
저번 게시물에 이어 OPEN API를 이용해 코로나 확진자 수를 bar_chart_race로 시각화 해 보겠습니다.
Preview
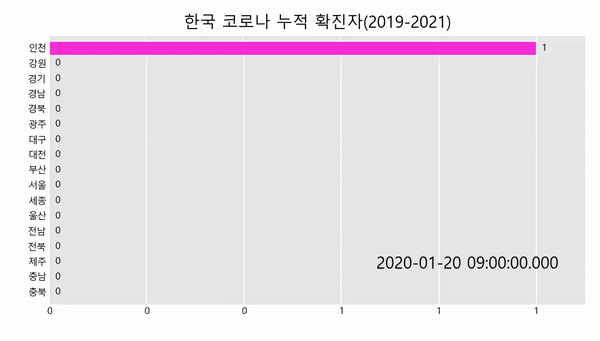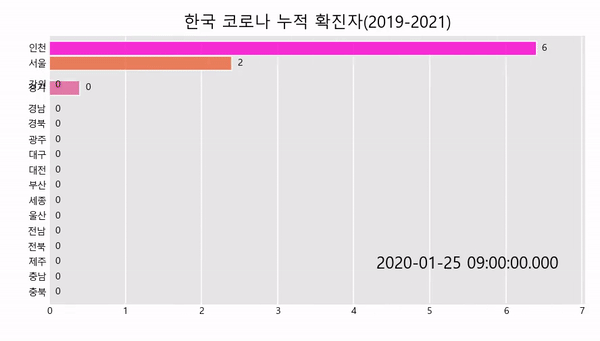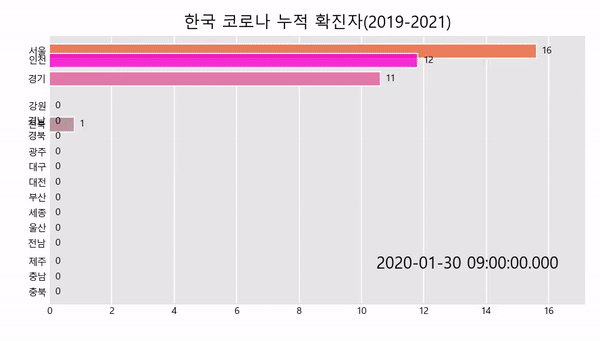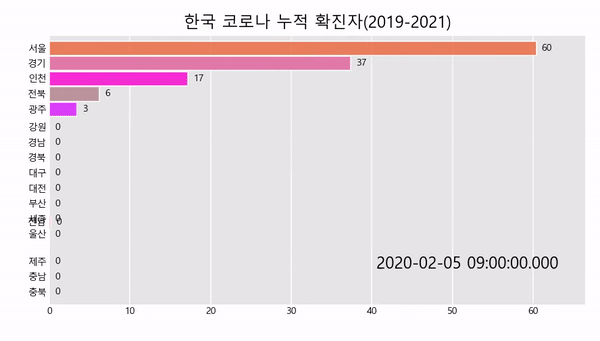

공공데이터 OPENAPI를 이용해 데이터를 가져오는 방법은 아래의 링크를 참고하여 주세요.
[python] 공공데이터 OPEN API의 xml 을 DataFrame으로 변환하기(feat. 코로나 확진자 수)
안녕하세요~! 오늘은 공공데이터 openAPI의 xml을 Pandas DataFrame으로 변환하여 보도록 하겠습니다. json에서 DataFrame으로의 변환은 여기를 클릭해서 확인해 주세요 :) step1. 데이터 활용신청하기 공공데
wonhwa.tistory.com
step1. 데이터 준비
저번 게시물을 통해 만든
전국 코로나 확진자 수(2020년도~2021년도 11월 3일까지) 데이터인 'corona_kr.csv' 파일을 불러와줍니다.
import pandas as pd
import bar_chart_race as bcr
#csv파일 불러오기(코로나 전국 확진자)
corona_csv=pd.read_csv('corona_kr.csv')
print(corona_csv.head(19))
이렇게 많은 컬럼 값에 각 값이 들어가있습니다.
각 컬럼의 의미는 아래와 같습니다.(공공데이터 포털에서 확인 가능합니다.)
각 컬럼 값 정보
SEQ : 게시글번호(국내 시도별 발생현황 고유값)
CREATE_DT: 등록일시분초
DEATH_CNT: 사망자 수
GUBUN: 시도명(한글)
GUBUN_CN: 시도명(중국어)
gubunEn: 시도명(영어)
INC_DEC: 전일대비 증감 수
ISOL_CLEAR_CNT: 격리 해제 수
QUR_RATE: 10만명당 발생률
STD_DAY: 기준일시
UPDATE_DT: 수정일시분초
DEF_CNT: 확진자 수
ISOL_ING_CNT: 격리중 환자수
OVER_FLOW_CNT: 해외유입 수
LOCAL_OCC_CNT: 지역발생 수
step2. 시각화를 위한 데이터 전처리하기
여기서 시도별 확진자 수 시각화를 하기 위해
확진자 수, 업데이트날짜, 시도명(영어) 컬럼 값만 남기고 나머지는 지워보겠습니다.
#필요한 데이터만 남기고 지우기
corona = corona_csv[['createDt','defCnt','gubunEn']] # 등록일시분초, 확진자 수, 시도명(영어)
print(corona.head(19))출력:

