
오늘은 전에 알려드린 오픈 API 사용과 더불어 파이썬으로 크롤러 만드는 방법을 소개하도록 하겠습니다.
네이버 오픈 API의 경우 사용하는 방법을 알면 간편하게 뉴스, 블로그, 카페 등등을 크롤링하여 정보를 수집할 수 있습니다. 하지만 개인당 일일 오픈 API 사용량이 제한되어 있어 빅데이터를 분석 시 그보다 더 큰 데이터를 수집해야 할 때가 있어 오픈 API만으로 필요한 정보를 모두 수집하기는 어렵습니다. 그래서 이번에는 Python으로 네이버 뉴스 크롤링하는 방법을 알아보려고 합니다.

step1. 네이버 뉴스 홈페이지 접속 및 HTML 구조 파악
먼저, 네이버 창에 "코로나"를 검색하여 나오는 뉴스 탭을 확인하도록 합시다.

<위 사진의 URL>
https://search.naver.com/search.naver?where=news&sm=tab_jum&query=코로나
뉴스 크롤링을 위에 보이는 페이지만 하는 것이 아니기 때문에 스크롤 다운을 하여 페이지 1을 클릭하여 줍니다.

<페이지 1을 클릭한 뒤의 URL>
https://search.naver.com/search.naver?where=news&sm=tab_pge&query=코로나&sort=0&photo=0&field=0&pd=0&ds=&de=&cluster_rank=32&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so:r,p:all,a:all&start=1
페이지 1을 클릭하고 URL을 확인하여 보니 아까 검색어만 입력했을 때와는 달리 엄청 길고 복잡한 URL이 나왔습니다.
다음으로 페이지 2,3을 각각 클릭하여 위의 URL과 어떤 다른 점이 있는지 확인하여 보겠습니다.


<페이지 1을 클릭한 뒤의 URL>
https://search.naver.com/search.naver?where=news&sm=tab_pge&
query=코로나
&sort=0&photo=0&field=0&pd=0&ds=&de=&cluster_rank=32&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so:r,p:all,a:all&
start=1
<페이지 2를 클릭한 뒤의 URL>
https://search.naver.com/search.naver?where=news&sm=tab_pge&query=코로나&sort=0&photo=0&field=0&pd=0&ds=&de=&cluster_rank=64&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so:r,p:all,a:all&start=11
<페이지 3을 클릭한 뒤의 URL>
https://search.naver.com/search.naver?where=news&sm=tab_pge&query=코로나&sort=0&photo=0&field=0&pd=0&ds=&de=&cluster_rank=87&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so:r,p:all,a:all&start=21
위와 같이 URL을 모아 보면 공통부분이 있습니다.
검색어를 입력하는 &query=코로나 부분과,
페이지를 입력하는 &start=1(1페이지),11(2페이지),21(3페이지)... 이 부분이 공통적인 요소입니다.
위의 내용을 토대로 중간 부분을 생략하고(생략하여도 검색에 문제는 없습니다.) 공통의 URL을 도출해 내면 아래와 같습니다.
https://search.naver.com/search.naver?where=news&sm=tab_pge&query="검색어"&start="페이지"
이제 파이썬으로 뉴스를 크롤링하는 코드를 만들어 보도록 합시다.
step 2. 파이썬에서 사용할 library(라이브러리들) import
#크롤링시 필요한 라이브러리 불러오기
from bs4 import BeautifulSoup
import requestsstep3. 검색어 입력받기
검색할 키워드와 페이지를 입력받는 코드를 input을 사용하여 작성해 줍니다.
