안녕하세요!
데이터 분석을 하다보면
특히 folium으로 위치를 시각화 할 때는 숫자로 된 위경도 값이 필요한데
데이터 파일 자체에 주소만 나와있고 위경도 값이 누락되어 있는 경우가 발생합니다.
그 때 위경도 값을 구하는 방법을 알아보도록 하겠습니다ㅎㅎ
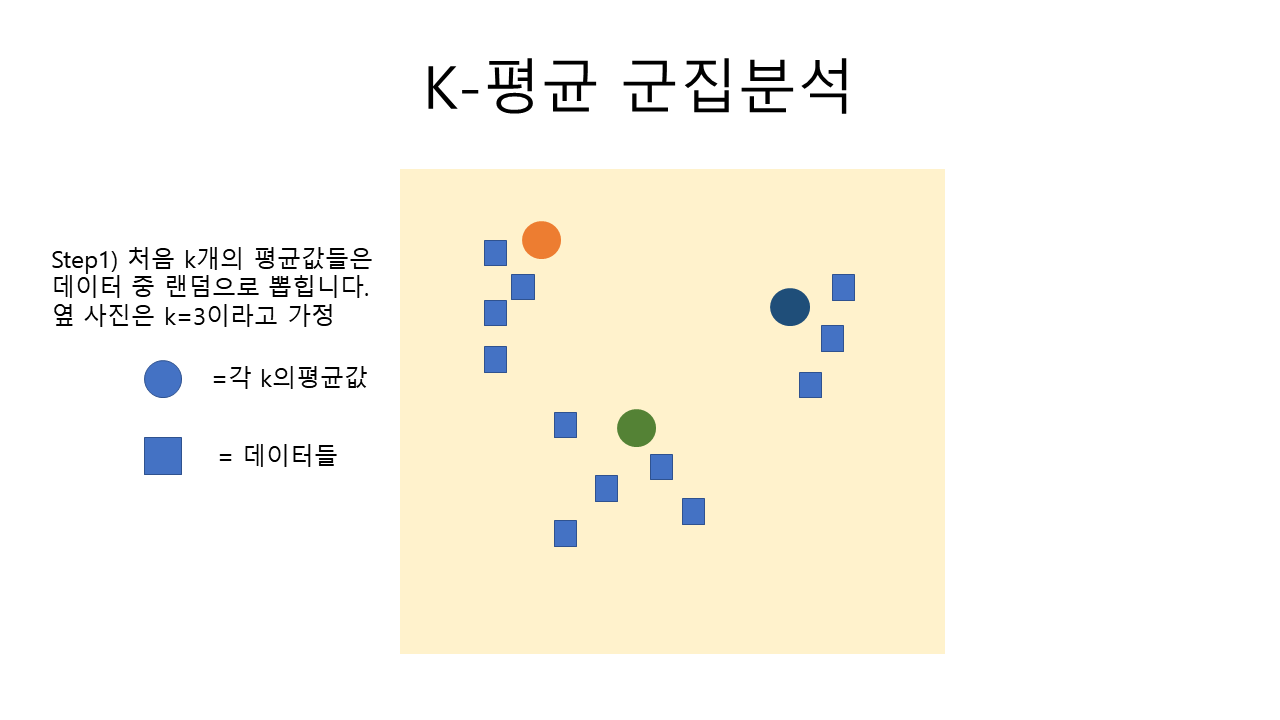
step1. 데이터 준비
오늘 예제로 사용할 데이터는 공공데이터의 인천 중구 커피숍 파일입니다.
아래의 링크에서 csv파일을 다운받아 주세요:)
다른 파일이 있으시다면 그 파일을 사용하셔도 무방합니다.