여기서 날짜 - 시도명 - 확진자 순으로 컬럼 순서를 바꿔 주도록 하겠습니다.
#열 순서 바꾸기 (등록일시, 시도명, 확진자 수 순)
corona = corona[['createDt','gubunEn','defCnt']]
print(corona.head(19))
위처럼 시간 - 이름 - 확진자 수 로 순서 배치가 잘 되었음을 확인할 수 있습니다.
다음으로, 시각화할때 관련없는 검역(Lazaretto)과 총합(Total)행을 지워주도록 하겠습니다.
gubunEn(시도 영어명)이 Lazaretto, Total 이 아닌 행만 남기는 조건을 달아 보도록 하겠습니다.
#필요없는 데이터 지우기(검역Lazaretto, 토탈Total)
condition = (corona.gubunEn != 'Lazaretto') & (corona.gubunEn !='Total')
corona = corona[condition]
print(corona.head(17))출력:

위 사진과 같이 잘 지워졌음을 확인할 수 있습니다.
이제 열값을 도시명으로 하고 값을 확진자 수로 피벗팅 해보겠습니다.
그리고 그 후 NaN값이 있는지 확인해 보도록 하겠습니다.
# 열값을 지역(gubunEn)으로, 값을 확진자 수(defCnt)로 하여 피봇팅하기
corona_df = corona.pivot_table(values = 'defCnt', index = ['createDt'], columns='gubunEn')
#nan값 있는지 확인 True이면 null값이 있음
print(pd.isnull(corona_df))출력:

중간중간 True가 있는 것을 보니 피벗후 데이터프레임에 NaN값이 있는 것을 확인 할 수 있습니다.
이 NaN값들을 모두 0으로 바꾸어주도록 하겠습니다.
# NaN값을 0으로 바꾸어 주기
corona_df.fillna(0,inplace=True)
print(corona_df.head())출력:

그럼 이렇게 0.0으로 대체되었음을 확인할 수 있습니다.
이제 전처리 마지막 단계입니다.
bar_chart_race로 시각화하기 위해 다음행을 그 전 행의 누적하여 값을 나타내 주도록 하겠습니다.
# 확진자 수 누적값으로 만들어주기
corona_df.iloc[:,0:-1] = corona_df.iloc[:,0:-1].cumsum()
print(corona_df.head())출력:

