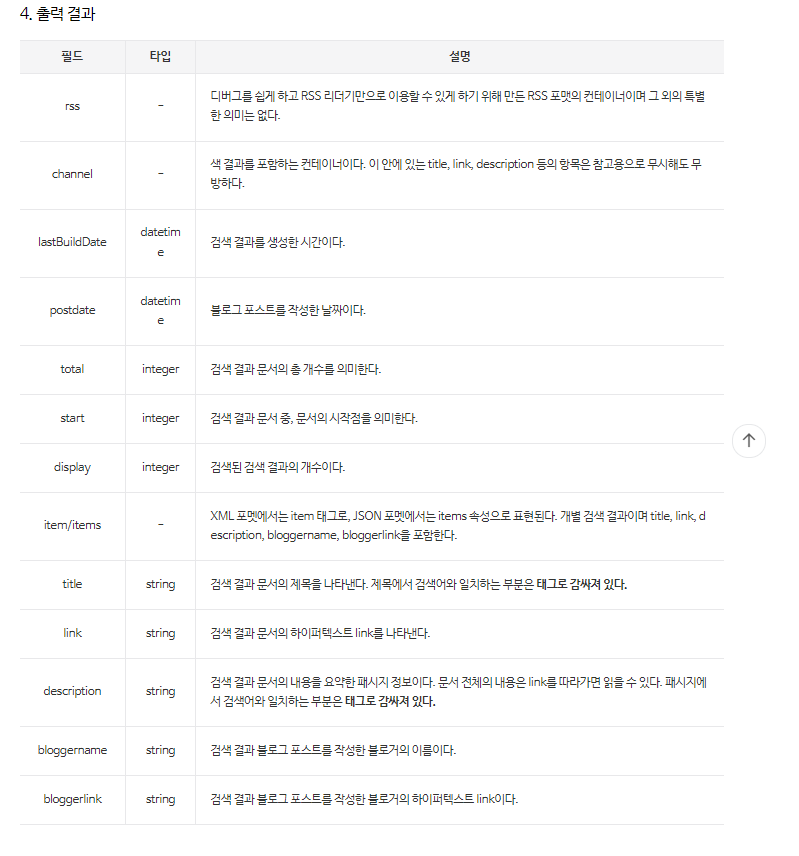
최근 두 수의 최대공약수를 어떻게 동적변수를 사용하여 list로 반환하는지에 관련한 문의가 들어와
꽤 오랜시간 고민해 보았다.
고민한 결과를 아래의 코드로 정리하여 공유하도록 하겠다.
동적변수로는 전역변수인 global()을 사용하였다.
하지만 보통 동적변수를 이용하여 변수를 생성하면 변수 관리가 힘들다는 단점이 있다.
변수가 자동생성되기 때문에 구문에 따라 어떤 변수가 어떤 값을 가지고 있는지 잘 기억해 두어야 한다.
그래서 각 상황에 맞게 적절히 사용하길 바란다.
코드
# 두 수를 입력받는 리스트 생성하기
input_list = list(map(int,input().split()))
#for 문을 사용하여 입력 받은 두 수 각각의 약수 구하기
for i in input_list:
a = globals()['num_{}'.format(i)]= list()
for j in range(i+1):
try:
if i/j - i//j ==0:
a.append(j)
except:
pass
print('num_{}: '.format(i),a) #입력받은 약수 출력
###실제 변수 리스트는 num_입력숫자1, num_입력숫자2 라는 이름의 변수에 저장되어있음을 유의##
오늘은 저번에 올린 네이버 뉴스 크롤링(1)에서 한 단계 업그레이드된 뉴스 크롤러를 공유하려 합니다 :)
1편에서는 뉴스 1페이지만 크롤링을 할 수 있었는데요
2편에서는 여러 페이지를 크롤링 할 수 있는 코드를 구현하여 보았습니다!
반복적인 작업이 있는 부분을 함수로 만들고
그 함수의 객체를 만들어 구현하여 기사 제목, 본문을 가지고 올 수 있는 크롤러를 만들었습니다.
오늘의 포스팅은 코드 위주이니 코드가 왜 이렇게 나왔는지 자세한 설명이 필요하시다면 (1) 편을 확인해 주세요 :-)
step1. 크롤링 시 필요한 라이브러리 불러오기
#크롤링시 필요한 라이브러리 불러오기
from bs4 import BeautifulSoup
import requests
step 2. 반복적인 작업 함수화하기
반복적인 작업들을 def를 이용해 함수를 만들어 보겠습니다.
