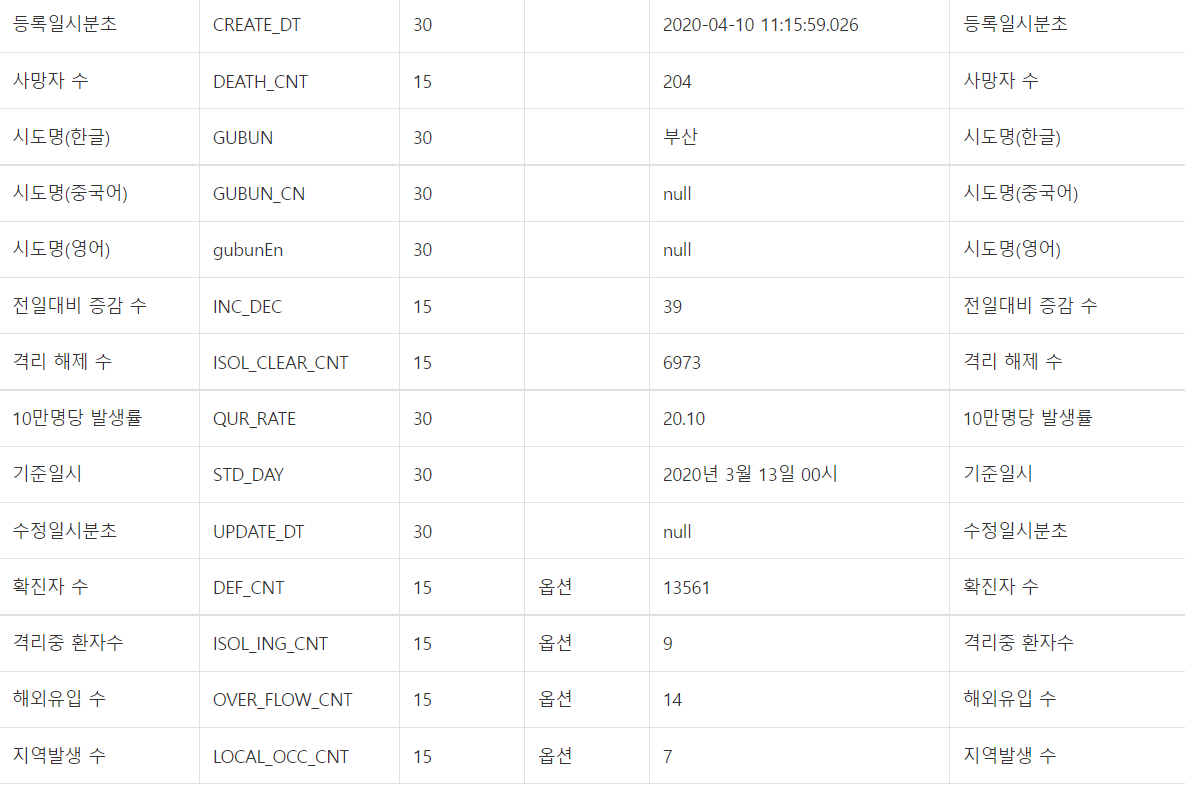
이렇게 용산구의 cctv가 있는 주소, x, y좌표 등등의 정보를 확인할 수 있습니다.
파일 중간중간 NAN이 있는 걸로 보아 위치 데이터에도 값이 없는 부분이 있을 수 있어
NaN이 있는 부분을 전부 0으로 바꾸어 주도록 하겠습니다.
# 데이터프레임 NaN 값 대체
cctv_csv = cctv_csv.fillna(0.0)
print(cctv_csv.head())출력:

위처럼 NaN이 0.0으로 모두 바뀌었습니다.
이제 위치를 지도에 표시하기 위해 x좌표(위도), y좌표(경도)를 따로 준비해 주도록 하겠습니다.
여기서 0.0 값(NaN값이었던)을 가지는 행은 제외하고 좌표를 리스트로 모아보도록 하겠습니다.
# x좌표(위도),y좌표(경도) 리스트로 만들기
x = []
y = []
for i in range(len(cctv_csv['WGS x좌표'])):
if cctv_csv['WGS x좌표'][i] == 0.0 or cctv_csv['WGS y좌표'][i] == 0.0:
pass
else:
x.append(cctv_csv['WGS x좌표'][i])
y.append(cctv_csv['WGS y좌표'][i])
print('x갯수: ',len(x))
print('y갯수: ',len(y))출력:
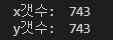
이렇게 위, 경도 각각 743개가 잘 들어가 있음을 확인할 수 있습니다.
step3. 지도에 위치 마커 표시하기
이제 folium을 이용해 지도를 불러오고, 불러온 지도에 CCTV 위치 정보를 표시하여 시각화해보도록 하겠습니다.
