
안녕하세요.
오늘은 LDA(Latent Dirichlet Allocation)에 대해 알아보도록 하겠습니다.
LDA는 자연어처리에서 토픽 모델링을 할 때 많이 활용되는 방법입니다.
토픽 모델링이란?
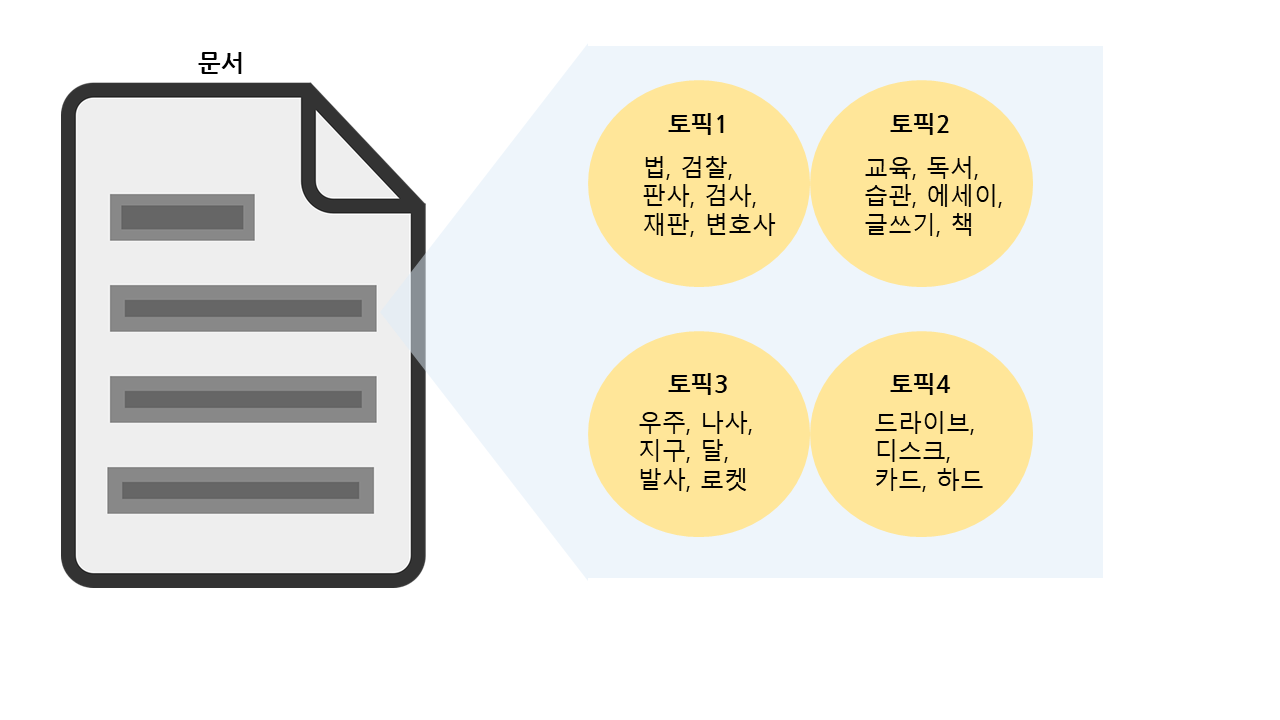
토픽 모델링은 어떠한 문서가 있다면 그 문서의 주제가 무엇일지에 대한 분석을 가능하게 하는 방법입니다.
보통 단어의 집합으로 토픽을 표현하고 이에 대한 토픽이 무엇일지를 파악할 수 있는데,
가령, '눈' 이라는 단어가 있을 때,
'눈', '얼굴' , '시력' 등의 단어가 같이 있으면 신체 부위인 '눈'을 말하는 것인지 알 수 있고
'눈', '겨울', '흰색' 등의 단어 집합이 있으면 하늘에서 내리는 '눈'이라는 것을 알 수 있습니다.
또한 이렇게 단어들로 토픽을 뽑아 보면 각 토픽의 단어 집합을 통해 해당 문서의 주제가 무엇일 지 유추할 수 있습니다.