#검색어 입력
search = input("검색할 키워드를 입력해주세요:")
#검색할 페이지 입력
page = int(input("크롤링할 페이지를 입력해주세요. ex)1(숫자만입력):")) # ex)1 =1페이지,2=2페이지...
print("크롤링할 페이지: ",page,"페이지")결괏값:
검색할 키워드를 입력해주세요: (검색 키워드 입력)
크롤링할 페이지를 입력해주세요. ex)1(숫자만입력): 1(숫자 입력)
크롤링할 페이지: 1 페이지
step4. 입력받은 내용에 해당하는 URL 생성하기
페이지 입력을 받을 때 naver에서는 1페이지가 1, 2페이지가 11, 3페이지가 21... 이런 식으로 표현되기 때문에 그것에 맞도록 바꿔주는 코드를 추가하여 url을 생성합니다.
#start수를 1, 11, 21, 31 ...만들어 주는 함수
page_num = 0
if page == 1:
page_num =1
elif page == 0:
page_num =1
else:
page_num = page+9*(page-1)
#url 생성
url = "https://search.naver.com/search.naver?where=news&sm=tab_pge&query=" + search + "&start=" + str(page_num)
print("생성url: ",url)결괏값:
생성url: https://search.naver.com/search.naver?where=news&sm=tab_pge&query=검색키워드&start=페이지숫자
step5. html 불러와서 BeautifulSoup로 해당 페이지 파싱 하기
# ConnectionError방지
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/100.0.48496.75" }
#html불러오기
original_html = requests.get(url, headers=headers)
html = BeautifulSoup(original_html.text, "html.parser")step6. 원하는 값을 추출하기 위한 코드 작성
예시로 코로나를 검색하여 나오는 페이지에서 필요한 내용(제목, 각 기사 url 등)을 찾아보도록 합시다.
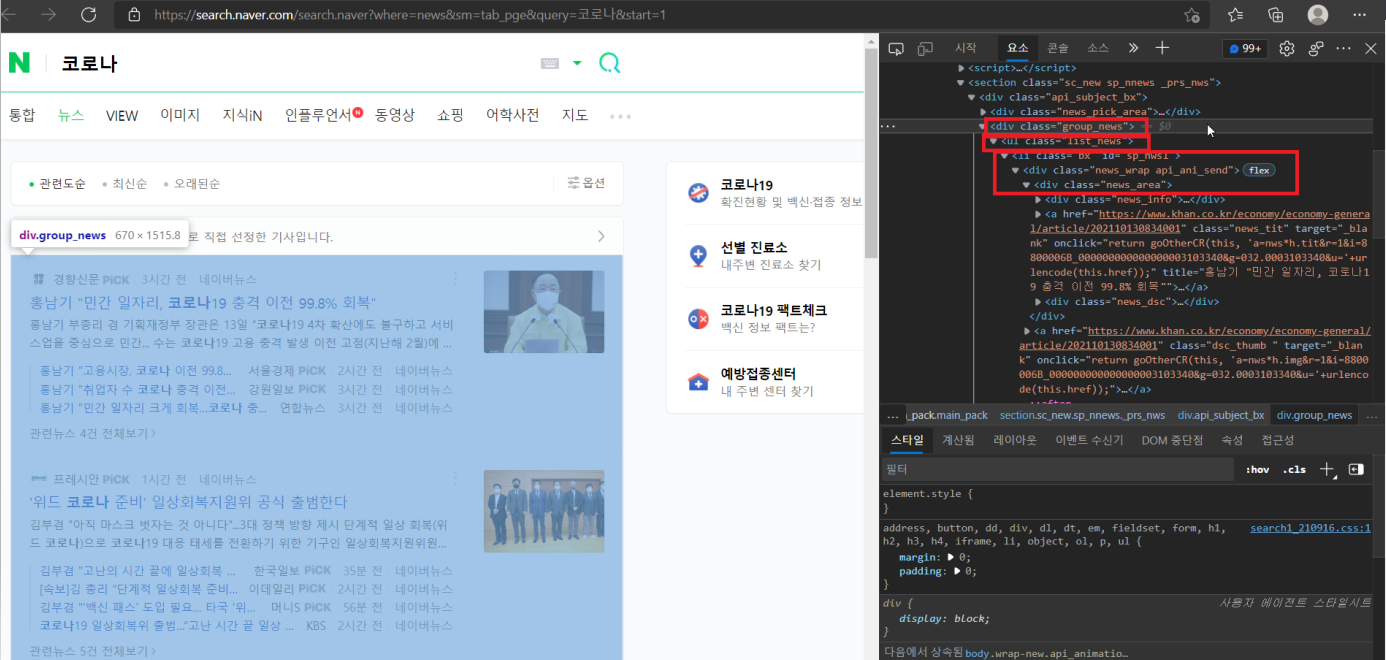
위의 화면에서 F12를 눌러주면 다음과 같이 오른쪽에 개발자 도구가 나오게 됩니다.