https://www.data.go.kr/data/15086876/fileData.do
인천광역시 중구_카페 및 커피숍 현황_20210805
인천광역시 중구 관내에 위치한 카페 및 커피숍 현황에 대한 데이터 입니다.<br/><br/>파일명 인천광역시_중구_카페 및 커피숍 현황<br/>파일내용 사업장명, 소재지지번주소, 도로명주소 등<br/>
www.data.go.kr
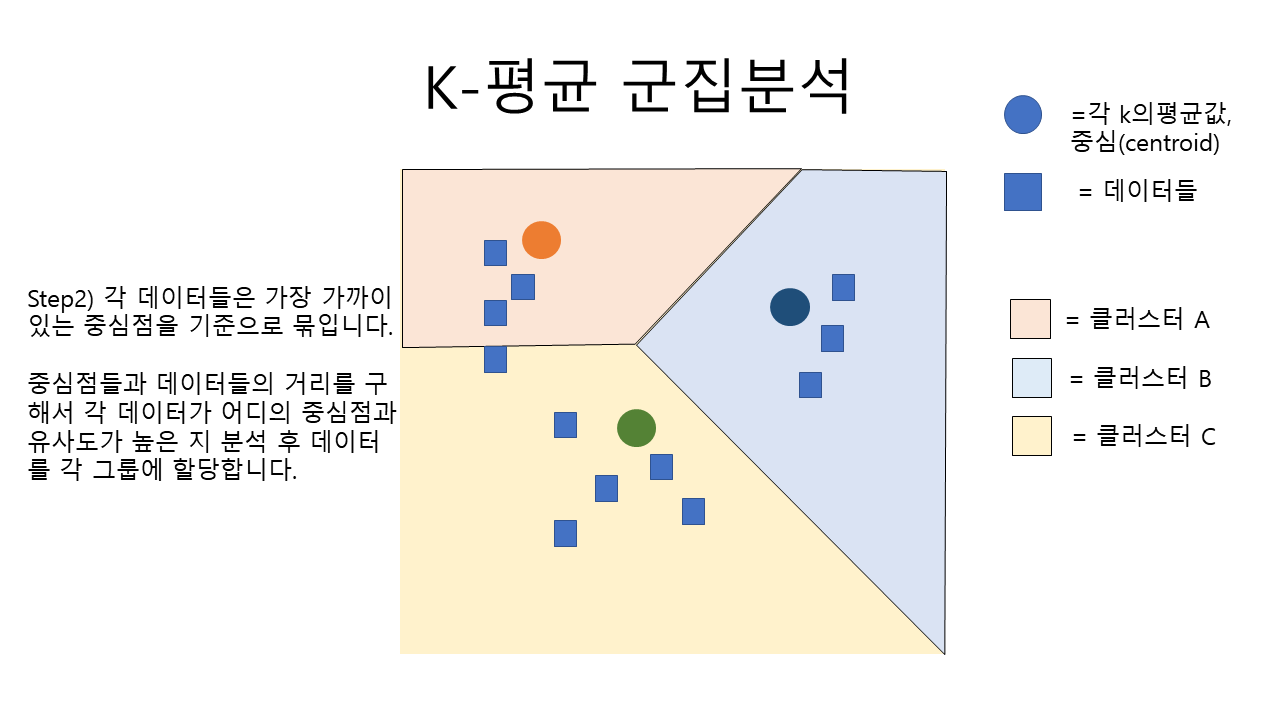
step2. 데이터 확인
# csv파일 불러오기
csv = pd.read_csv('incheon_coffeeshop_20210805.csv',encoding='cp949')
print(csv.head())출력:

전에 다운받은 데이터는 위와 같은 정보를 포함하고 있음을 알 수 있습니다.
위경도 값을 찾기 전에 위의 데이터에서 도로명 주소만 따로 추출해 보도록 하겠습니다.
# 데이터프레임 주소값 추출
address= csv['소재지도로명주소']