(1) 입력받은 페이지 url 형식에 맞추어 숫자를 바꿔주는 함수
# 페이지 url 형식에 맞게 바꾸어 주는 함수 만들기
#입력된 수를 1, 11, 21, 31 ...만들어 주는 함수
def makePgNum(num):
if num == 1:
return num
elif num == 0:
return num+1
else:
return num+9*(num-1)
(2) Naver news url 생성하는 함수
# 크롤링할 url 생성하는 함수 만들기(검색어, 크롤링 시작 페이지, 크롤링 종료 페이지)
def makeUrl(search,start_pg,end_pg):
if start_pg == end_pg:
start_page = makePgNum(start_pg)
url = "https://search.naver.com/search.naver?where=news&sm=tab_pge&query=" + search + "&start=" + str(start_page)
print("생성url: ",url)
return url
else:
urls= []
for i in range(start_pg,end_pg+1):
page = makePgNum(i)
url = "https://search.naver.com/search.naver?where=news&sm=tab_pge&query=" + search + "&start=" + str(page)
urls.append(url)
print("생성url: ",urls)
return urls
(3) html에서 원하는 속성 값 추출해주는 함수
# html에서 원하는 속성 추출하는 함수 만들기 (기사, 추출하려는 속성값)
def news_attrs_crawler(articles,attrs):
attrs_content=[]
for i in articles:
attrs_content.append(i.attrs[attrs])
return attrs_content
(4) 뉴스 기사 내용 크롤링하는 함수
#뉴스기사 내용 크롤링하는 함수 만들기(각 뉴스의 url)
def news_contents_crawler(news_url):
contents=[]
for i in news_url:
#각 기사 html get하기
news = requests.get(i)
news_html = BeautifulSoup(news.text,"html.parser")
#기사 내용 가져오기 (p태그의 내용 모두 가져오기)
contents.append(news_html.find_all('p'))
return contents
(5) 뉴스기사 크롤러(main) 함수
#html생성해서 기사크롤링하는 함수 만들기(제목,url): 3개의 값을 반환함(제목, 링크, 내용)
def articles_crawler(url):
#html 불러오기
original_html = requests.get(i)
html = BeautifulSoup(original_html.text, "html.parser")
# 검색결과
articles = html.select("div.group_news > ul.list_news > li div.news_area > a")
title = news_attrs_crawler(articles,'title')
url = news_attrs_crawler(articles,'href')
content = news_contents_crawler(url)
return title, url, content #3개의 값을 반환
step3. 함수를 이용하여 뉴스 크롤링 하기
#뉴스크롤링 시작
#검색어 입력
search = input("검색할 키워드를 입력해주세요:")
#검색 시작할 페이지 입력
page = int(input("\n크롤링할 시작 페이지를 입력해주세요. ex)1(숫자만입력):")) # ex)1 =1페이지,2=2페이지...
print("\n크롤링할 시작 페이지: ",page,"페이지")
#검색 종료할 페이지 입력
page2 = int(input("\n크롤링할 종료 페이지를 입력해주세요. ex)1(숫자만입력):")) # ex)1 =1페이지,2=2페이지...
print("\n크롤링할 종료 페이지: ",page2,"페이지")
# naver url 생성
url = makeUrl(search,page,page2)
#뉴스 크롤러 실행
news_titles = []
news_url =[]
news_contents =[]
for i in url:
title, url,content = articles_crawler(url)
news_titles.append(title)
news_url.append(url)
news_contents.append(content)
print("검색된 기사 갯수: 총 ",(page2+1-page)*10,'개')
print("\n[뉴스 제목]")
print(news_titles)
print("\n[뉴스 링크]")
print(news_url)
print("\n[뉴스 내용]")
print(news_contents)
[결과]
중략...
중략...
중략.....
이렇게 각각 뉴스 제목, 링크, 내용이 각각 출력됨을 확인 가능합니다 ㅎㅎ
크롤링할 페이지가 많을수록 시간이 오래 걸린 다는 점 참고해주세요 :)
step4. 데이터 프레임으로 만들기
이제 이 데이터들을 데이터 프레임으로 만들어 보도록 하겠습니다!
데이터 프레임으로 만들기 전에 내용을 보니 리스트가 [[]] 이런 식으로 중첩으로 되어서 저장되어 있기 때문에
한 개의 기사의 한 개의 제목, 링크, 내용을 할당하기 위해 for문을 사용하여 1차원리스트로 변경해 주겠습니다.
makeList라는 함수를 만들어 간편하게 변경해 주도록 하겠습니다.
###데이터 프레임으로 만들기###
import pandas as pd
#제목, 링크, 내용 1차원 리스트로 꺼내는 함수 생성
def makeList(newlist, content):
for i in content:
for j in i:
newlist.append(j)
return newlist
#제목, 링크, 내용 담을 리스트 생성
news_titles_1, news_url_1, news_contents_1 = [],[],[]
#1차원 리스트로 만들기(내용 제외)
makeList(news_titles_1,news_titles)
makeList(news_url_1,news_url)
makeList(news_contents_1,news_contents)
#데이터 프레임 만들기
news_df = pd.DataFrame({'title':news_titles_1,'link':news_url_1,'content':news_contents_1})
news_df
출력:
이런 식으로 데이터 프레임이 만들어졌습니다.
