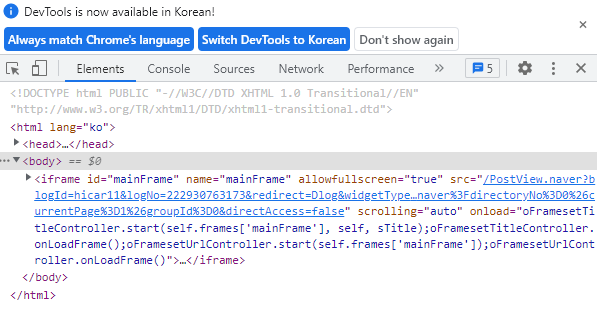
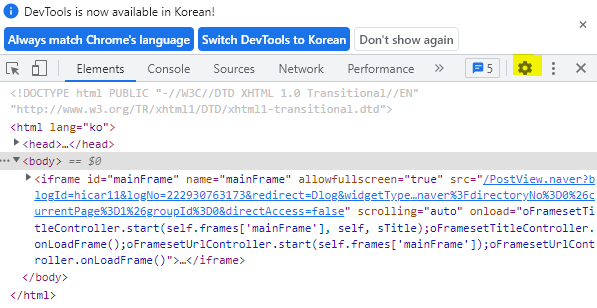
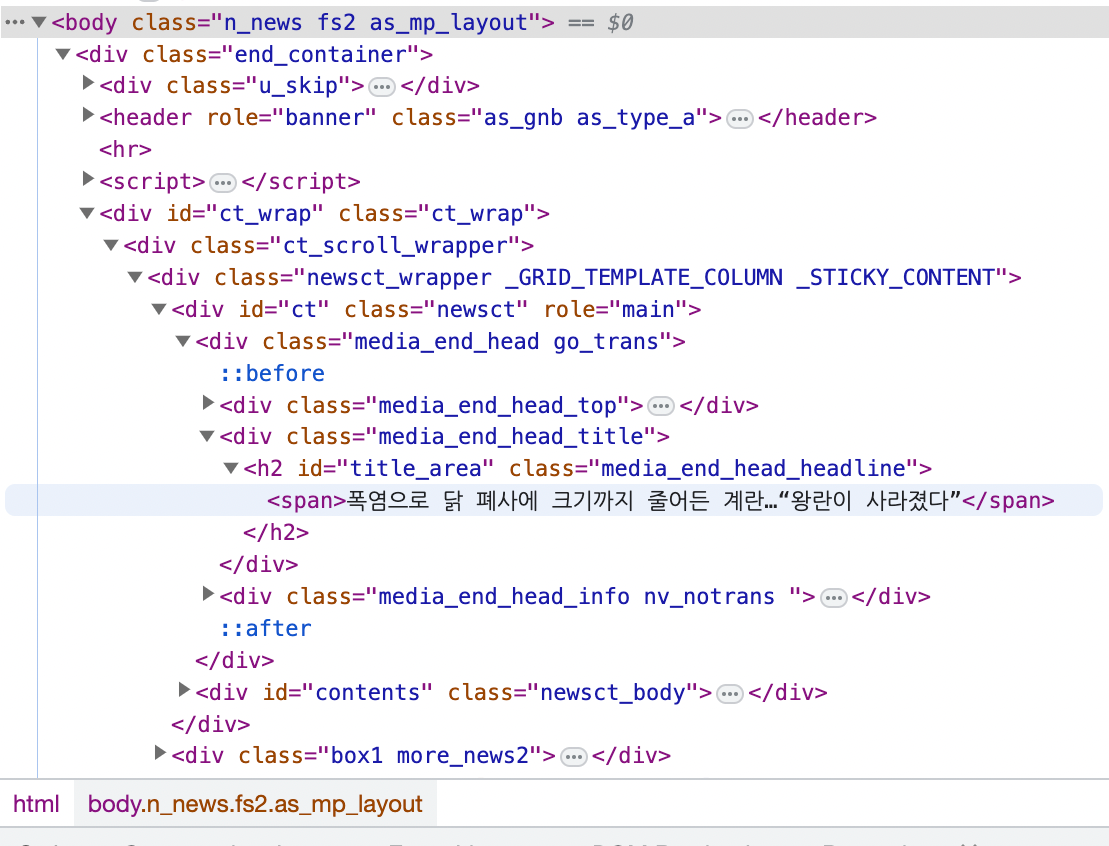
위의 사진에서 빨간색 박스로 표시된 아이콘을 