Pandas는 데이터 분석을 할 때 필수적으로 사용하는 파이썬 라이브러리입니다.
오늘은 유용하게 쓰일 수 있는 판다스의 메소드 몇 가지를 간단히 알아보도록 하겠습니다.
Groupby 그룹바이
pandas.groupby() 메서드는 그룹 연산을 도와주는 메서드입니다.
데이터를 집계하면 전체 데이터를 더 분석하기 쉽고 한눈에 파악하는데 용이하기 때문에 groupby는 정말 유용합니다.
그룹바이를 이용하면 평균, 합, 표준편차 등등 여러 값을 구할 수 있습니다.
오늘은 저번에 bar_chart_race에서 사용한 코로나 확진자 데이터를 이용하여 집계해 보도록 하겠습니다.
데이터셋
위의 데이터를 다운받아 주세요:)
그 후 파일을 열어 어떤 데이터를 가지고 있는지 확인해 보도록 하겠습니다.
####### Pandas Groupby #######
import pandas as pd
#데이터셋 준비
df = pd.read_csv('corona_kr.csv')
print(df.head())출력:

이렇게 업데이트된 날짜, 사망인원, 확진자, 지역명(한국어) 등등 여러 정보가 나와 있습니다.
이 데이터는 2020년부터~2021년 11월 초반까지의 데이터입니다.
지역별 총 코로나 확진자 수를 groupby sum을 이용해 구해 보도록 하겠습니다.
사용방법은 아래와 같습니다.
df.groupby('합계를 구할 기준컬럼 이름').합계할 값 컬럼이름.하고싶은 그룹연산()
##### groupby sum #####
## 지역별 총 코로나 확진자 수 구하기##
corona_by_region= df.groupby('gubun').defCnt.sum()
print(corona_by_region)출력:

이렇게 지역별 합이 만들어졌습니다.
이번에는 기간 내 코로나 확진자 지역 평균을 mean()을 사용하여 구해보도록 하겠습니다.
##### groupby mean #####
##지역별 평균 확진자 수 ##
means_by_region = df.groupby('gubun').defCnt.mean()
print(means_by_region)출력:
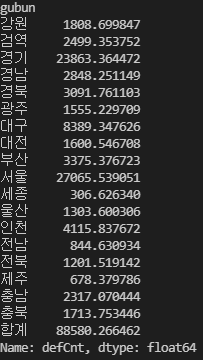
이렇게 하루 평균 지역 확진자 발생 인원을 구했습니다.
마지막으로는 describe를 알아보도록 하겠습니다.
describe는 전체적인 집계 정보를 보여줍니다.
위에서 구한 합계, 평균뿐만 아니라 표준편차, 최솟값, 최댓값, 4 분위 값 등등을 확인할 수 있습니다.
##### groupby describe #####
#코로나 확진자에 대한 전체적인 정보 반환#
print(df.groupby('gubun').defCnt.describe())출력:
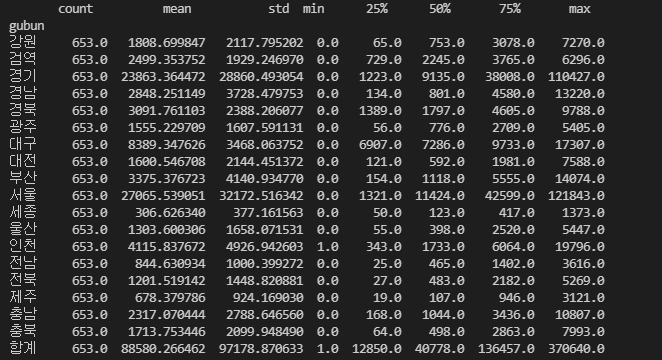
이렇게 데이터에 대한 전체적인 정보를 describe를 사용하여 확인 할 수 있습니다 :)
pivot_table 피벗 테이블
pivot_table 메서드는 데이터 프레임의 행과 열의 위치를 내가 원하는 대로 배치할 수 있도록 도와줍니다.
코로나 데이터에서는 지역 컬럼이 따로 있고 하루마다 확진자 수가 갱신이 됩니다.
지역별 확진자 수를 한눈에 보기 위해 (1)열 수를 정리해주고,
피벗 테이블을 사용하여 (2)지역열에 있는 행값들을 열로 위치하고,
각 지역 (3)열 값의 값으로는 확진자 수(defCnt)를 넣어 주도록 하겠습니다.
#### pandas pivot table ####
#필요한 정보만 df2에 담기
df2 = df.iloc[:,1:5]
print(df2)출력:

corona_pivotTable = df2.pivot_table(
index=['createDt','deathCnt'],
columns='gubun',
values='defCnt' )
print(corona_pivotTable)출력:
[원본 데이터]
[피벗 후 데이터]

