
[python] Naver 오픈API를 이용하여 원하는 검색어로 블로그 크롤링 하기(제목+본문)
오늘은 NAVER API를 이용하여 네이버 블로그 크롤링을 해 보겠습니다 ;)
NAVER OPEN API 신청하는 방법은 여기를 클릭해주세요ㅎㅎ
step1. 네이버 OPEN API를 이용하여 원하는 검색어로 관련 게시물 불러오기
신청한 네이버 OPEN API 아이디와 시크릿 코드를 이용하여 블로그 게시물을 불러와줍니다.
저는 검색어를 '상암 맛집' 으로, 출력 개수는 예시로 10개 받아와 보도록 하겠습니다.
import urllib.request
from selenium.common.exceptions import NoSuchElementException
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# 웹드라이버 설정
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option("useAutomationExtension", False)
# 정보입력
client_id = "*********************" # 발급받은 id 입력
client_secret = "*************" # 발급받은 secret 입력
quote = input("검색어를 입력해주세요.: ") #검색어 입력받기
encText = urllib.parse.quote(quote)
display_num = input("검색 출력결과 갯수를 적어주세요.(최대100, 숫자만 입력): ") #출력할 갯수 입력받기
url = "https://openapi.naver.com/v1/search/blog?query=" + encText +"&display="+display_num# json 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
#print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
body = response_body.decode('utf-8')
body[결과]

위를 보면 블로그 게시물에 대한 정보들이 나와 있습니다.
여기서 title (제목) 과 link(블로그 게시물 링크)를 추출하도록 하겠습니다.
여기서는 블로그의 대략적인 내용만 나오지 블로그 내용 전체가 나오지 않으므로
블로그 링크를 추출하여 각각의 블로그로 들어가 내용을 크롤링 하도록 해야 합니다.
step2. 게시글 제목 및 링크만 추출하기
위의 결괏값을 보면 "(큰따옴표)가 글 앞뒤로 붙어있는데 replace를 활용하여 지워주겠습니다.
# 불필요한 ""(큰따옴표)지워주기
body = body.replace('"','')그다음 "가 없어진 내용을 가지고 제목, 링크를 추출해 보도록 하겠습니다.
그 전에 네이버 블로그 링크만 받아오기 위해 body를 split으로 나누어 글 하나 당 리스트 요소 1개가 되도록 나누도록 하겠습니다. 그 후 list comprehension을 사용하여 naver가 들어간 글만 리스트에 남아있도록 해 줍니다.
#body를 나누기
list1 = body.split('\n\t\t{\n\t\t\t')
#naver블로그 글만 가져오기
list1 = [i for i in list1 if 'naver' in i]
list1[결과]

이렇게 naver블로그 글만 리스트에 담겼습니다.
제목은 title: 뒤, link: 앞에 위치하므로 re를 사용하여 제목만 추출하도록 하겠습니다.
각 링크는 link: 뒤, description 앞에 위치하여 있습니다.
for문을 이용하여 한번에 제목, 링크를 추출해 보도록 하겠습니다.
#블로그 제목, 링크 뽑기
import re
titles = []
links = []
for i in list1:
title = re.findall('"title":"(.*?)",\n\t\t\t"link"',i)
link = re.findall('"link":"(.*?)",\n\t\t\t"description"',i)
titles.append(title)
links.append(link)
titles = [r for i in titles for r in i]
links = [r for i in links for r in i]
print('<<제목 모음>>')
print(titles)
print('총 제목 수: ',len(titles),'개')#제목갯수확인
print('\n<<링크 모음>>')
print(links)
print('총 링크 수: ',len(links),'개')#링크갯수확인[결과]

위의 링크를 확인해 보면 보통의 url과는 다르게 '\\'(역 슬래쉬)가 많이 들어가 있음을 확인할 수 있습니다.
보통의 url링크를 가져오기 위해 링크 사이의 '\\'를 지워 다듬어진 링크를 가져오도록 하겠습니다.
# 링크를 다듬기 (필요없는 부분 제거 및 수정)
blog_links = []
for i in links:
a = i.replace('\\','')
b = a.replace('?Redirect=Log&logNo=','/')
# 다른 사이트 url이 남아있을 것을 대비해 한번 더 네이버만 남을 수 있게 걸러준다.
if 'naver.blog.com' in b:
blog_links.append(b)
print(blog_links)
print('생성된 링크 갯수:',len(blog_links),'개')[결과]

그러면 위와 같이 링크가 예쁘게 출력되었습니다.
step3. 게시글 본문 가져오기
다음으로 블로그 링크를 활용하여 각 페이지에 접근해 본문을 가져오도록 하겠습니다.
NAVER 블로그는 각 게시물에 들어가 보면 아래와 같이 iframe 안에 게시물 본문 글이 위치하여 있습니다.