클릭 후 왼쪽에 기사에 내가 확인하고 싶은 기사에 커서를 가져가면
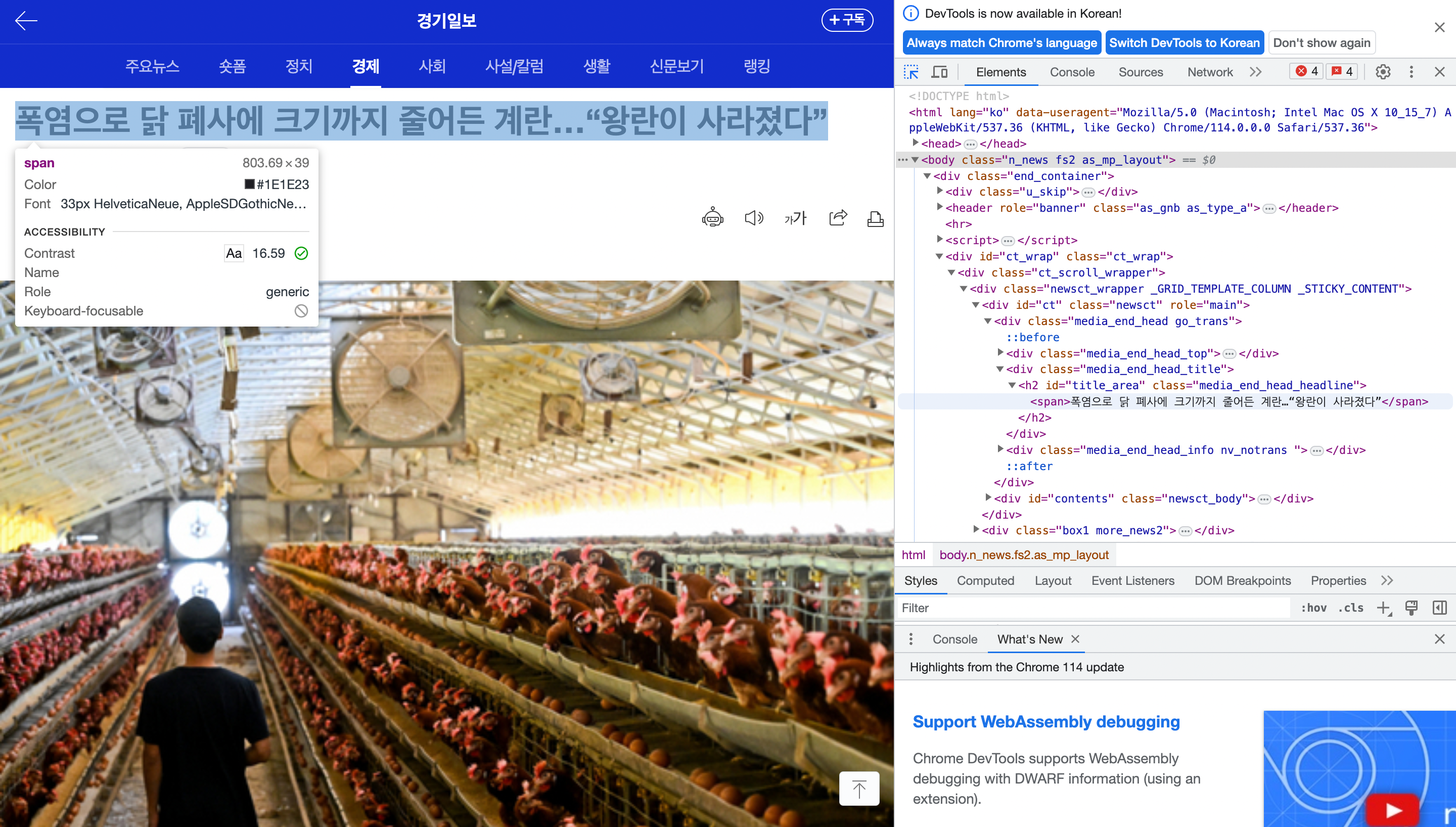
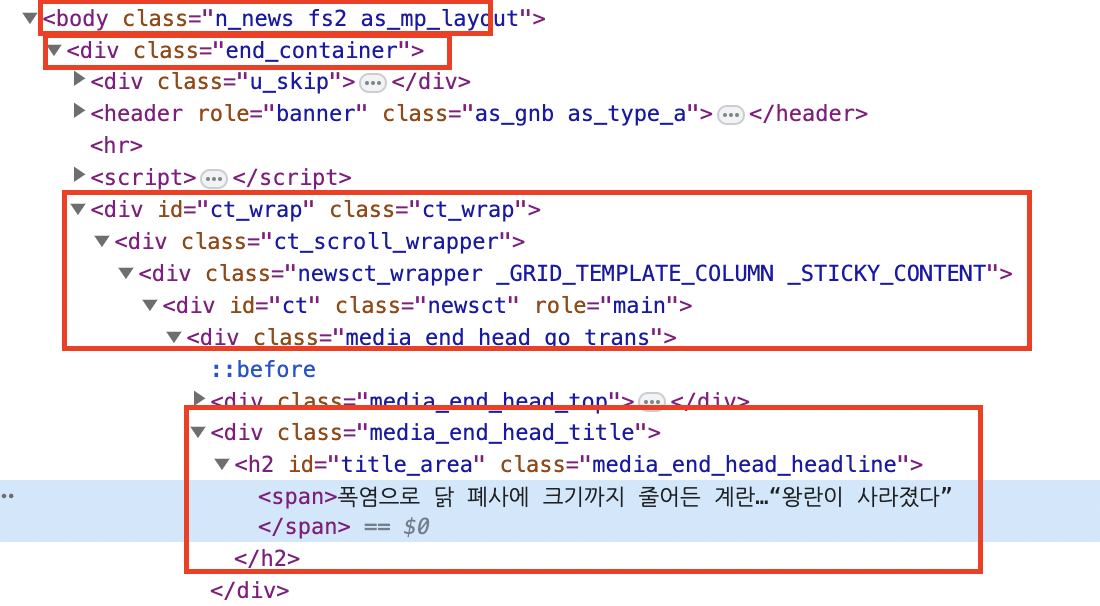
아래 사진과 같이 파란색으로 표시가 됩니다.