#지도 생성 및 marker 지정하기
import folium
map_osm = folium.Map(location=[x[13],y[13]],zoom_start=14)
for i in range(len(x)):
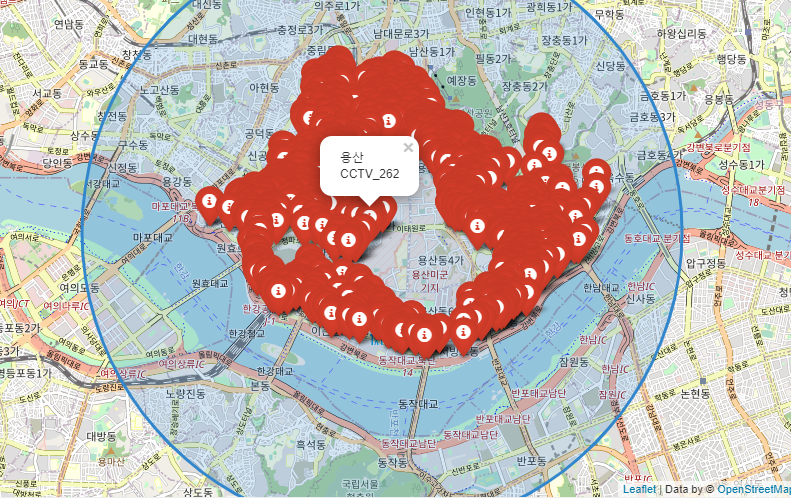
folium.Marker([x[i],y[i]], popup='용산CCTV_%d'%i, icon=folium.Icon(color='red', icon='info-sign')).add_to(map_osm)
# 지도에서 범위 지정
folium.CircleMarker(location=[x[13],y[13]],popup='용산구 CCTV', radius=300, color="#3186cc", fill_color="#3186cc").add_to(map_osm)
#map저장
map_osm.save('yongsan_cctv.html')출력:
위와 같이 Marker를 지정하면 아이콘 모양 및 색상을 정할 수 있습니다. pop-up은 지도에 표시되어 있는 아이콘을 클릭했을 때 나오는 설명 문구입니다.
여기에서는 csv의 cctv입력 순서에 따라 cctv_1 cctv_2 cctv3... 등으로 이름을 지정해 주었습니다.
또 서클 마커(CircleMarker)를 사용하면 위의 파란색 원과 같이 범위를 지정할 수 있습니다.
색 또한 지정 가능하니 참고하시면 됩니다.
전체 코드
# CSV 파일 열기
import pandas as pd
file = r'파일위치\yongsan_CCTV.csv'
file = file.replace('\\','//')
#print(file)
cctv_csv = pd.read_csv(file,encoding='cp949')
print(cctv_csv.head(5))
# 데이터프레임 NaN 값 대체
cctv_csv = cctv_csv.fillna(0.0)
print(cctv_csv.head())
# x좌표(위도),y좌표(경도) 리스트로 만들기
x = []
y = []
for i in range(len(cctv_csv['WGS x좌표'])):
if cctv_csv['WGS x좌표'][i] == 0.0 or cctv_csv['WGS y좌표'][i] == 0.0:
pass
else:
x.append(cctv_csv['WGS x좌표'][i])
y.append(cctv_csv['WGS y좌표'][i])
print('x갯수: ',len(x))
print('y갯수: ',len(y))
#지도 생성 및 marker 지정하기