때문에 Selenium을 이용하여 각 게시물의 iframe 접근 후 내용을 추출하는 방식으로 크롤링을 하여야 합니다.
Selenium을 이용할 때는 전용 drvier 가 있어야 합니다.
여기서는 크롬 드라이버를 이용하겠습니다.
여기를 클릭하여 현재 본인이 사용하고 있는 구글 버전에 맞는 드라이버를 다운받아주세요.
#본문 크롤링
import time
from selenium import webdriver
# 크롬 드라이버 설치
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.implicitly_wait(3)그다음으로 아까 다듬어진 링크에 접속하여 iframe 접근 후 본문의 내용을 크롤링하겠습니다.
본문은 iframe 안의 <div> class='se-main-container' 여기에 아래의 사진과 같이 들어있음을 확인할 수 있습니다.

그래서 find_element_by_css_selector를 사용해 본문 글을 가져와 contents 변수에 담아 줍니다.
그리고 가끔 예전 블로그 글을 가져오게 될 때가 있는데 그 때는 현재 블로그 html 구조와 달라
No Such Element Error가 날 수 있습니다. 이때 구 블로그 글도 잘 가져올 수 있도록
예외처리를 하여 내용 부분을 크롤링 해 줍니다.
#블로그 링크 하나씩 불러서 크롤링
contents = []
for i in blog_links:
#블로그 링크 하나씩 불러오기
driver.get(i)
time.sleep(1)
#블로그 안 본문이 있는 iframe에 접근하기
driver.switch_to.frame("mainFrame")
#본문 내용 크롤링하기
#본문 내용 크롤링하기
try:
a = driver.find_element(By.CSS_SELECTOR,'div.se-main-container').text
contents.append(a)
# NoSuchElement 오류시 예외처리(구버전 블로그에 적용)
except NoSuchElementException:
a = driver.find_element(By.CSS_SELECTOR,'div#content-area').text
contents.append(a)
#print(본문: \n', a)
driver.quit() #창닫기
print("<<본문 크롤링이 완료되었습니다.>>")[결과]