그후 오른쪽 창을 보면 아까는 보이지 않았던 제목 부분이 보입니다.
여기서 원래대로라면 body 밑에 div class name이 end_container인것 밑에 div ct_wrap 밑에 ct_scroll_wrapper 밑에 newsct... 밑에 이런 식으로 쭉쭉 타고 내려가서 h2에 span 에 제목이 위치해 있는 것을 확인할 수 있겠습니다만 귀찮고 복잡합니다.
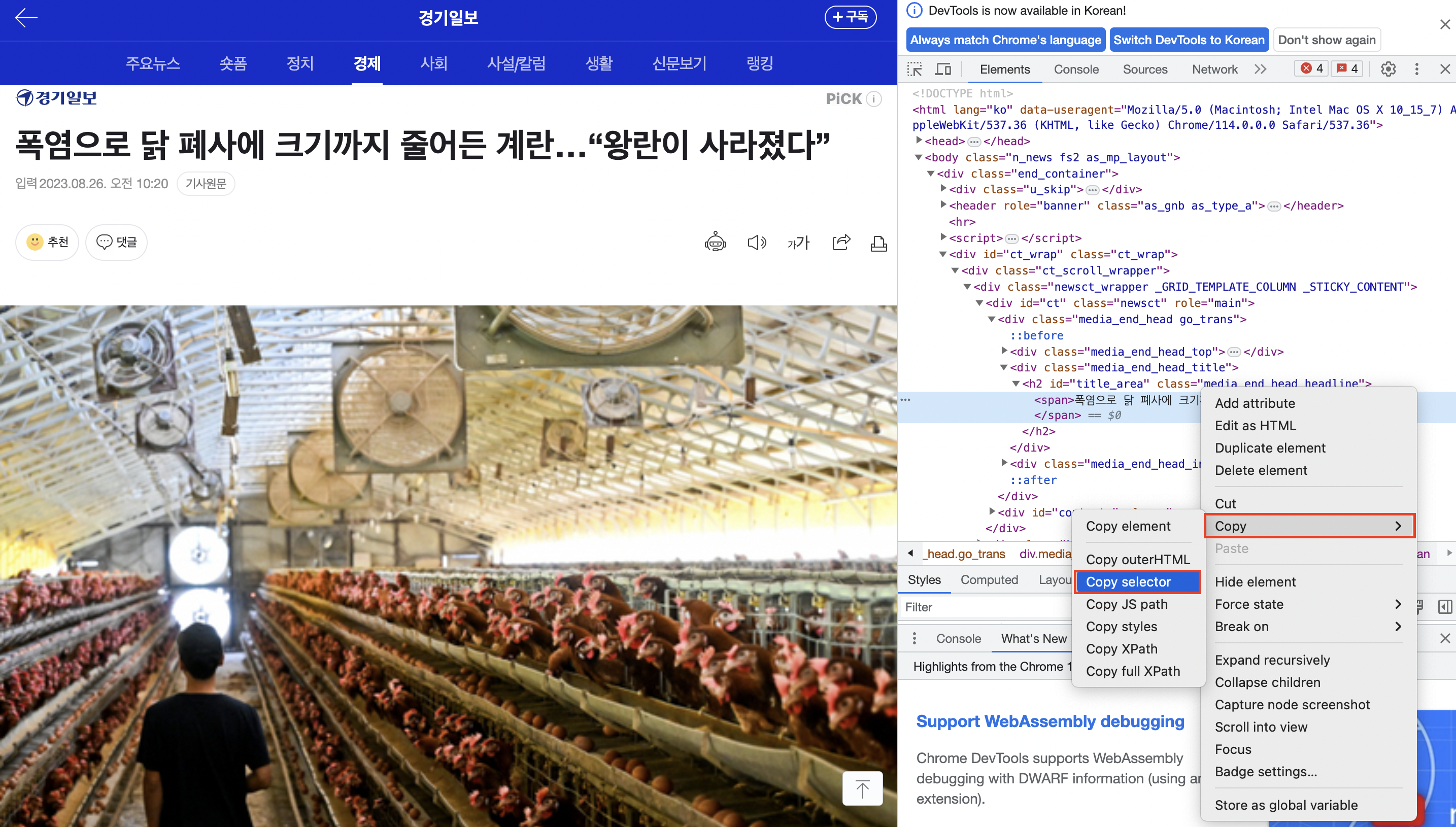
이렇게 하나하나 눈으로 봐도 되지만 이 대신에 copy selector를 사용하면
더 간단하게 Beautiful Soup의 html selector를 사용해서 바로 가져올 수 있습니다.
