
안녕하세요! 오늘은 텍스트 군집분석을 진행해보고자 합니다.
군집분석은 여러 문서들이 있을 때 유사한 텍스트끼리 그룹화하는 분석을 말합니다.
그중에서도 오늘은 분할 군집분석을 진행해 보겠습니다.
분할 군집 분석은 데이터를 k개의 그룹으로 나누어 주는 것을 말하는데 k개는 분석하는 사람에 따라 지정되는 숫자입니다. 연구자가 주관적으로 데이터 내에서 2개의 그룹으로 나누거나 3개의 그룹으로 나누어 겠다라고 결정하면 그 그룹 숫자에 따라 데이터들이 군집화 됩니다.
K-평균 군집 분석(K-means)
K-means (K-평균 군집 분석) 알고리즘은 아래의 사진으로쉽게 이해가 가능합니다.
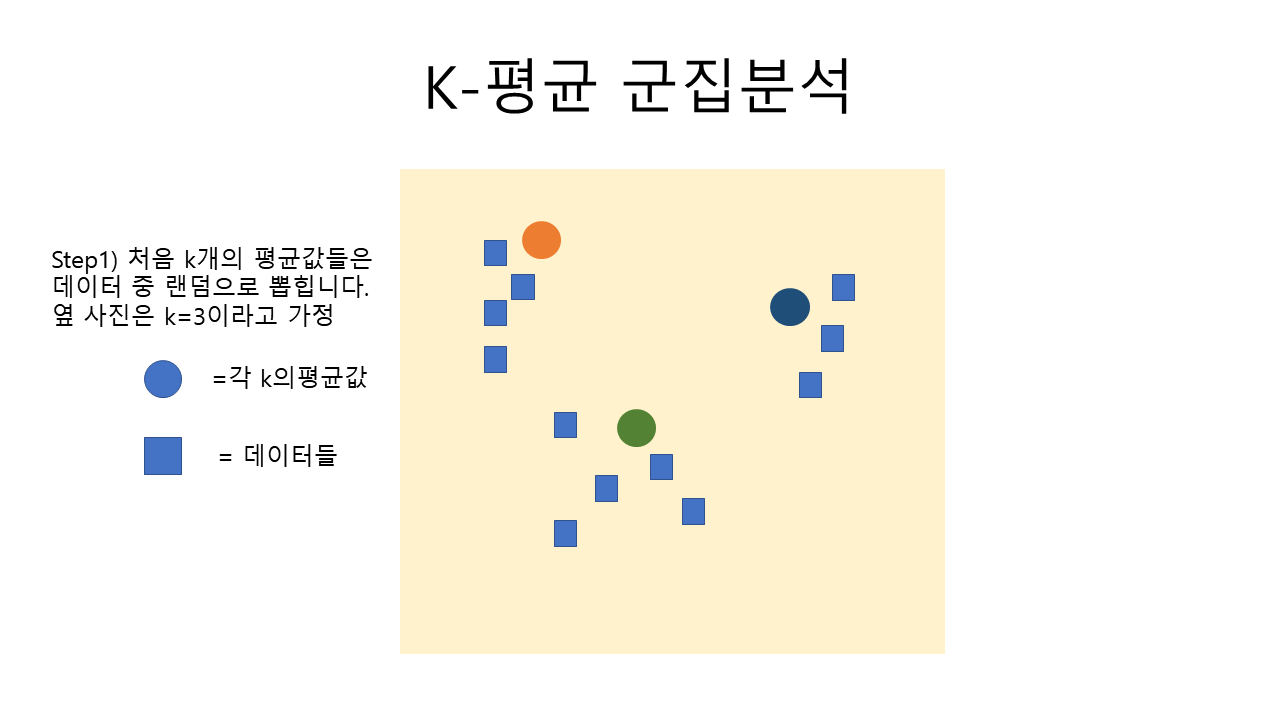

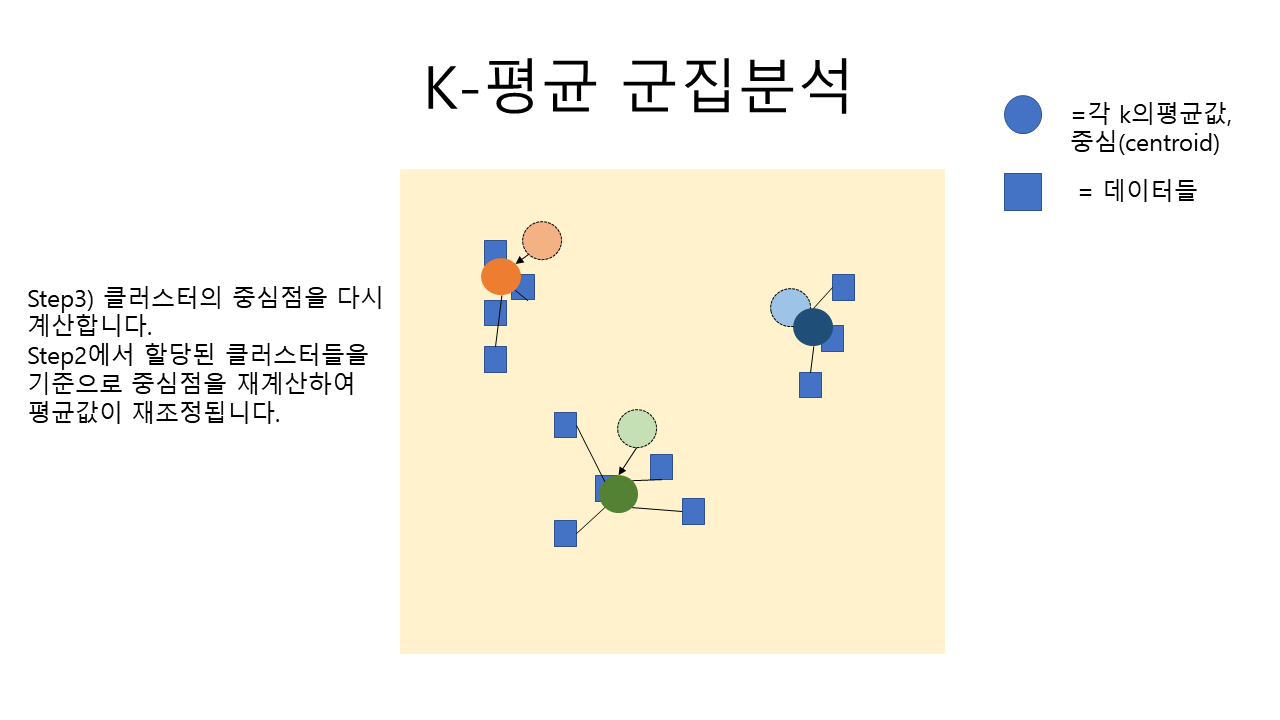

위의 사진을 만들어 준비해 보았는데 이해가 잘 가시나요? ㅎㅎ
이제는 군집분석을 파이썬으로 구현하여 보겠습니다.
우선 데이터를 준비해 주어야 하는데요
저는 네이버 api를 이용해 뉴스 제목, 요약, 링크 등을 크롤링 하여 준비해 보았습니다.
검색어는 '크리스마스' , '쇼미더머니' , 'SK하이닉스' 이렇게 3개의 키워드로 검색된 내용을 데이터프레임으로 만들었습니다.
각각 15기사씩 총 45개의 기사가 있습니다.
데이터 파일 준비
필요한 모듈 설치
sklearn 설치
pip install sklearn
c_konlpy 설치(커스텀 할 수 있는 형태소분석기, 사전에 konlpy설치 후 ckonlpy설치)