여기서 우리가 얻고 싶은 정보는 뉴스가 나와있는 부분이죠. 이 부분에 커서를 대면 빨간 박스와 같이 어디에 위치하여 있는지 표시가 됩니다.
각 기사의 제목과 url은 group_news라는 클래스 이름의 div 안 ul태그의 list_news라는 이름의 class 안 li태그 안의 div의 news_area라는 이름의 class 안의 a태그에 위치하여 있습니다.
이것을 코드로 나타내면 아래와 같이 작성할 수 있습니다.
div.group_news > ul.list_news > li div.news_area > a
.(점) 뒤에는 클래스 이름을, >는 ~안에 있다는 뜻입니다.
만약 html 개발자 도구로 확인할 때 class = 클래스 이름 이 아니라 id = 아이디 이름 이 있으면. 대신 #을 앞에 붙이면 됩니다.
# 검색결과
articles = html.select("div.group_news > ul.list_news > li div.news_area > a")
print(articles)
# 검색된 기사의 갯수
print(len(articles),"개의 기사가 검색됌.")결괏값:
[<a class="news_tit" href="http://www.edaily.co.kr/news/newspath.asp?newsid=01610486629212920" onclick="return goOtherCR(this, 'a=nws*h.tit&r=1&i=880000E7_000000000000000005059762&g=018.0005059762&u='+urlencode(this.href));" target="_blank" title="[속보]코로나19 신규 확진자 1940명…'연휴' 끝, 증가세 계속">[속보]<mark>코로나</mark>19 신규 확진자 1940명…'연휴' 끝, 증가세 계속</a>, <a class="news_tit" href="https://biz.chosun.com/it-science/bio-science/2021/10/14/S4RMV6PZZ5DXRCHU6GYD2354ZE/?utm_source=naver&utm_medium=original&utm_campaign=biz" onclick="return goOtherCR(this, 'a=nws*j.tit&r=3&i=88127058_000000000000000000766474&g=366.0000766474&u='+urlencode(this.href));" target="_blank" title="[단독] 적십자, 제약사에 혈액 헐값 공급… 코로나19로 혈액수급 비상인데">[단독] 적십자, 제약사에 혈액 헐값 공급… <mark>코로나</mark>19로 혈액수급 비상인데</a>, <a class="news_tit" href="https://news.kbs.co.kr/news/view.do?ncd=5300642&ref=A" onclick="return goOtherCR(this, 'a=nws*j.tit&r=4&i=88000114_000000000000000011137195&g=056.0011137195&u='+urlencode(this.href));" target="_blank" title="[속보] 코로나19 신규 확진 1,940명…100일째 네 자릿수">[속보] <mark>코로나</mark>19 신규 확진 1,940명…100일째 네 자릿수</a>, <a class="news_tit" href="https://health.chosun.com/site/data/html_dir/2021/10/14/2021101400675.html" onclick="return goOtherCR(this, 'a=nws*j.tit&r=5&i=88156f6f_000000000000000000045032&g=346.0000045032&u='+urlencode(this.href));" target="_blank" title="[속보] 코로나 신규 확진 1940명… 다시 2000명대 육박">[속보] <mark>코로나</mark> 신규 확진 1940명… 다시 2000명대 육박</a>, <a class="news_tit" href="https://www.khan.co.kr/national/health-welfare/article/202110140939001" onclick="return goOtherCR(this, 'a=nws*j.tit&r=6&i=8800006B_000000000000000003103628&g=032.0003103628&u='+urlencode(this.href));" target="_blank" title="[속보]코로나19 신규 확진 1940명···10명 중 8명 수도권">[속보]<mark>코로나</mark>19 