중간에 내용이 빈 칸은 사이트가 iframe으로 되어 있거나 할 것 같네요.
내용도 다 채우고 싶다면 한 사이트의 기사들만 추출하는 것이 깔끔합니다.
때문에 나는 더 깔끔하게 기사 내용을 추출하고 싶다! 하시는 분들은
1편의 내용을 참고하여 본인이 크롤링 하고 싶은 사이트만 전문으로 크롤링하는 코드를 만들어도 좋을 것 같습니다 .
전체 코드
#크롤링시 필요한 라이브러리 불러오기
from bs4 import BeautifulSoup
import requests
# 페이지 url 형식에 맞게 바꾸어 주는 함수 만들기
#입력된 수를 1, 11, 21, 31 ...만들어 주는 함수
def makePgNum(num):
if num == 1:
return num
elif num == 0:
return num+1
else:
return num+9*(num-1)
# 크롤링할 url 생성하는 함수 만들기(검색어, 크롤링 시작 페이지, 크롤링 종료 페이지)
def makeUrl(search,start_pg,end_pg):
if start_pg == end_pg:
start_page = makePgNum(start_pg)
url = "https://search.naver.com/search.naver?where=news&sm=tab_pge&query=" + search + "&start=" + str(start_page)
print("생성url: ",url)
return url
else:
urls= []
for i in range(start_pg,end_pg+1):
page = makePgNum(i)
url = "https://search.naver.com/search.naver?where=news&sm=tab_pge&query=" + search + "&start=" + str(page)
urls.append(url)
print("생성url: ",urls)
return urls
# html에서 원하는 속성 추출하는 함수 만들기 (기사, 추출하려는 속성값)
def news_attrs_crawler(articles,attrs):
attrs_content=[]
for i in articles:
attrs_content.append(i.attrs[attrs])
return attrs_content
#뉴스기사 내용 크롤링하는 함수 만들기(각 뉴스의 url)
def news_contents_crawler(news_url):
contents=[]
for i in news_url:
#각 기사 html get하기
news = requests.get(i)
news_html = BeautifulSoup(news.text,"html.parser")
#기사 내용 가져오기 (p태그의 내용 모두 가져오기)
contents.append(news_html.find_all('p'))
return contents
#html생성해서 기사크롤링하는 함수 만들기(제목,url): 3개의 값을 반환함(제목, 링크, 내용)
def articles_crawler(url):
#html 불러오기
original_html = requests.get(i)
html = BeautifulSoup(original_html.text, "html.parser")
# 검색결과
articles = html.select("div.group_news > ul.list_news > li div.news_area > a")
title = news_attrs_crawler(articles,'title')
url = news_attrs_crawler(articles,'href')
content = news_contents_crawler(url)
return title, url, content #3개의 값을 반환
#####뉴스크롤링 시작#####
#검색어 입력
search = input("검색할 키워드를 입력해주세요:")
#검색 시작할 페이지 입력
page = int(input("\n크롤링할 시작 페이지를 입력해주세요. ex)1(숫자만입력):")) # ex)1 =1페이지,2=2페이지...
print("\n크롤링할 시작 페이지: ",page,"페이지")
#검색 종료할 페이지 입력
page2 = int(input("\n크롤링할 종료 페이지를 입력해주세요. ex)1(숫자만입력):")) # ex)1 =1페이지,2=2페이지...
print("\n크롤링할 종료 페이지: ",page2,"페이지")
# naver url 생성
url = makeUrl(search,page,page2)
#뉴스 크롤러 실행
news_titles = []
news_url =[]
news_contents =[]
for i in url:
title, url,content = articles_crawler(url)
news_titles.append(title)
news_url.append(url)
news_contents.append(content)
print("검색된 기사 갯수: 총 ",(page2+1-page)*10,'개')
print("\n[뉴스 제목]")
print(news_titles)
print("\n[뉴스 링크]")
print(news_url)
print("\n[뉴스 내용]")
print(news_contents)
###데이터 프레임으로 만들기###
import pandas as pd
#제목, 링크, 내용 1차원 리스트로 꺼내는 함수 생성
def makeList(newlist, content):
for i in content:
for j in i:
newlist.append(j)
return newlist
#제목, 링크, 내용 담을 리스트 생성
news_titles_1, news_url_1, news_contents_1 = [],[],[]
#1차원 리스트로 만들기(내용 제외)
makeList(news_titles_1,news_titles)
makeList(news_url_1,news_url)
makeList(news_contents_1,news_contents)
#데이터 프레임 만들기
news_df = pd.DataFrame({'title':news_titles_1,'link':news_url_1,'content':news_contents_1})
news_df
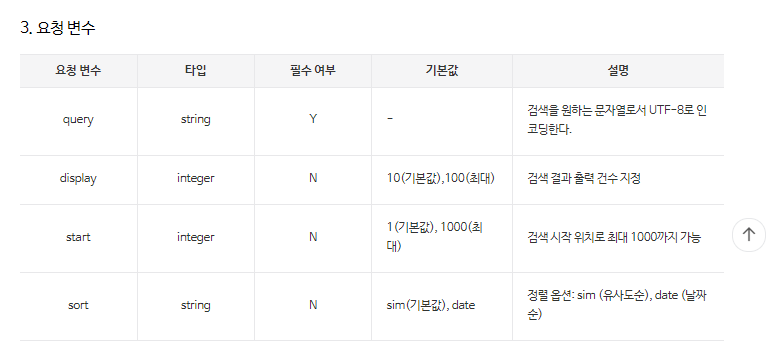
신청한 네이버 OPEN API 아이디와 시크릿 코드를 이용하여 블로그 게시물을 불러와줍니다.