git clone https://github.com/lovit/customized_konlpy.git
pip install customized_konlpy
pyclustering 설치
pip install pyclustering
코드
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.cluster import KMeans
from pyclustering.cluster import kmedoids
from ckonlpy.tag import Twitter
twitter = Twitter()
#데이터 불러오기
df = pd.read_csv('clustering_ex.csv')
print(df.head())출력:

준비한 데이터셋을 보면 요약 부분에 <b>태그 등이 남아 있어 제거 한 후 분석을 진행해 보도록 하겠습니다.
# 텍스트 전처리
import re
desc = df['요약']
for i in range(len(desc)):
desc[i] = re.sub('(<b>|</b>|")','',desc[i])
print(desc)출력:
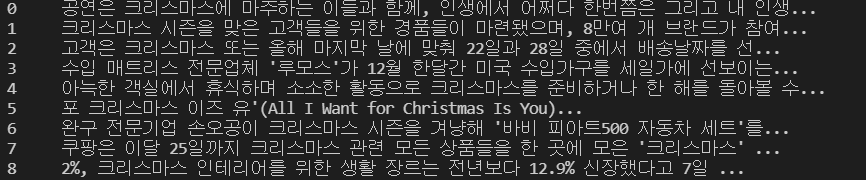
위와 같이 <b> 태그가 깔끔하게 없어진 것을 확인해 볼 수 있습니다.
이번 군집 분석에는 요약부분을 사용하여 분석해보도록 하겠습니다.
각 텍스트의 형태소 분석을 ckonlpy로 진행해줍니다. ckonlpy에서 검색키워드였던 크리스마스, 쇼미더머니, sk하이닉스를 명사로 추가해 줍니다. 다른 명사를 추가하고 싶다면 [] 안에 추가하면 됩니다.