신규 확진 1940명···10명 중 8명 수도권</a>, <a class="news_tit" href="http://www.fnnews.com/news/202110140647114518" onclick="return goOtherCR(this, 'a=nws*j.tit&r=7&i=880000FF_000000000000000004722854&g=014.0004722854&u='+urlencode(this.href));" target="_blank" title="'얀센+모더나 부스터샷' 코로나 백신 효과 가장 좋다">'얀센+모더나 부스터샷' <mark>코로나</mark> 백신 효과 가장 좋다</a>, <a class="news_tit" href="https://www.ytn.co.kr/_ln/0103_202110140934000806" onclick="return goOtherCR(this, 'a=nws*j.tit&r=8&i=880000AF_000000000000000001652079&g=052.0001652079&u='+urlencode(this.href));" target="_blank" title="[속보] 코로나19 신규 환자 1,940명...100일째 네 자릿수">[속보] <mark>코로나</mark>19 신규 환자 1,940명...100일째 네 자릿수</a>, <a class="news_tit" href="https://www.ytn.co.kr/_ln/0102_202110131304564350" onclick="return goOtherCR(this, 'a=nws*h.tit&r=9&i=880000AF_000000000000000001651712&g=052.0001651712&u='+urlencode(this.href));" target="_blank" title="분사형 제품, 살균력 낮고 '코로나 예방' 과장 광고">분사형 제품, 살균력 낮고 '<mark>코로나</mark> 예방' 과장 광고</a>, <a class="news_tit" href="http://www.newsis.com/view/?id=NISX20211014_0001612990&cID=10301&pID=10300" onclick="return goOtherCR(this, 'a=nws*j.tit&r=11&i=88000127_000000000000000010768538&g=003.0010768538&u='+urlencode(this.href));" target="_blank" title="軍 병원 코로나19 의료진에 KF94 마스크 3000장 기부">軍 병원 <mark>코로나</mark>19 의료진에 KF94 마스크 3000장 기부</a>, <a class="news_tit" href="http://news.heraldcorp.com/view.php?ud=20211013000716" onclick="return goOtherCR(this, 'a=nws*h.tit&r=12&i=8800010E_000000000000000001898691&g=016.0001898691&u='+urlencode(this.href));" target="_blank" title="‘위드코로나’ 준비 첫발 내딛다">‘위드<mark>코로나</mark>’ 준비 첫발 내딛다</a>]
10 개의 기사가 검색됌.
이렇게 제목 및 기사 내용을 알 수 있는 url이 추출이 되었습니다. 하지만 아직 지저분해 보입니다.
여기서 제목 및 기사 url만 추출하는 코드를 작성해 보겠습니다.
제목은 title이라는 속성 값을 가진 곳에 작성이 되어 있습니다.
이 부분만 추출하는 코드는 아래와 같습니다.
#뉴스기사 제목 가져오기
news_title = []
for i in articles:
news_title.append(i.attrs['title'])
news_title결괏값:
["[속보]코로나19 신규 확진자 1940명…'연휴' 끝, 증가세 계속", '[단독] 적십자, 제약사에 혈액 헐값 공급… 코로나19로 혈액수급 비상인데', '[속보] 코로나19 신규 확진 1,940명…100일째 네 자릿수', '[속보] 코로나 신규 확진 1940명… 다시 2000명대 육박', '[속보]코로나19 신규 확진 1940명···10명 중 8명 수도권', "'얀센+모더나 부스터샷' 코로나 백신 효과 가장 좋다", '[속보] 코로나19 신규 환자 1,940명...100일째 네 자릿수', "분사형 제품, 살균력 낮고 '코로나 예방' 과장 광고", '軍 병원 코로나19 의료진에 KF94 마스크 3000장 기부', '‘위드코로나’ 준비 첫발 내딛다']
이제 뉴스 기사 url을 가져와 봅시다.
url은 href라는 속성 값에 위치에 있습니다.