- 체크포인트 회복 기법: 장애 발생 시 검사점 이후에 처리된 트랜잭션에 대해서만 장애 발생 이전의 상태로 복원시키는 회복 기법
- 그림자 페이징 회복 기법: DB 트랜잭션 수행 시 복제본을 생성하여 데이터베이스 장애 시 이를 이용해 복구하는 기법
네트워크 공격 기법
이름
설명
스니핑(Sniffing)
공격 대상에게 직접 공격을 하지 않고 데이터만 몰래 들여다보는 공격 기법(수동적)
네트워크 스캐너, 스니퍼
네트워크 HW,SW 구성의 취약점 파악을 위해 공격자가 취약점을 탐색하는 공격 기법
패스워드 크래킹(Password Cracking)
아래와 같은 공격을 활용함 - 사전(Dictionary) 크래킹: ID와 PW가 될 가능성이 있는 단어를 파일로 만들어 놓고 이 파일의 단어를 대입하여 크랙하는 공격 기법 - 무차별 크래킹: PW로 사용될 수 있는 영문자, 숫자, 특수문자 등을 무작위로 대입하여 비번을 알아내는 공격 기법 - 패스워드 하이브리드 공격: 사전 , 무차별 대입 공격을 결합하여 공격하는 기법 - 레인보우 테이블 공격: 비번별로 해시값을 미리 생성하여 테이블에 모아 두고, 크래킹하고자 하는 해시값을 테이블에서 검색해서 역으로 비번을 찾는 공격 기법
IP 스푸핑(IP Spoofing)
침입자가 인증된 컴퓨팅 시스템인 것처럼 속여서 타깃의 시스템 정보를 빼내기 위해 본인의 패킷 헤더를 인증된 호스트의 IP 주소로 위조해 타깃에 전송하는 공격 기법
ARP 스푸핑
공격자가 특정 호스트의 MAC 주소를 자신의 MAC 주소로 위조한 APR Reply를 만들어 희생자에게 지속적으로 전송하여 희생자의 APR 캐시 테이블에 특정 호스트의 MAC 정보를 공격자의 MAC 정보로 변경, 희생자로부터 특정 호스트로 나가는 패킷을 공격자가 스니핑하는 공격 기법
ICMP Redirect 공격
- 3계층에서 스니핑 시스템을 네트워크에 존재- 하는 또다른 라우터라고 알림으로써 패킷의 흐름을 바꾸는 공격 기법 - 메시지를 공격자가 원하는 형태로 만들어 특정 목적지로 가는 패킷을 공격자가 스니핑하는 공격 기법
트로이 목마
악성 루틴이 숨어 있는 프로그램으로 겉보기에 정상적인 프로그램으로 보이지만 실행하면 악성 코드를 실행하는 프로그램
SW 개발 보안의 3요소
요소
설명
기밀성(Confidentiality)
인가되지 않은 개인 or 시스템 접근에 따른 정보 공개 및 노출을 차단하는 특성
무결성(Integrity)
정당한 방법을 따르지 않고서 데이터가 변경될 수 없으며, 데이터의 정확성 및 완전성과 고의 또는 악의로 변경되거나 훼손 또는 파괴되지 않음을 보장하는 특성
가용성(Availability)
권한을 가진 사용자나 애플리케이션이 원하는 서비스를 지속해서 사용할 수 있도록 보장하는 특성
import pygame, sys
from pygame.locals import *
import random, time
pygame.init()
# 초당 프레임 설정
FPS = 60
FramePerSec = pygame.time.Clock()
# 색상 세팅(RGB코드)
RED = (255, 0, 0)
ORANGE = (255, 153, 51)
YELLOW = (255, 255, 0)
GREEN = (0, 255, 0)
SEAGREEN = (60, 179, 113)
BLUE = (0, 0, 255)
BLACK = (0, 0, 0)
WHITE = (255, 255, 255)
VIOLET = (204, 153, 255)
PINK = (255, 153, 153)
GREY = (213,213,213)
LIGHT_GREY = (246,246,246)
LIGHT_BLACK = (76,76,76)
# 게임 진행에 필요한 변수들 설정
SPEED = 5 # 게임 진행 속도
SCORE = 0 # 플레이어 점수
# 폰트 설정
font = pygame.font.SysFont('Tahoma', 60) # 기본 폰트 및 사이즈 설정(폰트1)
small_font = pygame.font.SysFont('Malgun Gothic', 20,bold=True) # 작은 사이즈 폰트(폰트2)
middle_font = pygame.font.SysFont('Malgun Gothic', 40) # 중간 사이즈 폰트(폰트3)
game_over = font.render("GG", True, BLACK) # 게임 종료시 문구
# 게임 배경화면
background = pygame.image.load('resources/background1.jpg') # 배경화면 사진 로드
# 게임 화면 생성 및 설정
display_width = 640