그러면 이렇게 모든 게시물의 본문 내용을 가져올 수 있습니다 ;-ㅇ
step4. 크롤링 내용들 DataFrame으로 만들기
마지막으로 아까 추출한 제목, 블로그 링크, 내용을 DataFrame으로 만들어 깔끔하게 정리해 보도록 하겠습니다.
#제목, 블로그링크, 본문내용 Dataframe으로 만들기
import pandas as pd
df = pd.DataFrame({'제목':titles, '링크':blog_links,'내용':contents})
#df 저장
df.to_csv('{}_블로그.csv'.format(quote),encoding='utf-8-sig',index=False)[결과]
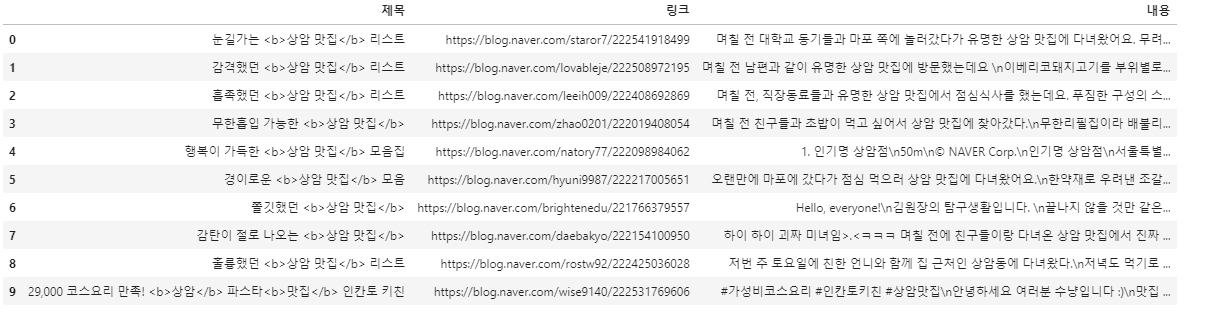
깔끔하게 df로 만들어졌습니다. ㅎㅎ
전체 코드
import urllib.request
from selenium.common.exceptions import NoSuchElementException
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# 웹드라이버 설정
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option("useAutomationExtension", False)
#정보입력
client_id = "********************" # 발급받은 id 입력
client_secret = "**********" # 발급받은 secret 입력
quote = input("검색어를 입력해주세요.: ") #검색어 입력받기
encText = urllib.parse.quote(quote)
display_num = input("검색 출력결과 갯수를 적어주세요.(최대100, 숫자만 입력): ") #출력할 갯수 입력받기
url = "https://openapi.naver.com/v1/search/blog?query=" + encText +"&display="+display_num# json 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
#print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
body = response_body.decode('utf-8')
print(body)
#body를 나누기
list1 = body.split('\n\t\t{\n\t\t\t')
#naver블로그 글만 가져오기
list1 = [i for i in list1 if 'naver' in i]
print(list1)
#블로그 제목, 링크 뽑기
import re
titles = []
links = []
for i in list1:
title = re.findall('"title":"(.*?)",\n\t\t\t"link"',i)
link = re.findall('"link":"(.*?)",\n\t\t\t"description"',i)
titles.append(title)
links.append(link)
titles = [r for i in titles for r in i]
links = [r for i in links for r in i]
print('<<제목 모음>>')
print(titles)
print('총 제목 수: ',len(titles),'개')#제목갯수확인
print('\n<<링크 모음>>')
print(links)
print('총 링크 수: ',len(links),'개')#링크갯수확인
# 링크를 다듬기 (필요없는 부분 제거 및 수정)
blog_links = []
for i in links:
a = i.replace('\\','')
b = a.replace('?Redirect=Log&logNo=','/')
# 다른 사이트 url이 남아있을 것을 대비해 한번 더 네이버만 남을 수 있게 걸러준다.
if 'naver.blog.com' in b:
blog_links.append(b)
print(blog_links)
print('생성된 링크 갯수:',len(blog_links),'개')
#본문 크롤링
import time
from selenium import webdriver
# 크롬 드라이버 설치
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.implicitly_wait(3)
#블로그 링크 하나씩 불러서 크롤링
contents = []
for i in blog_links:
#블로그 링크 하나씩 불러오기
driver.get(i)
time.sleep(1)
#블로그 안 본문이 있는 iframe에 접근하기
driver.switch_to.frame("mainFrame")
#본문 내용 크롤링하기
try:
a = driver.find_element(By.CSS_SELECTOR,'div.se-main-container').text
contents.append(a)
# NoSuchElement 오류시 예외처리(구버전 블로그에 적용)
except NoSuchElementException:
a = driver.find_element(By.CSS_SELECTOR,'div#content-area').text
contents.append(a)
#print(본문: \n', a)
driver.quit() #창닫기
print("<<본문 크롤링이 완료되었습니다.>>")
#제목 및 본문 txt에 저장
total_contents = titles + contents
text = open("blog_text.txt",'w',encoding='utf-8')
for i in total_contents:
text.write(i)
text.close()
#제목, 블로그링크, 본문내용 Dataframe으로 만들기
import pandas as pd
df = pd.DataFrame({'제목':titles, '링크':blog_links,'내용':contents})
print(df)
#df 저장
df.to_csv('{}_블로그.csv'.format(quote),encoding='utf-8-sig',index=False)
마무리
오늘은 네이버 API를 이용하여 블로그 제목 및 내용을 가져와봤는데요
이번 포스팅을 작성하는 데 꽤 시간이 걸렸는데 이렇게 깔끔하게 할 수 있어 정말 기쁘네요.ㅎㅎ
다음에는 크롤링 내용을 가지고 워드 클라우드를 만드는 실습을 해볼까 합니다.
포스팅에 대한 좋은 의견이 있다면 주저 말고 댓글로 추천해주세요!
--------------
+ 22.05.13 NoSuchElementException import 추가
+ 22.05.25 제목, 링크 추출 코드 수정
+ 22.06.03 네이버 블로그 글만 추출하는 코드 추가
+ 22.07.29 제목,링크 추출 코드 수정
+24.02.16 코드수정
'Crawling' 카테고리의 다른 글
| [python] 공공데이터 OPEN API의 xml 을 DataFrame으로 변환하기(feat. 코로나 확진자 수) (31) | 2021.11.04 |
|---|---|
| [python] 원하는 검색어로 네이버 뉴스 크롤링하기(2) (5) | 2021.10.22 |
| [Python] 공공데이터 포털의 OPEN API 사용 방법(2) (69) | 2021.10.14 |
| [python] 원하는 검색어로 네이버 뉴스 크롤링하기(1) (18) | 2021.10.14 |
| [python] Naver 오픈API를 이용하여 크롤링 하기(뉴스/블로그/카페) (8) | 2021.10.05 |
댓글