#뉴스기사 URL 가져오기
news_url = []
for i in articles:
news_url.append(i.attrs['href'])
news_url결괏값:
['http://www.edaily.co.kr/news/newspath.asp?newsid=01610486629212920', 'https://biz.chosun.com/it-science/bio-science/2021/10/14/S4RMV6PZZ5DXRCHU6GYD2354ZE/?utm_source=naver&utm_medium=original&utm_campaign=biz', 'https://news.kbs.co.kr/news/view.do?ncd=5300642&ref=A', 'https://health.chosun.com/site/data/html_dir/2021/10/14/2021101400675.html', 'https://www.khan.co.kr/national/health-welfare/article/202110140939001', 'http://www.fnnews.com/news/202110140647114518', 'https://www.ytn.co.kr/_ln/0103_202110140934000806', 'https://www.ytn.co.kr/_ln/0102_202110131304564350', 'http://www.newsis.com/view/?id=NISX20211014_0001612990&cID=10301&pID=10300', 'http://news.heraldcorp.com/view.php?ud=20211013000716']
step7. 각 기사의 내용을 크롤링하기
각 기사의 내용을 크롤링하려면 step6에서와 같이 각각의 기사 링크를 타고 들어가 f12를 누르고 개발자 도구를 통해 html의 구조 및 필요한 내용이 어디에 위치해 있는지를 확인하여야 합니다.
하지만 각각의 언론사는 다 다른 html 구조를 가지고 있기 때문에 정확하게 크롤링하려면 번거롭고 시간이 많이 듭니다.
보통 기사는 p 태그에 본문 내용이 있기 때문에 p태그에 있는 모든 내용을 가져오는 코드를 작성해 보도록 하겠습니다.
#뉴스기사 내용 크롤링하기
contents = []
for i in news_url:
#각 기사 html get하기
news = requests.get(i)
news_html = BeautifulSoup(news.text,"html.parser")
#기사 내용 가져오기 (p태그의 내용 모두 가져오기)
contents.append(news_html.find_all('p'))
contents결괏값:
p class="tit">이시간 <span>핫 뉴스</span></p>, <p class="tit">오늘의 헤드라인</p>, <p class="tit"><a href="/view?id=NISX20211014_0001613089">"확진 1940명…100일째 네자리 연휴 끝난 후 3일 연속 증가세</a></p>, <p class="subTit"></p>, <p class="txt"><a href="/view?id=NISX20211014_0001613089">코로나19 신규 확진자 수가 1940명으로 집계돼 다시 2000명대에 육박했다. 신규 확진자 수는 최근 3일 연속 증가세인데, 정부는 단계적 일상회복 전 마지막 사회적 거리두기 단계 조정안을 오는 15일 발표할 예정이다. 질병관리청 중앙방역대책본부(방대본)에 따르면 14일 0시 기준 누적 확진자는 전날보다 1940명 증가한 33만7679명이다.</a></p>, <p class="tit"><a href="/view?id=NISX20211014_0001612865">"김만배, 구속심사 출석…'700억대' 뇌물 등 혐의</a></p>, <p class="tit"><a href="/view?id=NISX20211014_0001612930">"李 34%·尹 33.7%…이낙연 지지층, 尹으로 이탈</a></p>, <p class="tit"><a href="/view?id=NISX20211013_0001612719">"[단독]음저협, 저작권료 41억 받고도 미분배</a></p>, <p class="tit"><a href="/view?id=NISX20211014_0001613023">"日언론 "기시다, 이르면 오늘 文대통령과 통화"</a></p>, <p class="tit"><a href="/view?id=NISX20211014_0001613075">"尹 "당 없어지는 게 낫다"에 劉·洪 "못된 버르장머리"</a></p>, <p class="tit">많이 본 기사</p>...(중략)
기사의 모든 본문을 가지고 있지만 본문 뿐만이 아니라 p태그의 모든 내용이 크롤링 되기 때문에 크롤링 후 전처리가 필수적으로 진행이 되어야 합니다. 추후 전처리에 관련해서도 포스팅 할 예정입니다.