분석 후 명사가 추출된 문장을 띄어쓰기로 구분하여 기사당 한 문장으로 만들어 줍니다.
contents = []
# 형태소 분석, 명사만 추출
twitter.add_dictionary(['크리스마스','쇼미더머니','SK하이닉스'],'Noun')
for i in desc:
contents.append(twitter.nouns(i))
text = [' '.join(contents[i]) for i in range(len(contents))]
print(text)출력:
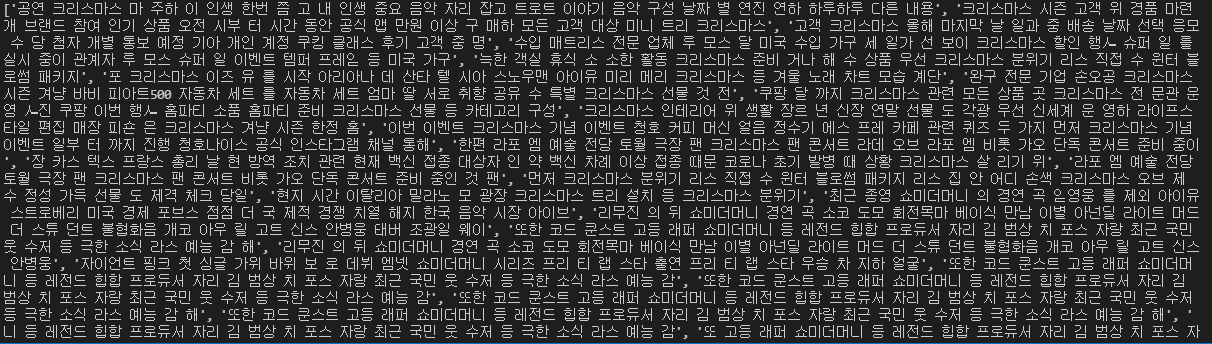
그 후 문장 벡터화를 하여 분석할 수 있는 형태로 텍스트를 바꾸어 줍니다.
#문장 벡터화
vectorize = CountVectorizer()
x = vectorize.fit_transform(text)이렇게 준비가 되었으면 평균 군집 분석을 진행해 줍니다.
데이터 셋이 3개의 키워드로 검색후 만든 파일이기 때문에 k=3으로 설정하여 진행해 보도록 하겠습니다.
######### 평균 군집 분석 ###########
#데이터 프레임 생성 (문장 단어 매트릭스 만들기)
new_df = pd.DataFrame(x.toarray(), columns=vectorize.get_feature_names_out())
# K- 평균 군집 분석
kmeans = KMeans(n_clusters=3).fit(new_df)
print('[K-평균 군집 분석 결과]')
print('###########################################')
print(kmeans.labels_)출력:

아까의 문장들이 k=3이라고 했기 때문에 0,1,2의 3 그룹 중 하나로 배정되었음을 확인할 수 있습니다.
K-대푯값 군집 분석
위의 데이터를 가지고 이번에는 대푯값 군집 분석을 진행하겠습니다.
k-대푯값은 보통 데이터들 중 어느 한 값만 매우 높거나 매우 작을때 평균값이 그 데이터들을 대표하지 못할 때 평균 아닌 다른 방법으로 중심값을 찾아야 할 때 쓰는 방법입니다.
숫자로 예를 들자면
[1,2,3,4,5,6,100] 이라는 데이터가 있을 때
위 숫자들의 평균은 (1+2+3+4+5+6+100)/7 =17.28... 이 되는데, 이 평균이 숫자들의 값을 대표한다고 보기 어렵습니다.
이 때 중앙값인 4를 대푯값으로 정하는 등의 다른 방법이 필요하게 됩니다.
텍스트도 평균 값이 아닌 대푯값을 정하여 군집 분석을 진행해 보도록 하겠습니다.
초기 대푯값으로는 각 키워드의 기사들 중 임의의 기사를 1개씩 선정하여 initial_index_medoids에 세팅해 주었습니다.
######### k-대푯값 군집 분석 ###########
#인스턴스 생성
kmedoids_ins = kmedoids.kmedoids(new_df.values,initial_index_medoids=[4,18,36]) # initial_index는 df행 중 대푯값 행 지정
kmedoids_ins.process()
clusters = kmedoids_ins.get_clusters()
print('###########################################')
print('[K-대푯값 군집 분석 결과]')
print(clusters)출력:

각각 []로 3개의 군집으로 나누어졌음을 확인할 수 있습니다.