display_height = 440
GameDisplay = pygame.display.set_mode((display_width,display_height))
GameDisplay.fill(PINK)
pygame.display.set_caption("Mini Game")
#점수 reset함수
def reset():
global SCORE
SCORE = 0
return SCORE
Button 함수 만들기
Intro,outro에 사용할 버튼을 간단하게 만들기 위해 버튼을 만드는 함수를 하나 추가해 줍니다.
이 버튼 함수는 버튼 영역 안에 마우스 포인터가 들어가면 색이 바뀌고 클릭 시 True값을 return 합니다.
더 자세히 설명하자면 아래와 같습니다.
button(버튼안에 들어갈 메세지, x좌표,y좌표, 도형의가로길이,도형의세로길이,도형색, 포인터가 도형위에 위치시 변하는 색, action=True(클릭했을 때 이벤트 활성화), 버튼글씨색 설정 )
#버튼 생성 함수
def button(msg,x,y,w,h,ic,ac,action=None,fcolor=BLACK):
mouse = pygame.mouse.get_pos()
click = pygame.mouse.get_pressed()
#print(click)
if x+w > mouse[0] > x and y+h > mouse[1] > y:
pygame.draw.ellipse(GameDisplay, ac,(x,y,w,h))
if click[0] == 1 and action != None:
return True
else:
pygame.draw.ellipse(GameDisplay, ic,(x,y,w,h))
textSurf = middle_font.render(msg,True,fcolor)
textRect = textSurf.get_rect()
textRect.center = ( (x+(w/2)), (y+(h/2)) )
GameDisplay.blit(textSurf, textRect)
Intro 만들기
게임 설명 텍스트를 위치시켜주고,
start, quit 버튼을 만들어서
start를 누를 시 게임을 시작하고, quit을 누르면 창이 닫히도록 game_intro 함수를 만들어 주었습니다.
# 시작(intro) 화면
def game_intro():
intro = True
while intro:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
quit()
# 배경화면 사진 게임창에 불러오기(사진, 위치)
GameDisplay.blit(background, (0, 0)) #TODO
# 텍스트 생성 및 배치하기
large_Text = pygame.font.SysFont('Tahoma', 100)
Text1,Text1Rect = text_objects("How to Play",large_Text)
Text2,Text2Rect = text_objects("Use ← , → to avoid bombs!",middle_font)
Text3,Text3Rect = text_objects("방향키 ← , →를 사용하여 폭탄을 피하세요!",small_font)
Text1Rect.center = ((display_width/2),(display_height/4.5))
Text2Rect.center = ((display_width/2),(display_height/2.5))
Text3Rect.center = ((display_width/2),(display_height/2))
GameDisplay.blit(Text1, Text1Rect)
GameDisplay.blit(Text2,Text2Rect)
GameDisplay.blit(Text3,Text3Rect)
#start,quit버튼
introBtn1 = button("START",display_width/6,display_height/1.7,200,100,BLACK,BLUE,action=True,fcolor=YELLOW)
introBtn2 = button("QUIT",display_width/2,display_height/1.7,200,100,BLACK,RED,action=True,fcolor=YELLOW)
#버튼을 눌렀을 때
if introBtn1 == True:
return game()
if introBtn2 ==True:
pygame.quit()
quit()
pygame.display.update()
FramePerSec.tick(FPS)
게임에서 동작할 class 만들기
게임에서 사용할 플레이어 및 적 개체 class를 저번 처럼만들어 줍니다.