전체 코드
#크롤링시 필요한 라이브러리 불러오기
from bs4 import BeautifulSoup
import requests
#검색어 입력
search = input("검색할 키워드를 입력해주세요:")
#검색할 페이지 입력
page = int(input("크롤링할 페이지를 입력해주세요. ex)1(숫자만입력):")) # ex)1 =1페이지,2=2페이지...
print("크롤링할 페이지: ",page,"페이지")
#start수를 1, 11, 21, 31 ...만들어 주는 함수
page_num = 0
if page == 1:
page_num =1
elif page == 0:
page_num =1
else:
page_num = page+9*(page-1)
#url 생성
url = "https://search.naver.com/search.naver?where=news&sm=tab_pge&query=" + search + "&start=" + str(page_num)
print("생성url: ",url)
# ConnectionError방지
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/100.0.48496.75" }
#html불러오기
original_html = requests.get(url, headers=headers)
html = BeautifulSoup(original_html.text, "html.parser")
# 검색결과
articles = html.select("div.group_news > ul.list_news > li div.news_area > a")
print(articles)
# 검색된 기사의 갯수
print(len(articles),"개의 기사가 검색됌.")
#뉴스기사 제목 가져오기
news_title = []
for i in articles:
news_title.append(i.attrs['title'])
news_title
#뉴스기사 URL 가져오기
news_url = []
for i in articles:
news_url.append(i.attrs['href'])
news_url
#뉴스기사 내용 크롤링하기
contents = []
for i in news_url:
#각 기사 html get하기
news = requests.get(i,headers=headers)
news_html = BeautifulSoup(news.text,"html.parser")
#기사 내용 가져오기 (p태그의 내용 모두 가져오기)
contents.append(news_html.find_all('p'))
contents코드 파일
마무리
오늘의 포스팅은 네이버 뉴스를 파이썬으로 크롤링하는 코드를 만들어 보았습니다. 이번에는 1페이지씩 크롤링하는 코드를 작성하였는데요, 다음 포스팅에는 한 번에 여러 페이지를 크롤링하는 코드를 만들어 보도록 하겠습니다. :-)
+ 최신 버전을 확인하고 싶다면??
https://wonhwa.tistory.com/46?category=996518
[python] 원하는 검색어로 네이버 뉴스 기사 제목 및 내용만 크롤링하기
안녕하세요! 크롤링 포스팅을 오랜만에 진행하네요~ 이번에는 네이버 뉴스 검색 결과중 네이버 뉴스에 기사가 있는 링크들만 가져와 크롤링을 진행해 보도록 하겠습니다. 지난 크롤러에서 아쉬
wonhwa.tistory.com
위의 게시물을 방문해 주세요:)
+2022.4.6 connection error 수정
'Crawling' 카테고리의 다른 글
| [python] 원하는 검색어로 네이버 뉴스 크롤링하기(2) (5) | 2021.10.22 |
|---|---|
| [python] Naver 오픈API를 이용하여 원하는 검색어로 블로그 크롤링 하기(제목+본문) (28) | 2021.10.21 |
| [Python] 공공데이터 포털의 OPEN API 사용 방법(2) (69) | 2021.10.14 |
| [python] Naver 오픈API를 이용하여 크롤링 하기(뉴스/블로그/카페) (8) | 2021.10.05 |
| [Python] 공공데이터 포털의 OPEN API 사용 방법 (0) | 2021.09.29 |