저는 검색어를 '상암 맛집' 으로, 출력 개수는 예시로 10개 받아와 보도록 하겠습니다.
import urllib.request
from selenium.common.exceptions import NoSuchElementException
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# 웹드라이버 설정
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option("useAutomationExtension", False)
# 정보입력
client_id = "*********************" # 발급받은 id 입력
client_secret = "*************" # 발급받은 secret 입력
quote = input("검색어를 입력해주세요.: ") #검색어 입력받기
encText = urllib.parse.quote(quote)
display_num = input("검색 출력결과 갯수를 적어주세요.(최대100, 숫자만 입력): ") #출력할 갯수 입력받기
url = "https://openapi.naver.com/v1/search/blog?query=" + encText +"&display="+display_num# json 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
#print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
body = response_body.decode('utf-8')
body
[결과]
위를 보면 블로그 게시물에 대한 정보들이 나와 있습니다.
여기서 title (제목) 과 link(블로그 게시물 링크)를 추출하도록 하겠습니다.
여기서는 블로그의 대략적인 내용만 나오지 블로그 내용 전체가 나오지 않으므로
블로그 링크를 추출하여 각각의 블로그로 들어가 내용을 크롤링 하도록 해야 합니다.
step2. 게시글 제목 및 링크만 추출하기
위의 결괏값을 보면 "(큰따옴표)가 글 앞뒤로 붙어있는데 replace를 활용하여 지워주겠습니다.
# 불필요한 ""(큰따옴표)지워주기
body = body.replace('"','')
그다음 "가 없어진 내용을 가지고 제목, 링크를 추출해 보도록 하겠습니다.
그 전에 네이버 블로그 링크만 받아오기 위해 body를 split으로 나누어 글 하나 당 리스트 요소 1개가 되도록 나누도록 하겠습니다. 그 후 list comprehension을 사용하여 naver가 들어간 글만 리스트에 남아있도록 해 줍니다.
#body를 나누기
list1 = body.split('\n\t\t{\n\t\t\t')
#naver블로그 글만 가져오기
list1 = [i for i in list1 if 'naver' in i]
list1
[결과]
이렇게 naver블로그 글만 리스트에 담겼습니다.
제목은 title: 뒤, link: 앞에 위치하므로 re를 사용하여 제목만 추출하도록 하겠습니다.
각 링크는link:뒤,description앞에 위치하여 있습니다.
for문을 이용하여 한번에 제목, 링크를 추출해 보도록 하겠습니다.
#블로그 제목, 링크 뽑기
import re
titles = []
links = []
for i in list1:
title = re.findall('"title":"(.*?)",\n\t\t\t"link"',i)
link = re.findall('"link":"(.*?)",\n\t\t\t"description"',i)
titles.append(title)
links.append(link)
titles = [r for i in titles for r in i]
links = [r for i in links for r in i]
print('<<제목 모음>>')
print(titles)
print('총 제목 수: ',len(titles),'개')#제목갯수확인
print('\n<<링크 모음>>')
print(links)
print('총 링크 수: ',len(links),'개')#링크갯수확인
[결과]
위의 링크를 확인해 보면 보통의 url과는 다르게 '\\'(역 슬래쉬)가 많이 들어가 있음을 확인할 수 있습니다.
보통의 url링크를 가져오기 위해 링크 사이의 '\\'를 지워 다듬어진 링크를 가져오도록 하겠습니다.
# 링크를 다듬기 (필요없는 부분 제거 및 수정)
blog_links = []
for i in links:
a = i.replace('\\','')
b = a.replace('?Redirect=Log&logNo=','/')
# 다른 사이트 url이 남아있을 것을 대비해 한번 더 네이버만 남을 수 있게 걸러준다.
if 'naver.blog.com' in b:
blog_links.append(b)
print(blog_links)
print('생성된 링크 갯수:',len(blog_links),'개')
[결과]
그러면 위와 같이 링크가 예쁘게 출력되었습니다.
step3. 게시글 본문 가져오기
다음으로 블로그 링크를 활용하여 각 페이지에 접근해 본문을 가져오도록 하겠습니다.
NAVER 블로그는 각 게시물에 들어가 보면 아래와 같이 iframe 안에 게시물 본문 글이 위치하여 있습니다.