import folium
map_osm = folium.Map(location=[x[13],y[13]],zoom_start=14)
for i in range(len(x)):
folium.Marker([x[i],y[i]], popup='용산CCTV_%d'%i, icon=folium.Icon(color='red', icon='info-sign')).add_to(map_osm)
# 지도에서 범위 지정
folium.CircleMarker(location=[x[13],y[13]],popup='용산구 CCTV', radius=300, color="#3186cc", fill_color="#3186cc").add_to(map_osm)
#map저장
map_osm.save('yongsan_cctv.html')
코드 파일
참고 문서
Folium — Folium 0.12.1 documentation
folium builds on the data wrangling strengths of the Python ecosystem and the mapping strengths of the leaflet.js library. Manipulate your data in Python, then visualize it in on a Leaflet map via folium. Concepts folium makes it easy to visualize data tha
python-visualization.github.io
마무리
오늘은 파이썬으로 지도위치 시각화하는 방법을 알아보았습니다ㅎㅎ csv파일과 위치 좌표만 있으면
간편하게 시각화가 가능합니다. 질문은 댓글 달아주세요 :)
'시각화(Visualization)' 카테고리의 다른 글
| [python/시각화] matplotlib으로 그래프 만들기- 히스토그램, 산점도, 박스그래프 (0) | 2021.12.15 |
|---|---|
| [python] CCTV,가로등 위치를 folium을 사용하여 clustering 시각화하기 (4) | 2021.11.17 |
| [python] 네이버 블로그 크롤링 결과로 WordCloud 시각화하기 (5) | 2021.11.10 |
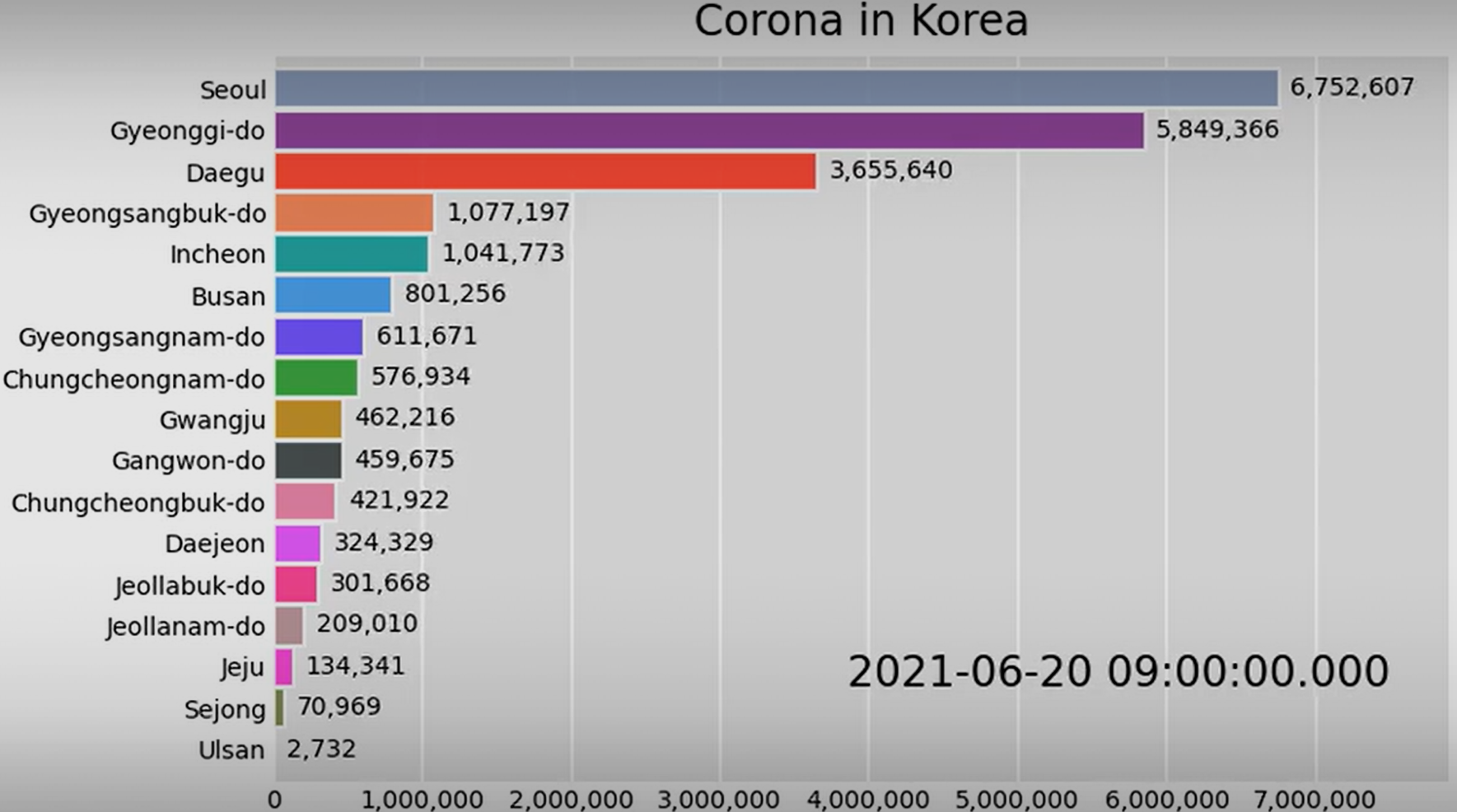
| [python] 공공데이터 코로나 확진자 데이터로 bar_chart_race 시각화하기 (3) | 2021.11.08 |
| [python] bar-chart-race로 시각화하기 (feat. 축구) (2) | 2021.10.29 |