print(address.head())출력:

주소를 보면 맨 뒤 에 '1층'과 같은 상세주소도 포함됨을 알 수 있습니다.
위경도 값에는 층수가 포함이 되지 않고, 주소를 위경도 변환시 오류가 날 수 있어 필요한 주소만 남겨주고 나머지는 지워주는 작업을 진행하겠습니다.
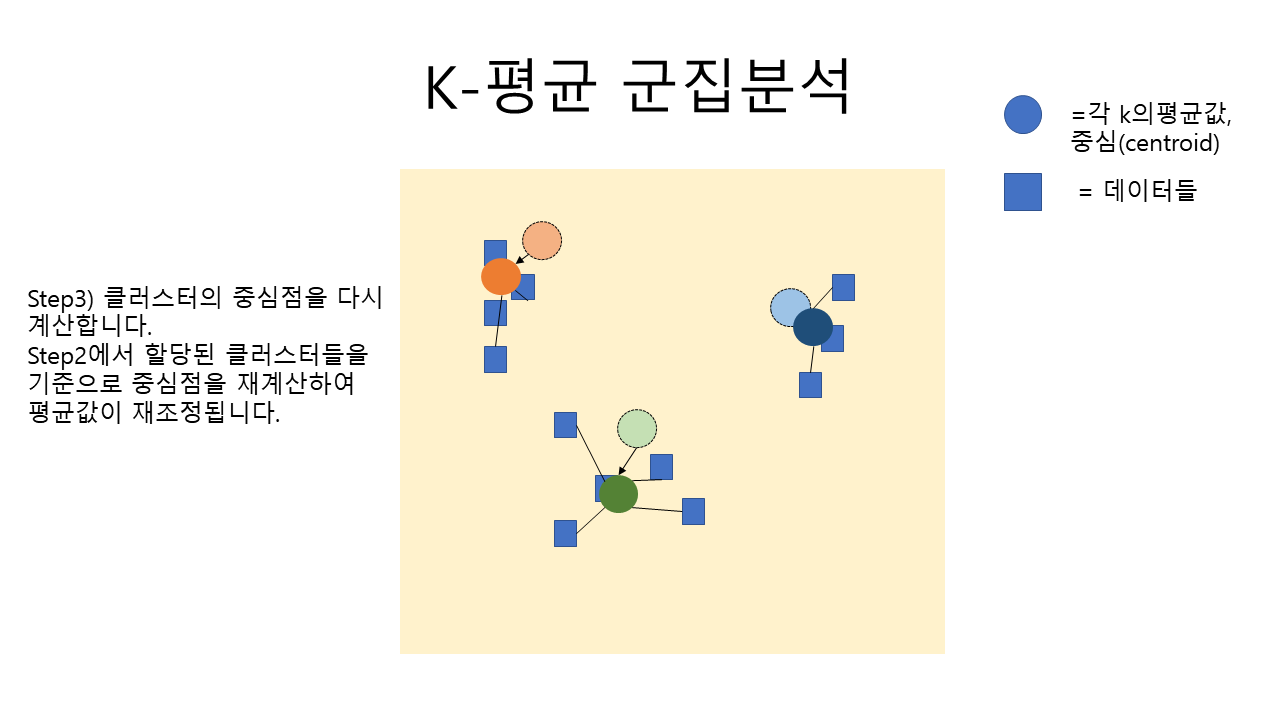
step3. 필요한 주소만 남겨놓기
# 주소 데이터 깔끔하게 다듬기
for i in range(len(address)):
a = address[i].split(' ')
address[i] = " ".join(a[0:4])
print(address)출력:

사진과 같이 필요한 정보만 담아졌음을 확인할 수 있습니다.
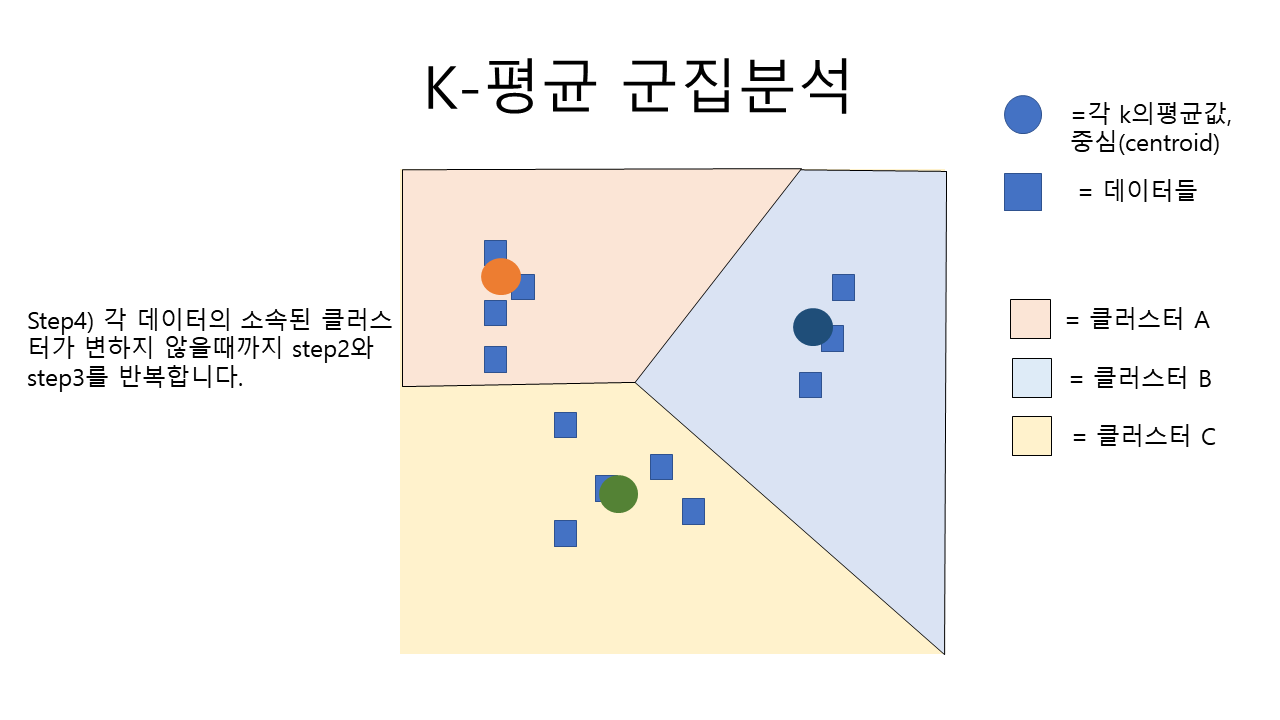
step4. 위경도 변환하기
그럼 이제 위 주소를 가지고 위경도 값으로 바꿔주겠습니다.