LDA(Latent Dirichlet Allocation): 잠재 디리클레 할당
처음에 언급했듯이 LDA는 토픽 모델링에서 많이 사용됩니다.
LDA는 문서 작성 시 몇 개의 토픽을 미리 정하고 문서가 작성될 때 이 토픽과 관련된 단어들을 사용한다고 가정합니다.
LDA 모형의 구조는 아래와 같습니다.

1. α: 디리클레 분포의 매개변수(LDA 하이퍼 파라미터)
2. M: 문서의 수
3. θ: 문서의 토픽 분포(디리클레 분포를 따름)
※ 디리클레 분포: 연속확률분포 중 하나.
k 차원의 실수 벡터 중 벡터의 요소가 양수이며 모든 요소를 더한 값이 1인 경우 실수 벡터에서 각 벡터 값이 양수이고 모든 값을 더하면 1이 되는 경우에 대해 확률값이 정의되는 분포(출처:위키피디아-디리클레 분포)
예시: 문서에 토픽 3개 선정시 토픽의 비중을 [0.4, 0.4, 0.2]로 할당한다. 이 값을 다 더하면 1이 된다.
4. β: 각 토픽의 단어 분포에 관여하는 매개변수( LDA 하이퍼 파라미터)
5. Z: 문서에 있는 토픽
6. W: Z에 있는 단어들
7. N: 문서에 나타난 단어들의 빈도
이에 대해 간단히 설명하자면
LDA는 주어진 문서에 사용된 단어(W)들의 빈도(N)를 측정하고, 이로부터 문서의 토픽분포(θ)와 각 토픽의 단어분포를 추정합니다.

또한 LDA를 실행할 때, 토픽의 개수 k와 위에서 언급한 α, β 를 사용자가 설정해주어야 합니다.
위의 설정값들을 어떻게 설정하느냐에 따라 LDA 토픽 모델링의 성능을 높일 수 있습니다.
이때, 적절한 값을 판단하기 위해 혼란도(perplexity)와 토픽 응집도(topic coherence)를 이용합니다.
LDA 모형 평가
- 혼란도(perplexity): 사용자가 추정한 LDA모형이 실제 문서 집합과 비교했을 때 얼마나 유사한지 알아보는 척도입니다.
혼란도는 값이 작을수록 문서집합을 잘 반영하고 있다고 해석할 수 있습니다.
- 토픽 응집도(topic coherence): 각 토픽에 속한 단어들 중 높은 비중을 가진 단어들이 의미적으로 서로 유사한지를 나타냅니다.
토픽 응집도는 혼란도와는 반대로, 값이 클수록 좋습니다.(어떤 응집도 방법을 선택하느냐에 따라 차이는 있을 수 있습니다.)
성능 평가시 주의할 점
사용자가 모델링한 LDA 모형을 평가 시 가장 중요한 것은
혼란도 또는 토픽 응집도 수치에만 너무 집착하지 않는 것입니다.
LDA를 실행 후 사람의 눈으로 봤을 때 토픽과 그 단어의 구성이 자연스러운 것이 가장 좋은 모델입니다.
때문에 최종적으로 토픽 수 결정 시에는 척도 값만 보고 토픽 수를 결정하기보다,
최적값 근처의 값들을 추가로 선택 후
그 값들에 대해 모델링을 해보고 결과들을 사용자가 본인의 눈으로 직접 비교하여 최종 값을 선택하는 것이 좋습니다.
참고자료
1. 파이썬 텍스트 마이닝 완벽 가이드(책)
'NLP' 카테고리의 다른 글
| [NLP] 한국어 토픽 모델링 - LDA 활용방법(sklearn) (2) | 2023.02.07 |
|---|---|
| [NLP] 한국어 토픽 모델링 - LDA 활용방법(gensim) (0) | 2023.01.12 |
| [NLP/영어] 사전학습된 BERT 모형의 기본 사용법 : pipeline() (0) | 2022.12.15 |
| [NLP]사전학습모델 - BERT(버트)란? (0) | 2022.12.13 |
| [NLP] 감성분석이란? (2) | 2022.09.07 |