## 게임 내에서 동작할 클래스 설정 ##
## 플레이어에게 적용할 클래스
class Player(pygame.sprite.Sprite):
# 플레이어 이미지 로딩 및 설정 함수
def __init__(self):
super().__init__()
# 플레이어 사진 불러오기
self.image = pygame.image.load('resources/chick.png')
# 이미지 크기의 직사각형 모양 불러오기
self.rect = self.image.get_rect()
# rec 크기 축소(충돌판정 이미지에 맞추기 위함)
self.rect = self.rect.inflate(-20,-20)
# 이미지 시작 위치 설정
self.rect.center = (540, 390)
# 플레이어 키보드움직임 설정 함수
def move(self):
prssdKeys = pygame.key.get_pressed()
# 왼쪽 방향키를 누르면 5만큼 왼쪽 이동
if self.rect.left > 0:
if prssdKeys[K_LEFT]:
self.rect.move_ip(-5, 0)
position_p = self.rect.center
return position_p
# 오른쪽을 누르면 5만큼 오른쪽으로 이동
if self.rect.right < 640:
if prssdKeys[K_RIGHT]:
self.rect.move_ip(5, 0)
position_p = self.rect.center
return position_p
## 적에게 적용할 클래스
class Enemy(pygame.sprite.Sprite):
# 적의 이미지 로딩 및 설정 함수
def __init__(self):
super().__init__()
# 적 사진 불러오기
self.image = pygame.image.load('resources/boom2.png')
# 이미지 크기의 직사각형 모양 불러오기
self.rect = self.image.get_rect()
# rec 크기 축소(충돌판정 이미지에 맞추기 위함)
self.rect = self.rect.inflate(-20,-20)
# 이미지 시작 위치 설정
self.rect.center = (random.randint(40, 600), 0)
# 적의 움직임 설정 함수+ 플레이어 점수 측정
def move(self):
global SCORE
# 적을 10픽셀크기만큼 위에서 아래로 떨어지도록 설정
self.rect.move_ip(0, SPEED) # x,y좌표 설정
# 이미지 가 화면 끝에 있으면(플레이어가 물체를 피하면) 다시 이미지 위치 세팅 + 1점 추가
if (self.rect.bottom > 440):
SCORE += 1
self.rect.top = 0
self.rect.center = (random.randint(30, 610), 0)
return self.rect.center
게임 만들기
이제 위의 클래스를 사용하여 폭탄 피하기 게임을 만들어 줍니다.
게임 종료 시 outro화면으로 넘어갈 수 있도록 설정하는 것도 잊지 말고 넣어 줍니다.
###### 게임 설정 ########
# 플레이어 및 적 개체 생성
def game(speed = SPEED):
P1 = Player()
E1 = Enemy()
# Sprites Groups 생성하기
# 게임 물체들을 그룹화 하여 그룹별로 접근하여 설정 시 용이하게 만들기
# 적(enemy) 객체 그룹화하기
Enemies = pygame.sprite.Group()
Enemies.add(E1)
# 전체 그룹을 묶기
All_groups = pygame.sprite.Group()
All_groups.add(P1)
All_groups.add(E1)
# 적 개체 1초(1000ms)마다 새로 생기는 이벤트 생성
increaseSpeed = pygame.USEREVENT + 1
pygame.time.set_timer(increaseSpeed, 1000)
# 게임 BGM 설정
bgm = pygame.mixer.Sound('resources/backgroundMusic.mp3')
bgm.play()
## 게임 루프 설정 ##
# 게임 종료되기 전까지 실행되는 루프(이벤트) 설정
while True:
for event in pygame.event.get():
# type increaseSpeed이면 속도 증가하여 어렵게 만듬(적 물체 이벤트)
if event.type == increaseSpeed:
speed += 0.5
# 이벤트가 종료되면 게임도 종료시킴
if event.type == QUIT:
pygame.quit()
sys.exit()
# 배경화면 사진 게임창에 불러오기(사진, 위치)
GameDisplay.blit(background, (0, 0))
# 하단부에 위치할 스코어 점수(적을 피할때마다 +1점 증가)
scores = small_font.render("Score: " + str(SCORE), True, BLACK)
GameDisplay.blit(scores, (10, 400))
# group1 = '<Player Sprite(in 1 groups)>'
# group2 = '<Enemy Sprite(in 2 groups)>'
# 게임 내 물체 움직임 생성
for i in All_groups:
GameDisplay.blit(i.image, i.rect)
i.move()
if str(i) == '<Player Sprite(in 1 groups)>':
player_pos = i
else:
enemy_pos = i
# <Player Sprite(in 1 groups)>
# 플레이어 충돌 판정(게임종료)시
if pygame.sprite.spritecollideany(P1, Enemies):
for i in All_groups:
i.kill()
# 물체 이미지 변경(충돌후 변경되는 이미지)
# 플레이어
GameDisplay.blit(background, (0, 0))
image0 = pygame.image.load('resources/chickbommed.png')
image0.get_rect()
GameDisplay.blit(image0, player_pos)
# 폭탄
image1 = pygame.image.load('resources/boomm.png')
image1.get_rect()
GameDisplay.blit(image1, enemy_pos)
pygame.display.update()
# 배경음악 멈춤
bgm.stop()
# 적과 충돌시 효과음 추가
pygame.mixer.Sound('resources/BOOM.WAV').play()
time.sleep(0.5)
# 게임오버화면 설정
pygame.mixer.Sound('resources/gameover.mp3').play()
pygame.display.update()
game_outro()
pygame.display.update()
# 초당 프레임 설정
FramePerSec.tick(FPS)
Outro 만들기
게임 종료 화면을 만들어 줍니다.