위 사진과 같이 누적값으로 변환이 되었습니다.
step3. bar_chart_race로 시각화하기
#bar_chart_race로 시각화하기
bcr.bar_chart_race(df = corona_df,
n_bars= 17,
sort='desc',
title='Corona in Korea',
filename='한국_코로나확진자.mp4')시도명이 총 17개이므로 n_bars를 17로, 정렬(sort)은 내림차순으로 하여 큰 숫자부터 앞에 나타나도록 하였습니다.
title(제목)을 설정해주고 , 파일을 mp4로 저장하기 위해 filename을 설정해 주었습니다.
이번 데이터는 양이 많기 때문에 그래프를 생성하는데 시간이 오래 걸립니다.
이점 참고해 주세요.
또는 step2의 데이터 전처리 과정에서 시간 행을 줄이고 시각화 하시길 바랍니다.
출력:
[한글버전]
전체 코드
import pandas as pd
import bar_chart_race as bcr
#csv파일 불러오기(코로나 전국 확진자)
corona_csv=pd.read_csv('corona_kr.csv')
#print(corona_csv.head(19))
## 각 컬럼 값 ## (포털 문서에서 꼭 확인하세요)
"""
SEQ : 게시글번호(국내 시도별 발생현황 고유값)
CREATE_DT: 등록일시분초
DEATH_CNT: 사망자 수
GUBUN: 시도명(한글)
GUBUN_CN: 시도명(중국어)
gubunEn: 시도명(영어)
INC_DEC: 전일대비 증감 수
ISOL_CLEAR_CNT: 격리 해제 수
QUR_RATE: 10만명당 발생률
STD_DAY: 기준일시
UPDATE_DT: 수정일시분초
DEF_CNT: 확진자 수
ISOL_ING_CNT: 격리중 환자수
OVER_FLOW_CNT: 해외유입 수
LOCAL_OCC_CNT: 지역발생 수
"""
#필요한 데이터만 남기고 지우기
corona = corona_csv[['createDt','defCnt','gubunEn']] # 등록일시분초, 확진자 수, 시도명(영어)
#print(corona.head(19))
#열 순서 바꾸기 (등록일시, 시도명, 확진자 수 순)
corona = corona[['createDt','gubunEn','defCnt']]
#print(corona.head(19))
#필요없는 데이터 지우기(검역Lazaretto, 토탈Total)
condition = (corona.gubunEn != 'Lazaretto') & (corona.gubunEn !='Total')
corona = corona[condition]
#print(corona.head(17))
# 열값을 지역(gubunEn)으로, 값을 확진자 수(defCnt)로 하여 피봇팅하기
corona_df = corona.pivot_table(values = 'defCnt', index = ['createDt'], columns='gubunEn')
#nan값 있는지 확인 True이면 null값이 있음
#print(pd.isnull(corona_df))
# NaN값을 0으로 바꾸어 주기
corona_df.fillna(0,inplace=True)
#print(corona_df.head())
# 확진자 수 누적값으로 만들어주기
corona_df.iloc[:,0:-1] = corona_df.iloc[:,0:-1].cumsum()
print(corona_df.head())
#bar_chart_race로 시각화하기
bcr.bar_chart_race(df = corona_df,
n_bars= 17,
sort='desc',
title='Corona in Korea',
filename='한국_코로나확진자.mp4')아래는 한글 버전입니다.
###한글버전###
import pandas as pd
import bar_chart_race as bcr
from matplotlib import font_manager,rc
# 한글 폰트 설정
font_location = 'C:/Windows/Fonts/MALGUNSL.TTF' #맑은고딕
font_name = font_manager.FontProperties(fname=font_location).get_name()
rc('font',family=font_name)
#csv파일 불러오기(코로나 전국 확진자)
corona_csv=pd.read_csv('corona_kr.csv')
#필요한 데이터만 남기고 지우기
corona = corona_csv[['createDt','defCnt','gubun']] # 등록일시분초, 확진자 수, 시도명(한글)
#열 순서 바꾸기 (등록일시, 시도명, 확진자 수 순)
corona = corona[['createDt','gubun','defCnt']]
#필요없는 데이터 지우기(검역Lazaretto, 합계Total)
condition = (corona.gubun != '검역') & (corona.gubun !='합계')
corona = corona[condition]
# 열값을 지역(gubun)으로, 값을 확진자 수(defCnt)로 하여 피봇팅하기
corona_df = corona.pivot_table(values = 'defCnt', index = ['createDt'], columns='gubun')
# NaN값을 0으로 바꾸어 주기
corona_df.fillna(0,inplace=True)
# 확진자 수 누적값으로 만들어주기
corona_df.iloc[:,0:-1] = corona_df.iloc[:,0:-1].cumsum()
#bar_chart_race로 시각화하기
bcr.bar_chart_race(df = corona_df,
shared_fontdict={'family':font_name},
n_bars= 17,
sort='desc',
title='한국 코로나 누적 확진자(2019-2021)',
filename='한국_코로나확진자_한글.mp4')코드 파일
마무리
저번 시각화에 이어 오늘은 공공데이터 OPEN API를 이용하여 수집한 데이터를 토대로 시각화를 해 보았습니다.
거의 2년치를 시각화하느라 시간이 꽤 걸렸는데요.
공공 데이터를 이용해 다른 분야도 위 게시글을 활용하여 시각화 해보시길 바랍니다 :)
질문은 댓글로 남겨주세요 ^ㅇ^
++ 22.07.05 한국어 버전 추가
'시각화(Visualization)' 카테고리의 다른 글
| [python] CCTV,가로등 위치를 folium을 사용하여 clustering 시각화하기 (4) | 2021.11.17 |
|---|---|
| [python] folium을 이용하여 CCTV 위치 시각화하기 (3) | 2021.11.15 |
| [python] 네이버 블로그 크롤링 결과로 WordCloud 시각화하기 (5) | 2021.11.10 |
| [python] bar-chart-race로 시각화하기 (feat. 축구) (2) | 2021.10.29 |
| [python] matplotlib을 이용하여 3D 막대 그래프 그리기 (0) | 2021.10.27 |