<body>밑에 iframe이 위치되어있음을 확인가능합니다.
때문에 Selenium을 이용하여 각 게시물의 iframe 접근 후 내용을 추출하는 방식으로 크롤링을 하여야 합니다.
#본문 크롤링
import time
from selenium import webdriver
# 크롬 드라이버 설치
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.implicitly_wait(3)
그다음으로 아까 다듬어진 링크에 접속하여 iframe 접근 후 본문의 내용을 크롤링하겠습니다.
본문은 iframe 안의 <div> class='se-main-container' 여기에 아래의 사진과 같이 들어있음을 확인할 수 있습니다.
파란색 부분이 있는 class 이름이 se-main-container임을 확인할 수 있습니다.
그래서 find_element_by_css_selector를 사용해 본문 글을 가져와 contents 변수에 담아 줍니다.
그리고 가끔 예전 블로그 글을 가져오게 될 때가 있는데 그 때는 현재 블로그 html 구조와 달라
No Such Element Error가 날 수 있습니다. 이때 구 블로그 글도 잘 가져올 수 있도록
예외처리를 하여 내용 부분을 크롤링 해 줍니다.
#블로그 링크 하나씩 불러서 크롤링
contents = []
for i in blog_links:
#블로그 링크 하나씩 불러오기
driver.get(i)
time.sleep(1)
#블로그 안 본문이 있는 iframe에 접근하기
driver.switch_to.frame("mainFrame")
#본문 내용 크롤링하기
#본문 내용 크롤링하기
try:
a = driver.find_element(By.CSS_SELECTOR,'div.se-main-container').text
contents.append(a)
# NoSuchElement 오류시 예외처리(구버전 블로그에 적용)
except NoSuchElementException:
a = driver.find_element(By.CSS_SELECTOR,'div#content-area').text
contents.append(a)
#print(본문: \n', a)
driver.quit() #창닫기
print("<<본문 크롤링이 완료되었습니다.>>")
[결과]
그러면 이렇게 모든 게시물의 본문 내용을 가져올 수 있습니다 ;-ㅇ
step4. 크롤링 내용들 DataFrame으로 만들기
마지막으로 아까 추출한 제목, 블로그 링크, 내용을 DataFrame으로 만들어 깔끔하게 정리해 보도록 하겠습니다.
#제목, 블로그링크, 본문내용 Dataframe으로 만들기
import pandas as pd
df = pd.DataFrame({'제목':titles, '링크':blog_links,'내용':contents})
#df 저장
df.to_csv('{}_블로그.csv'.format(quote),encoding='utf-8-sig',index=False)
[결과]
깔끔하게 df로 만들어졌습니다. ㅎㅎ
전체 코드
import urllib.request
from selenium.common.exceptions import NoSuchElementException
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# 웹드라이버 설정
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option("useAutomationExtension", False)
#정보입력
client_id = "********************" # 발급받은 id 입력
client_secret = "**********" # 발급받은 secret 입력
quote = input("검색어를 입력해주세요.: ") #검색어 입력받기
encText = urllib.parse.quote(quote)
display_num = input("검색 출력결과 갯수를 적어주세요.(최대100, 숫자만 입력): ") #출력할 갯수 입력받기
url = "https://openapi.naver.com/v1/search/blog?query=" + encText +"&display="+display_num# json 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
#print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
body = response_body.decode('utf-8')
print(body)
#body를 나누기
list1 = body.split('\n\t\t{\n\t\t\t')
#naver블로그 글만 가져오기
list1 = [i for i in list1 if 'naver' in i]
print(list1)
#블로그 제목, 링크 뽑기
import re
titles = []
links = []
for i in list1:
title = re.findall('"title":"(.*?)",\n\t\t\t"link"',i)
link = re.findall('"link":"(.*?)",\n\t\t\t"description"',i)
titles.append(title)
links.append(link)
titles = [r for i in titles for r in i]
links = [r for i in links for r in i]
print('<<제목 모음>>')
print(titles)
print('총 제목 수: ',len(titles),'개')#제목갯수확인
print('\n<<링크 모음>>')
print(links)
print('총 링크 수: ',len(links),'개')#링크갯수확인
# 링크를 다듬기 (필요없는 부분 제거 및 수정)
blog_links = []
for i in links:
a = i.replace('\\','')
b = a.replace('?Redirect=Log&logNo=','/')