게임 점수를 배치하고 버튼을 배치하여,
다시 플레이하고 싶은 사람은 score 리셋 후 retry를, 종료하고 싶은 사람은 quit을 눌러 창을 닫을 수 있도록 설정합니다.
## 게임오버 페이지
def game_outro():
outro = True
while outro:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
quit()
GameDisplay.blit(background, (0, 0))
final_scores = font.render("Your Score: " + str(SCORE), True, BLACK)
Music = small_font.render("Music: www.bensound.com",True,BLACK)
Photos = small_font.render("Photos: pixabay, pngwing",True,BLACK)
Madeby = small_font.render("Made by wonhwa.tistory.com",True,BLACK)
GameDisplay.blit(final_scores, (150, 100))
GameDisplay.blit(game_over, (280, 200))
GameDisplay.blit(Music,(10,400))
GameDisplay.blit(Photos,(10,380))
GameDisplay.blit(Madeby,(350,400))
#retry,quit버튼
outroBtn1 = button("RETRY",display_width/6,display_height/1.7,200,100,BLACK,BLUE,action=True,fcolor=YELLOW)
outroBtn2 = button("QUIT",display_width/2,display_height/1.7,200,100,BLACK,RED,action=True,fcolor=YELLOW)
#time.sleep(1)
#pygame.display.update()
#time.sleep(5)
#TODO: 버튼 누르면 동작
if outroBtn1 == True:
reset()
game()
if outroBtn2 ==True:
pygame.quit()
sys.exit()
pygame.display.update()
FramePerSec.tick(FPS)
이제 이 민원 토픽들을 가지고 시간별로 어떤 종류의 토픽이 많이 나왔는지 확인하기 위한 트렌드 분석을 진행해 보겠습니다.
날짜 데이터는 '등록일자(RCPT_YMD)' 컬럼에 있습니다.
행이 5만개가 되기 때문에 날짜를 월단위까지만 자른 데이터를 토픽 분포 데이터와 합치도록 하겠습니다.
from sklearn.feature_extraction.text import CountVectorizer
trend_data = pd.DataFrame(minwon_topics,columns=['토픽'+str(i) for i in range(1,5)])
trend_data = pd.concat([trend_data,df['등록일자(RCPT_YMD)'].map(lambda x:x[:7])], axis=1)
trend_data.head()
이후 groupby를 사용하여 월 단위로 토픽의 평균을 구해보겠습니다.
#월별 평균 구하기
trend = trend_data.groupby(['등록일자(RCPT_YMD)']).mean()
trend.head()
이제 월별로 토픽 비중이 어떻게 변했는지 확인하기 위해 matplotlib을 사용하여 그래프를 그려 보도록 하겠습니다.
matplotlib의 AutoDateLocator를 사용하여 x축은 6개월 단위로 눈금 및 값을 표시해서 보여주도록 하겠습니다.
