
사전학습모델이란?
사전학습모델(pre-training model)은 어떠한 새로운 문제를 해결하려 모델을 만들어 학습시킬 때,
기존의 다른 문제를 해결하는 데 사용한 모델의 가중치들을 활용하여 구성하는 모델을 말합니다.
예를 들어,
전에 감성 분석 모델을 미리 만들어 놓았었고 이번에는 텍스트 유사도 예측 모델을 만든다고 할 때,
미리 만들어 놓은 감정 분석 문제 모델의 가중치를 텍스트 유사도 예측 모델의 가중치로 활용하는 것이라 할 수 있습니다.
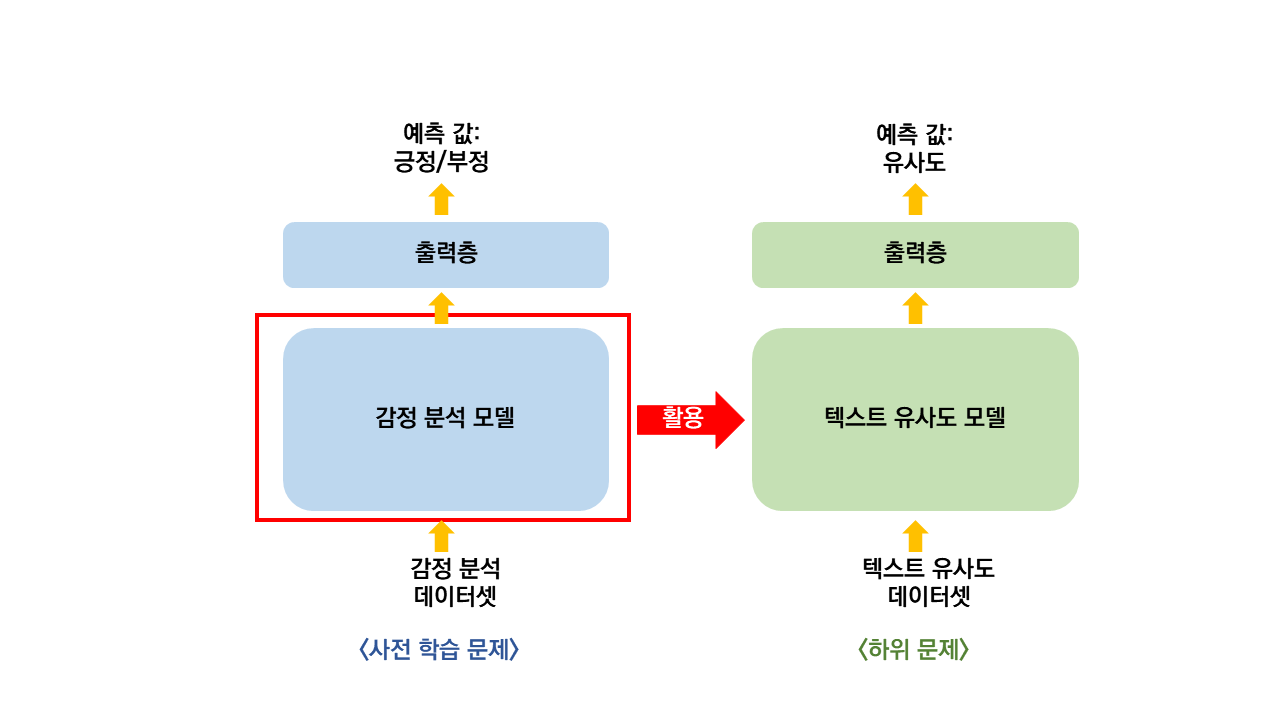
즉, 감성 분석 문제를 학습하면서 얻은 정보를 유사도 문제를 학습하는 데 활용하는 방식이라고 할 수 있습니다.
이때, 감정 분석 문제는 사전 학습 문제(pre-train-ask)가 되고,
텍스트 유사도 문제는 하위 문제(downstream task)가 됩니다.
자주 사용하는 사전학습 문제: 언어 모델
위에서 사전학습 모델과 그 예를 알아보았는데
실제 연구에서는 보통 사전 학습 문제로 '언어 모델(language model)'을 사용합니다.
언어 모델(language model)이란?
언어모델은 문장 또는 단어 나열에 확률을 부여하는 모델입니다.
간단히 말해 특정 단어가 있을 때 그 다음 단어 또는 다른 위치에 있는 단어가 어떤 단어일지를 예측하는 모델입니다.
예를 들어,
"나는 추워서 롱패딩을 입었다." 이 문장이 있을 때, 마지막 부분인 "입었다."를 모델이 예측하며 학습합니다.
또한 "나는 너무 졸려서 잔다." 와 "나는 너무 졸려서 일어난다." 의 두 문장이 있을 때,
언어 모델은 더 자연스러운 문장인 "나는 너무 졸려서 잔다." 라는 문장에 더 높은 확률을 할당합니다.
여기서 자연스럽다는 의미는 일반적으로 더 많이 사용된다는 의미로,
이렇듯 언어 모델은 언어에 대한 이해를 높여주는 모델이라고 할 수 있습니다.
또한 정답 라벨이 필요 없는 비지도 학습이므로 지도 학습에 비해 전처리 시간이 줄어듭니다.
BERT란?
BERT(Bidirectional Encoder Representation from Transformers)는
2018년도에 나온
<<BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding>>
라는 논문에서 제안된 사전학습모델입니다.