# 다른 사이트 url이 남아있을 것을 대비해 한번 더 네이버만 남을 수 있게 걸러준다.
if 'naver.blog.com' in b:
blog_links.append(b)
print(blog_links)
print('생성된 링크 갯수:',len(blog_links),'개')
#본문 크롤링
import time
from selenium import webdriver
# 크롬 드라이버 설치
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.implicitly_wait(3)
#블로그 링크 하나씩 불러서 크롤링
contents = []
for i in blog_links:
#블로그 링크 하나씩 불러오기
driver.get(i)
time.sleep(1)
#블로그 안 본문이 있는 iframe에 접근하기
driver.switch_to.frame("mainFrame")
#본문 내용 크롤링하기
try:
a = driver.find_element(By.CSS_SELECTOR,'div.se-main-container').text
contents.append(a)
# NoSuchElement 오류시 예외처리(구버전 블로그에 적용)
except NoSuchElementException:
a = driver.find_element(By.CSS_SELECTOR,'div#content-area').text
contents.append(a)
#print(본문: \n', a)
driver.quit() #창닫기
print("<<본문 크롤링이 완료되었습니다.>>")
#제목 및 본문 txt에 저장
total_contents = titles + contents
text = open("blog_text.txt",'w',encoding='utf-8')
for i in total_contents:
text.write(i)
text.close()
#제목, 블로그링크, 본문내용 Dataframe으로 만들기
import pandas as pd
df = pd.DataFrame({'제목':titles, '링크':blog_links,'내용':contents})
print(df)
#df 저장
df.to_csv('{}_블로그.csv'.format(quote),encoding='utf-8-sig',index=False)
마무리
오늘은 네이버 API를 이용하여 블로그 제목 및 내용을 가져와봤는데요
이번 포스팅을 작성하는 데 꽤 시간이 걸렸는데 이렇게 깔끔하게 할 수 있어 정말 기쁘네요.ㅎㅎ
오늘은 전에 알려드린 오픈 API 사용과 더불어 파이썬으로 크롤러 만드는 방법을 소개하도록 하겠습니다.
네이버 오픈 API의 경우 사용하는 방법을 알면 간편하게 뉴스, 블로그, 카페 등등을 크롤링하여 정보를 수집할 수 있습니다. 하지만 개인당 일일 오픈 API 사용량이 제한되어 있어 빅데이터를 분석 시 그보다 더 큰 데이터를 수집해야 할 때가 있어 오픈 API만으로 필요한 정보를 모두 수집하기는 어렵습니다. 그래서 이번에는 Python으로 네이버 뉴스 크롤링하는 방법을 알아보려고 합니다.
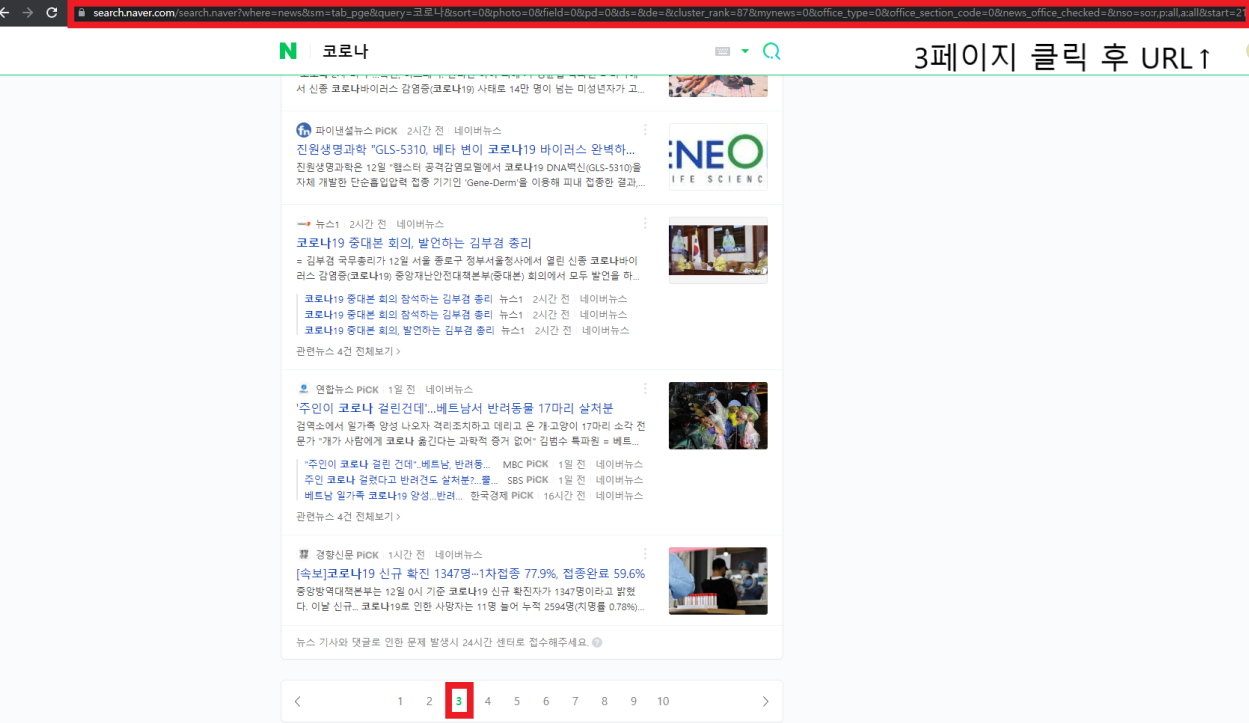
뉴스 크롤링을 위에 보이는 페이지만 하는 것이 아니기 때문에 스크롤 다운을 하여 페이지 1을 클릭하여 줍니다.