이번 텍스트에서는 k대푯값보다 kmeans가 더 분석이 잘 되었네요. 다른 텍스트로도 한 번 진행해 보시고 분석 목적에 맞는 방법을 선택해서 진행하면 됩니다 ㅎㅎ
전체코드
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.cluster import KMeans
from pyclustering.cluster import kmedoids
from ckonlpy.tag import Twitter
twitter = Twitter()
#데이터 불러오기
df = pd.read_csv('clustering_ex.csv')
print(df.head())
# 텍스트 전처리
import re
desc = df['요약']
for i in range(len(desc)):
desc[i] = re.sub('(<b>|</b>|")','',desc[i])
#print(desc)
contents = []
# 형태소 분석, 명사만 추출
twitter.add_dictionary(['크리스마스','쇼미더머니','SK하이닉스'],'Noun')
for i in desc:
contents.append(twitter.nouns(i))
#print(contents)
text = [' '.join(contents[i]) for i in range(len(contents))]
print(text)
#문장 벡터화
vectorize = CountVectorizer()
x = vectorize.fit_transform(text)
######### 평균 군집 분석 ###########
#데이터 프레임 생성 (문장 단어 매트릭스 만들기)
new_df = pd.DataFrame(x.toarray(), columns=vectorize.get_feature_names_out())
# K- 평균 군집 분석
kmeans = KMeans(n_clusters=3).fit(new_df)
print('[K-평균 군집 분석 결과]')
print('###########################################')
print(kmeans.labels_)
######### k-대푯값 군집 분석 ###########
#인스턴스 생성
kmedoids_ins = kmedoids.kmedoids(new_df.values,initial_index_medoids=[4,18,36]) # initial_index는 df행 중 대푯값 행 지정
kmedoids_ins.process()
clusters = kmedoids_ins.get_clusters()
print('###########################################')
print('[K-대푯값 군집 분석 결과]')
print(clusters)
참고자료
- 책- 「잡아라 텍스트 마이닝 with 파이썬」
보너스
PCA (주성분 분석)으로 군집 시각화하기
PCA(Principal component analysis)는 간단하게 말해 고차원의 데이터를 저차원의 데이터로 바꾸는 방법입니다.
여러 변수가 있으면 그 것을 융합해 주성분을 뽑아내어 그것을 새로운 변수로 만들어내는 방법입니다.여기서는 텍스트를 2차원으로 축소 후 결과를 시각화하여 보겠습니다.
#pca(주성분 분석)으로 시각화하기
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
pca = PCA(n_components=2) # 2차원으로 축소
pc = pca.fit_transform(new_df)
p_df = pd.DataFrame(data=pc, columns=['main1', 'main2'])
p_df.index=df['검색어']
plt.scatter(p_df.iloc[kmeans.labels_ == 0,0],
p_df.iloc[kmeans.labels_ == 0,1], s = 10, c = 'red', label = 'clustering1')
plt.scatter(p_df.iloc[kmeans.labels_ == 1,0],
p_df.iloc[kmeans.labels_ == 1,1], s = 10, c = 'blue', label = 'clustering2')
plt.scatter(p_df.iloc[kmeans.labels_ == 2,0],
p_df.iloc[kmeans.labels_ == 2,1], s = 10, c = 'green', label = 'clustering3')
plt.legend()
plt.show()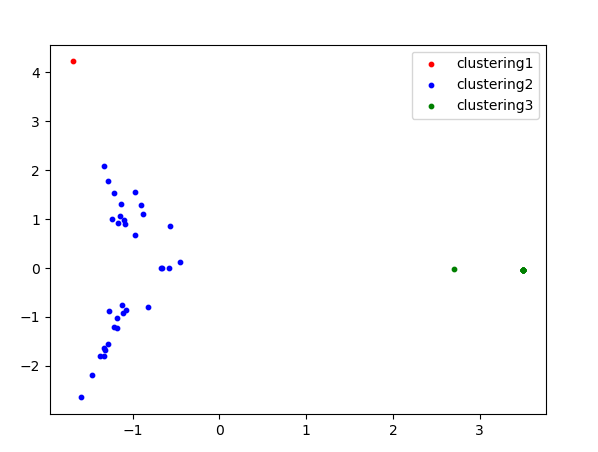
주성분 분석에 대해 더 알아보고 싶은 분은 아래의 링크를 참고해 주세요 :)
https://www.youtube.com/watch?v=FgakZw6K1QQ
전체 코드 파일
'NLP' 카테고리의 다른 글
| [python/NLP] 감성분석(영어)-영화리뷰(tf-idf, word2vec, random forest) 성능평가 (0) | 2022.02.03 |
|---|---|
| [python/NLP] 감정분류(한국어)- 리뷰데이터 학습, 평가, 예측까지 (29) | 2022.01.10 |
| [python] 자연어처리(NLP) - 텍스트 유사도 (0) | 2021.11.26 |
| [python] 자연어처리 - 영어 (nltk, spaCy) (0) | 2021.11.23 |
| [python] 자연어처리(NLP) - Konlpy로 한국어 형태소 분석하기 (0) | 2021.11.22 |