이 작업을 진행하려면 먼저 geopy라는 라이브러리를 import 해주어야 하는데요,
아래와 같이 명령창에 pip 명령어를입력해서 다운받아 주세요.
pip install geopy
그 후 아래와 같이 함수를 작성해줍니다.
####### 도로명주소 위도 경도 값으로 바꿔주기 ########
from geopy.geocoders import Nominatim
geo_local = Nominatim(user_agent='South Korea')
# 위도, 경도 반환하는 함수
def geocoding(address):
try:
geo = geo_local.geocode(address)
x_y = [geo.latitude, geo.longitude]
return x_y
except:
return [0,0]위의 함수는 geocoding함수 안에 주소를 넣어주면 그 주소에 맞는 위도, 경도를
리스트로 만들어 [위도, 경도]로 반환해주는 함수입니다.
주소가 올바르지 않은 형식인 경우에는 [0,0]을 반환합니다.
이제 이 함수를 이용하여 커피숍의 위경도 값을 추출해 주도록 하겠습니다.
#####주소를 위,경도 값으로 변환하기 #####
latitude = []
longitude =[]
for i in address:
latitude.append(geocoding(i)[0])
longitude.append(geocoding(i)[1])그 후 데이터프레임으로 만들어 한눈에 보이도록 해 줍니다.
#####Dataframe만들기######
address_df = pd.DataFrame({'카페이름': csv['사업장명'],'상세주소':csv['소재지도로명주소'],'주소':address,'위도':latitude,'경도':longitude})
#df저장
address_df.to_csv('jungu_incheon_coffeeshop.csv')
이렇게 주소값만으로 위경도 값을 찾을 수 있습니다 :)
전체 코드
import pandas as pd
# csv파일 불러오기
csv = pd.read_csv('incheon_coffeeshop_20210805.csv',encoding='cp949')
print(csv.head())
# 데이터프레임 주소값 추출
address= csv['소재지도로명주소']
print(address.head())
# 주소 데이터 깔끔하게 다듬기
for i in range(len(address)):
a = address[i].split(' ')
address[i] = " ".join(a[0:4])
print(address)
####### 도로명주소 위도 경도 값으로 바꿔주기 ########
from geopy.geocoders import Nominatim
geo_local = Nominatim(user_agent='South Korea')
# 위도, 경도 반환하는 함수
def geocoding(address):
try:
geo = geo_local.geocode(address)
x_y = [geo.latitude, geo.longitude]
return x_y
except:
return [0,0]
#####주소를 위,경도 값으로 변환하기 #####
latitude = []
longitude =[]
for i in address:
latitude.append(geocoding(i)[0])
longitude.append(geocoding(i)[1])
#####Dataframe만들기######
address_df = pd.DataFrame({'카페이름': csv['사업장명'],'상세주소':csv['소재지도로명주소'],'주소':address,'위도':latitude,'경도':longitude})
#df저장
address_df.to_csv('jungu_incheon_coffeeshop.csv')
마무리
오늘은 주소정보만 있을때 위치 정보로 바꾸어 주는 방법을 알아보았는데요
필요시 활용해 주시길 바랍니다. ㅎㅎ
그리고 코드 관련 질문이나 기타 의견이 있다면 댓글로 남겨주세요 :)
++ 22/08/04 예외처리 추가
++ 관련한 최신 포스팅은 아래에서 확인 가능합니다.
https://wonhwa1.blogspot.com/2022/10/python-geopy.html
[python] geopy를 사용하여 주소를 위,경도 값으로 바꾸기 & 위,경도 값을 주소로 바꾸기
geopy란? geopy는 파이썬 라이브러리로, 주소를 위,경도 숫자 값으로 바꿔 주거나(지오코딩), 반대로 위,경도 값을 사람이 읽을 수 있는 주소로 바꿔줍니다. (이를 역 지오코딩이라 합니다.) 예를
wonhwa1.blogspot.com
'Python' 카테고리의 다른 글
| [python/DB] python으로 SQL문 작성하여 DB 다루기(sqlite3) (0) | 2022.02.09 |
|---|---|
| [python/GUI] tkinter 로 GUI 만들기(기초예제, 단위 변환기 만들기) (9) | 2022.02.08 |
| [python] pandas(판다스) - groupby, pivot_table, melt (0) | 2021.11.29 |
| [python] Visual Studio Code를 이용하여 파이썬 코딩하기(+ 아나콘다) (5) | 2021.11.04 |
| [python] pandas 데이터 프레임 특정 열값의 데이터타입 변경하기 (0) | 2021.10.27 |