BERT(버트)에서 활용하는 사전 학습 문제는 위에서 언급한 언어 모델(language model)이며,
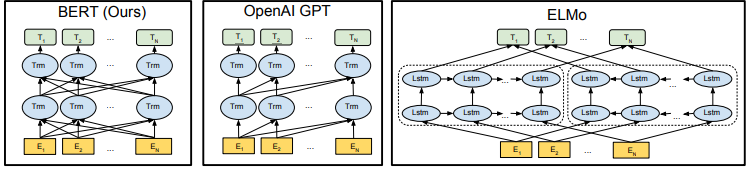
트랜스포머에서 인코더 부분만 사용한 모형입니다.
인코더의 특징으로 양방향(bidirectional) 셀프 어텐션을 구현하고 있다는 것이 있습니다.
이는 다른 사전학습 모델(GPT, ELMo)등과 비교했을 때 확연히 다른 차이점입니다.
BERT의 학습
BERT 의 학습으로,
1. 사전학습
2. 미세조정학습
이렇게 두 단계가 있습니다.
여기서 사전학습은 비지도학습이고, 미세조정학습은 해결해야 하는 문제에 대한 지도학습입니다.
BERT의 사전학습
BERT는 두 문제를 사전 학습합니다.
두 문제는 아래와 같습니다.
1.1 마스크 언어 모델
- 마스크 언어 모델: 주어진 문장에서 일부 단어를 마스킹(가림) 처리하여 가려진 단어가 무엇인지 예측하는 학습
여기서, BERT는 마스킹된 앞 뒤 단어 (양 방향)를 모두 사용해서 가려진 단어를 예측한다.
성능 향상을 위해 마스킹 할 단어의 80% 는 [MASK]라는 토큰을 사용하고,
10%는 다른 단어로 바꾸고, 마지막 10%는 단어 그대로 놔둔다.
예) 원래 문장: 분석은 전처리 과정이 매우 중요하다.
마스킹 후 문장: 분석은 [MASK] 과정이 오늘 중요하다.
1.2 다음 문장 예측(next sentence prediction)
- 다음 문장 예측: 두 개의 주어진 문장에서 이 두 문장이 이어진 문장인지 아닌지를 분류하는 학습
이를 통해 문장 간의 관계를 학습할 수 있다.
데이터 셋 구성 시 50%는 이어진 문장, 나머지 50%는 이어지지 않은 문장으로 구성한다.
앞 문장에는 [CLS]라는 토큰을 넣고, 두번째 문장 앞과 맨 끝에는 [SEP] 토큰을 넣어 문장을 구분할 수 있도록 처리한다.
예) [CLS] 분석은 [MASK] 과정이 [MASK] 중요하다. [SEP] 그래서 [MASK] 시간이 많이 걸린다.[SEP]
위의 예시에서 모델은 가려진 단어들과 두 문장이 이어졌는지 아닌지를 예측한다.
BERT의 미세조정학습
미세조정학습은 사전학습으로 BERT의 언어에 대한 이해가 학습되고,
이를 통해 최종적으로 해결하여야 하는 하위문제(예: 문서 분류, 유사도 측정 등)를 풀기 위한 학습을 말합니다.
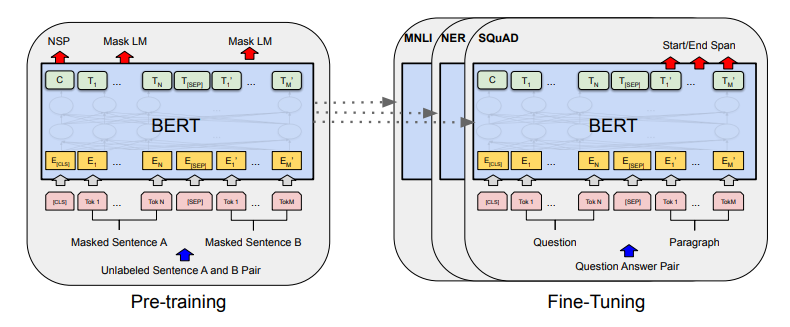
미세조정 학습을 하고 나면,
사전학습으로 만들어진 가중치들이 하위 문제에 맞게 세밀하게 조정되어 최종적인 예측 값을 반환합니다.
참고자료
1. 텐서플로2와 머신러닝으로 시작하는 자연어처리(위키북스)
2. 파이썬 텍스트 마이닝 완벽 가이드(위키북스)
3. BERT논문 - https://arxiv.org/pdf/1810.04805.pdf
마무리
이번에는 간단하게 사전학습 모델이 무엇인지, BERT가 무엇인지 알아보았습니다.
BERT를 개인이 직접 사전학습하려면 많은 비용과 시간이 들어갈 것입니다.
그래도 개인이 BERT를 사용할 수 있는 방법이 있습니다.
바로 사전학습된 모형을 무료로 제공하는 웹사이트들을 활용하는 것입니다.
다음 포스팅에서는 허깅페이스(Hugging Face)에서
미리 사전학습된 BERT를 사용하는 방법을 같이 알아보도록 하겠습니다.
'NLP' 카테고리의 다른 글
| [python]토픽 모델링 알고리즘-LDA(잠재 디리클레 할당)란? (0) | 2022.12.27 |
|---|---|
| [NLP/영어] 사전학습된 BERT 모형의 기본 사용법 : pipeline() (0) | 2022.12.15 |
| [NLP] 감성분석이란? (2) | 2022.09.07 |
| Windows에 MeCab 설치하기(feat. python, R) (4) | 2022.04.01 |
| [python/NLP] transformer 모델(attention 기법)을 이용하여 향상된 성능의 챗봇 만들기 (0) | 2022.02.03 |