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import font_manager,rc
from matplotlib.dates import AutoDateLocator,MonthLocator
# 한글 폰트 설정
font_location = 'C:/Windows/Fonts/MALGUNSL.TTF' #맑은고딕
font_name = font_manager.FontProperties(fname=font_location).get_name()
rc('font',family=font_name)
#날짜설정
locator = AutoDateLocator()
locator.intervald['MONTHLY'] = [6]
print_top_words(lda, Count_vector.get_feature_names_out(),20)
fig,axes = plt.subplots(2,2,figsize=(10,10))
for col,ax in zip(trend.columns.tolist(),axes.ravel()):
ax.set_title(col)
ax.xaxis.set_major_locator(locator)
ax.axes.xaxis.set_visible(True)
ax.plot(trend[col])
plt.show()
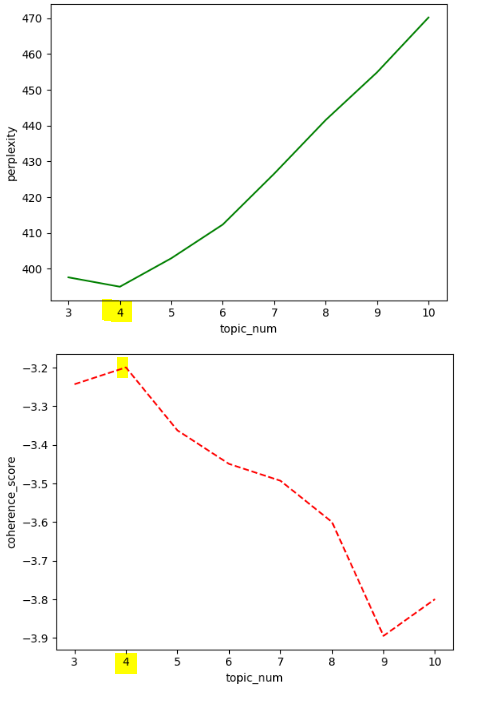
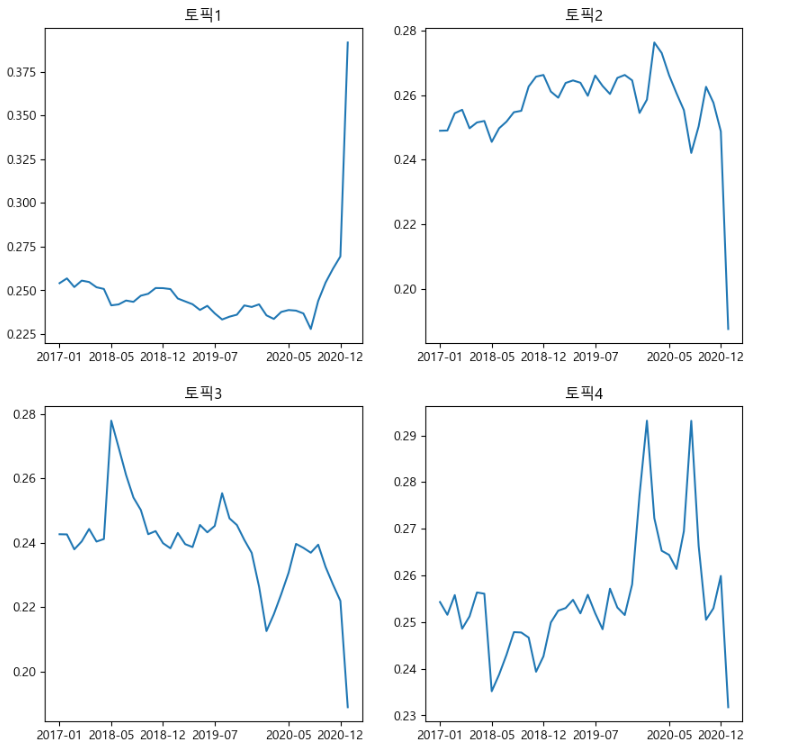
4개의 토픽에서 토픽별로 시간에 따라 분포가 어떻게 변화했는지 확인할 수 있습니다.
각 토픽 주제는 대략적으로
토픽 1: 피해 상담 문의
토픽2: 환불 및 반품 문의
토픽3: 수리 및 보상 문의
토픽4: 계약 해지 문의
이렇게 볼 수 있을 것 같습니다.
토픽1 은 최근에 급격히 비중이 늘어났고, 토픽 3번은 시간에 따라 비중이 줄어들고 있고, 토픽 4번은 후반부에 비중이 늘어남을 확인할 수 있습니다.
for topic_idx, topic in enumerate(lda.components_):
print("토픽 #%d: " % topic_idx, end='')
print(", ".join([Count_vector.get_feature_names_out()[i] for i in topic.argsort()[:10]]))
이렇게 결과가 나옵니다. 하지만 이는 비중이 작은 순서라서 다시 가장 비중이 큰 10개만 다시 뽑아보면,
for topic_idx, topic in enumerate(lda.components_):
print("토픽 #%d: " % topic_idx, end='')
print(", ".join([Count_vector.get_feature_names_out()[i] for i in topic.argsort()[:-11:-1]]))
비슷한 단어가 많이 겹치는 것을 확인할 수 있습니다.
단순히 응집도 점수만 봤을 때 이런 결과가 나오니 다른 토픽 수도 확인하여 결정하는 것이 좋을 것 같습니다.