위와 같이 아까는 행에 있던 지역 명들이 열값으로 옮겨졌음을 확인할 수 있습니다.
pivot_table 메서드에서 3개의 인자를 사용하여 데이터프레임을 피봇 해주었는데요,
index = 그대로 유지할 열 이름 입력
columns = 피벗할 열 이름 입력
values = 피벗할 열의 값이 될 열 이름 입력
위와 같이 사용하여 입력하면 됩니다:)
melt
마지막으로 알아볼 메서드는 melt인데요,
melt는 긴 열값을 가지고 있는 데이터를 정리할 때 유용합니다.
예를 들어 서울시 상권분석서비스 소득소비 데이터를 확인해보면,
(아래의 링크에서 데이터를 다운받아 주세요.)
http://data.seoul.go.kr/dataList/OA-15571/S/1/datasetView.do
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
##데이터 셋 불러오기##
seoul=pd.read_csv('서울시_우리마을가게 상권분석서비스(상권배후지-소득소비).csv',encoding='cp949')
print(seoul)출력:

위와 같이 의류지출총금액, 생활용품지출총금액, 의료지출금액 등등 열이 길게 늘어져 있는것을 확인할 수 있습니다.
이 데이터를 melt를 사용해서 지출 종류별로 열을 행으로 만들어 주어 데이터를 만들어 보도록 하겠습니다.
행으로 합쳐질 새로운 열의 이름을 '지출 종류'라 이름짓고, 원래 데이터에 있던 지출금액을 '금액'으로 열이름을 지정하겠습니다.
#### pandas melt ####
seoul_melt = pd.melt(seoul,id_vars=['기준 년 코드','기준_분기_코드','상권_구분_코드','상권_구분_코드_명',
'상권_코드','상권_코드_명','월_평균_소득_금액'
, '소득_구간_코드','지출_총금액']
, var_name='지출종류',value_name='금액')
# 변경된 부분 한눈에 확인할 수 있도록 앞에 부분 자르기
a = seoul_melt.iloc[:,8:]
print(a)출력:

위와 같이 아까는 열이었던 식료품, 유흥, 의료 지출 총 금액이 하나의 열의 행값으로 합쳐지고 그 값도 옆에 '금액' 열로 정리되었음을 확인할 수 있습니다.
melt 메서드 인자는 아래와 같이 사용할 수 있습니다.
id_vars = 그대로 유지할 열 이름, 2개이상 입력 시 []로 묶어 입력하기
value_vars = 행으로 바꿀 열 이름
var_name = value_vars로 바꿀 열의 새로운 이름 만들기
value_name = var_name으로 바꾼 열의 원래 데이터값의 새로운 열 이름
전체 코드
####### Pandas Groupby #######
import pandas as pd
#데이터셋 준비
df = pd.read_csv('corona_kr.csv')
print(df.head())
##### groupby sum #####
## 지역별 총 코로나 확진자 수 구하기##
corona_by_region= df.groupby('gubun').defCnt.sum()
print(corona_by_region)
##### groupby mean #####
##지역별 평균 확진자 수 ##
means_by_region = df.groupby('gubun').defCnt.mean()
print(means_by_region)
##### groupby describe #####
#코로나 확진자에 대한 전체적인 정보 반환#
print(df.groupby('gubun').defCnt.describe())
#### pandas pivot table ####
df2 = df.iloc[:,1:5]
print(df2)
corona_pivotTable = df2.pivot_table(
index=['createDt','deathCnt'],
columns='gubun',
values='defCnt' )
print(corona_pivotTable)
#### pandas melt ####
##데이터 셋 불러오기##
seoul=pd.read_csv('서울시_우리마을가게 상권분석서비스(상권배후지-소득소비).csv',encoding='cp949')
print(seoul)
seoul_melt = pd.melt(seoul,id_vars=['기준 년 코드','기준_분기_코드','상권_구분_코드','상권_구분_코드_명',
'상권_코드','상권_코드_명','월_평균_소득_금액'
, '소득_구간_코드','지출_총금액']
, var_name='지출종류',value_name='금액')
a = seoul_melt.iloc[:,8:]
print(a)
코드 파일
참고 자료
책 「데이터 분석을 위한 판다스 입문」 - 이지스퍼블리싱
마무리
오늘은 데이터 전처리 시 유용하게 사용가능한 메서드 3개를 알아보았습니다ㅎㅎ
알고싶은 다른 pandas 기능이 있으시다면 댓글로 남겨주세요 (o'◡'o)
'Python' 카테고리의 다른 글
| [python/GUI] tkinter 로 GUI 만들기(기초예제, 단위 변환기 만들기) (9) | 2022.02.08 |
|---|---|
| [python] 주소값만 있을 때 위경도 찾는 방법 (10) | 2021.12.08 |
| [python] Visual Studio Code를 이용하여 파이썬 코딩하기(+ 아나콘다) (5) | 2021.11.04 |
| [python] pandas 데이터 프레임 특정 열값의 데이터타입 변경하기 (0) | 2021.10.27 |
| [python] 두 수를 입력받아 동적 변수를 이용하여 각각의 약수 list 출력하기 (2) | 2021.10.26 |