<페이지 1을 클릭한 뒤의 URL> https://search.naver.com/search.naver?where=news&sm=tab_pge&query=코로나&sort=0&photo=0&field=0&pd=0&ds=&de=&cluster_rank=32&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so:r,p:all,a:all&start=1
페이지 1을 클릭하고 URL을 확인하여 보니 아까 검색어만 입력했을 때와는 달리 엄청 길고 복잡한 URL이 나왔습니다.
다음으로 페이지 2,3을 각각 클릭하여 위의 URL과 어떤 다른 점이 있는지 확인하여 보겠습니다.
<페이지 1을 클릭한 뒤의 URL> https://search.naver.com/search.naver?where=news&sm=tab_pge& query=코로나 &sort=0&photo=0&field=0&pd=0&ds=&de=&cluster_rank=32&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so:r,p:all,a:all& start=1
<페이지 2를 클릭한 뒤의 URL> https://search.naver.com/search.naver?where=news&sm=tab_pge&query=코로나&sort=0&photo=0&field=0&pd=0&ds=&de=&cluster_rank=64&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so:r,p:all,a:all&start=11
<페이지 3을 클릭한 뒤의 URL> https://search.naver.com/search.naver?where=news&sm=tab_pge&query=코로나&sort=0&photo=0&field=0&pd=0&ds=&de=&cluster_rank=87&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so:r,p:all,a:all&start=21
위와 같이 URL을 모아 보면 공통부분이 있습니다.
검색어를 입력하는 &query=코로나 부분과,
페이지를 입력하는 &start=1(1페이지),11(2페이지),21(3페이지)... 이 부분이 공통적인 요소입니다.
위의 내용을 토대로 중간 부분을 생략하고(생략하여도 검색에 문제는 없습니다.) 공통의 URL을 도출해 내면 아래와 같습니다.
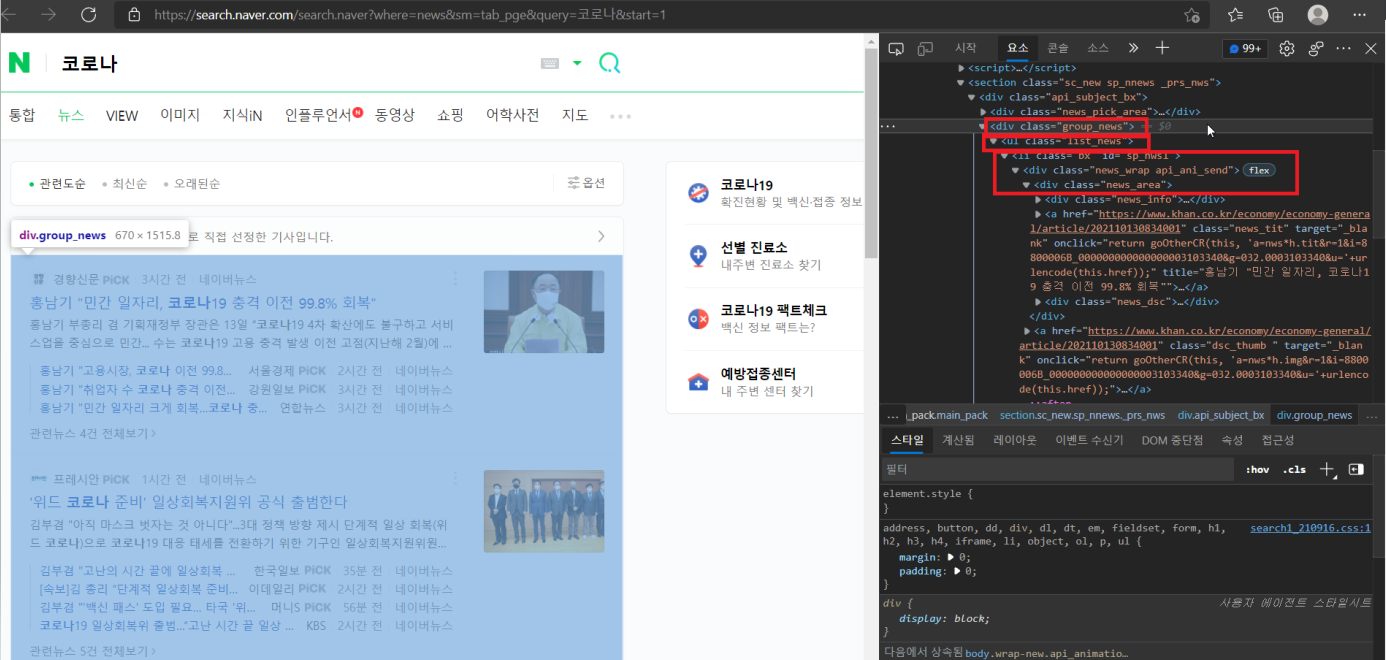
각 기사의 내용을 크롤링하려면 step6에서와 같이 각각의 기사 링크를 타고 들어가 f12를 누르고 개발자 도구를 통해 html의 구조 및 필요한 내용이 어디에 위치해 있는지를 확인하여야 합니다.
하지만 각각의 언론사는 다 다른 html 구조를 가지고 있기 때문에 정확하게 크롤링하려면 번거롭고 시간이 많이 듭니다.
보통 기사는 p 태그에 본문 내용이 있기 때문에 p태그에 있는 모든 내용을 가져오는 코드를 작성해 보도록 하겠습니다.
#뉴스기사 내용 크롤링하기
contents = []
for i in news_url:
#각 기사 html get하기
news = requests.get(i)
news_html = BeautifulSoup(news.text,"html.parser")
#기사 내용 가져오기 (p태그의 내용 모두 가져오기)
contents.append(news_html.find_all('p'))
contents
결괏값:
p class="tit">이시간 <span>핫 뉴스</span></p>, <p class="tit">오늘의 헤드라인</p>, <p class="tit"><a href="/view?id=NISX20211014_0001613089">"확진 1940명…100일째 네자리 연휴 끝난 후 3일 연속 증가세</a></p>, <p class="subTit"></p>, <p class="txt"><a href="/view?id=NISX20211014_0001613089">코로나19 신규 확진자 수가 1940명으로 집계돼 다시 2000명대에 육박했다. 신규 확진자 수는 최근 3일 연속 증가세인데, 정부는 단계적 일상회복 전 마지막 사회적 거리두기 단계 조정안을 오는 15일 발표할 예정이다. 질병관리청 중앙방역대책본부(방대본)에 따르면 14일 0시 기준 누적 확진자는 전날보다 1940명 증가한 33만7679명이다.</a></p>, <p class="tit"><a href="/view?id=NISX20211014_0001612865">"김만배, 구속심사 출석…'700억대' 뇌물 등 혐의</a></p>, <p class="tit"><a href="/view?id=NISX20211014_0001612930">"李 34%·尹 33.7%…이낙연 지지층, 尹으로 이탈</a></p>, <p class="tit"><a href="/view?id=NISX20211013_0001612719">"[단독]음저협, 저작권료 41억 받고도 미분배</a></p>, <p class="tit"><a href="/view?id=NISX20211014_0001613023">"日언론 "기시다, 이르면 오늘 文대통령과 통화"</a></p>, <p class="tit"><a href="/view?id=NISX20211014_0001613075">"尹 "당 없어지는 게 낫다"에 劉·洪 "못된 버르장머리"</a></p>, <p class="tit">많이 본 기사</p>...(중략)
기사의 모든 본문을 가지고 있지만 본문 뿐만이 아니라 p태그의 모든 내용이 크롤링 되기 때문에 크롤링 후 전처리가 필수적으로 진행이 되어야 합니다. 추후 전처리에 관련해서도 포스팅 할 예정입니다.
전체 코드
#크롤링시 필요한 라이브러리 불러오기
from bs4 import BeautifulSoup
import requests
#검색어 입력
search = input("검색할 키워드를 입력해주세요:")
#검색할 페이지 입력
page = int(input("크롤링할 페이지를 입력해주세요. ex)1(숫자만입력):")) # ex)1 =1페이지,2=2페이지...
print("크롤링할 페이지: ",page,"페이지")
#start수를 1, 11, 21, 31 ...만들어 주는 함수
page_num = 0
if page == 1:
page_num =1
elif page == 0:
page_num =1
else:
page_num = page+9*(page-1)
#url 생성
url = "https://search.naver.com/search.naver?where=news&sm=tab_pge&query=" + search + "&start=" + str(page_num)
print("생성url: ",url)
# ConnectionError방지
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/100.0.48496.75" }
#html불러오기
original_html = requests.get(url, headers=headers)
html = BeautifulSoup(original_html.text, "html.parser")
# 검색결과
articles = html.select("div.group_news > ul.list_news > li div.news_area > a")
print(articles)
# 검색된 기사의 갯수
print(len(articles),"개의 기사가 검색됌.")
#뉴스기사 제목 가져오기
news_title = []
for i in articles:
news_title.append(i.attrs['title'])
news_title
#뉴스기사 URL 가져오기
news_url = []
for i in articles:
news_url.append(i.attrs['href'])
news_url
#뉴스기사 내용 크롤링하기
contents = []
for i in news_url:
#각 기사 html get하기
news = requests.get(i,headers=headers)
news_html = BeautifulSoup(news.text,"html.parser")
#기사 내용 가져오기 (p태그의 내용 모두 가져오기)
contents.append(news_html.find_all('p'))
contents