
안녕하세요.
저번 포스팅에 이어서 pandas를 활용하여 날짜&시간 데이터를 다루는 방법 2편 시작하도록 하겠습니다!
데이터 준비
이번에 사용할 데이터는 국가 별 기대수명 데이터 입니다!
15개의 각 나라에 대한 년도별 기대수명이 있는 데이터 입니다.
Kaggle에서 다운받을 수 있으며 아래의 링크에서 찾을 수 있습니다.
https://www.kaggle.com/datasets/brendan45774/countries-life-expectancy
Countries Life Expectancy
Countries Life Expectancy
www.kaggle.com

Download 버튼을 눌러서 다운받으실 수 있습니다 ㅎㅎ
CSV 파일 불러오기 및 데이터 확인
import pandas as pd
df = pd.read_csv("Life expectancy.csv")
df
데이터를 확인해 보면 3253행 x3열 이며 각 컬럼은 나라(Entity), 년도(Year), 기대수명(Life expectancy)을 의미합니다.
여기서 시간데이터인 Year 컬럼을 to_datetime으로 형변환을 해 주도록 하겠습니다.
날짜형 데이터로 변환
저번 1편에서 확인했듯이 pd.to_datetime를 사용하여 형변환을 해주고 데이터 타입을 확인하여 보면 아래와 같습니다.
# year을 데이터형으로 변환
df['Year'] = pd.to_datetime(df['Year'],format = '%Y')
df.dtypes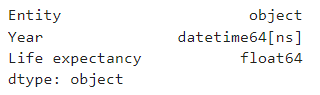
의도했던 대로 Year 컬럼이 datetime형으로 바뀌었습니다.

데이터도 다시 확인하여 보면 날짜형으로 바뀌었음을 알 수 있습니다.
날짜, 시간데이터의 증감 - timedelta
이 시간데이터를 가지고 날짜, 시간데이터의 증감을 해 보도록 하겠습니다.
datetime의 timedelta를 이용하면 날짜별, 시간별로 데이터를 더할 수 있습니다.
# 일자 더하기
날짜데이터 + datetime.timedelta(days = 더할 일수)
# 시간 더하기
날짜데이터 + datetime.timedelta(hours = 더할 시간)
# 분 더하기
날짜데이터 + datetime.timedelta(minutes = 더할 분)
# 초 더하기
날짜데이터 + datetime.timedelta(seconds = 더할 초)
아래 예제에서는 각각 1일, 1시간, 1분, 1초를 Year 열에 더해 보았습니다.
import datetime
# 시간 더하기
#일
addDay = df['Year']+ datetime.timedelta(days=1)
#시
addHour = df['Year']+ datetime.timedelta(hours=1)
#분
addMinute = df['Year']+ datetime.timedelta(minutes=1)
#초
addSecond = df['Year']+ datetime.timedelta(seconds=1)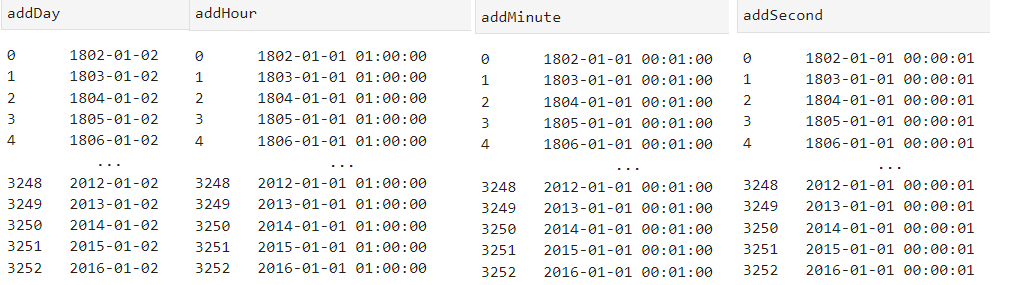
각각 데이터가 잘 더해진 것을 확인할 수 있습니다.
Pivot_table을 사용하여 행, 열 바꾸기
이 데이터를 보면 나라별로 데이터가 나누어져 있습니다.
이 데이터를 Year을 인덱스로 하여 행으로 바꿔주고 나라를 컬럼으로, 기대수명을 값으로 하여
데이터 프레임을 만들어 보도록 하겠습니다.
이 때 pivot_table을 사용하여 값을 바꿀 수 있습니다.
pivot_table에 대한 자세한 내용은 전에 포스팅을 참고해 주세요.
https://wonhwa.tistory.com/27?category=996516
[python] pandas(판다스) - groupby, pivot_table, melt
Pandas는 데이터 분석을 할 때 필수적으로 사용하는 파이썬 라이브러리입니다. 오늘은 유용하게 쓰일 수 있는 판다스의 메소드 몇 가지를 간단히 알아보도록 하겠습니다. Groupby 그룹바이 pandas.grou
wonhwa.tistory.com
# 피벗으로 행렬 전환
# index = Year
# columns = Entity
# values = Life expectancy
df_pivot = df.pivot_table(
index='Year',
columns='Entity',
values='Life expectancy')
df_pivot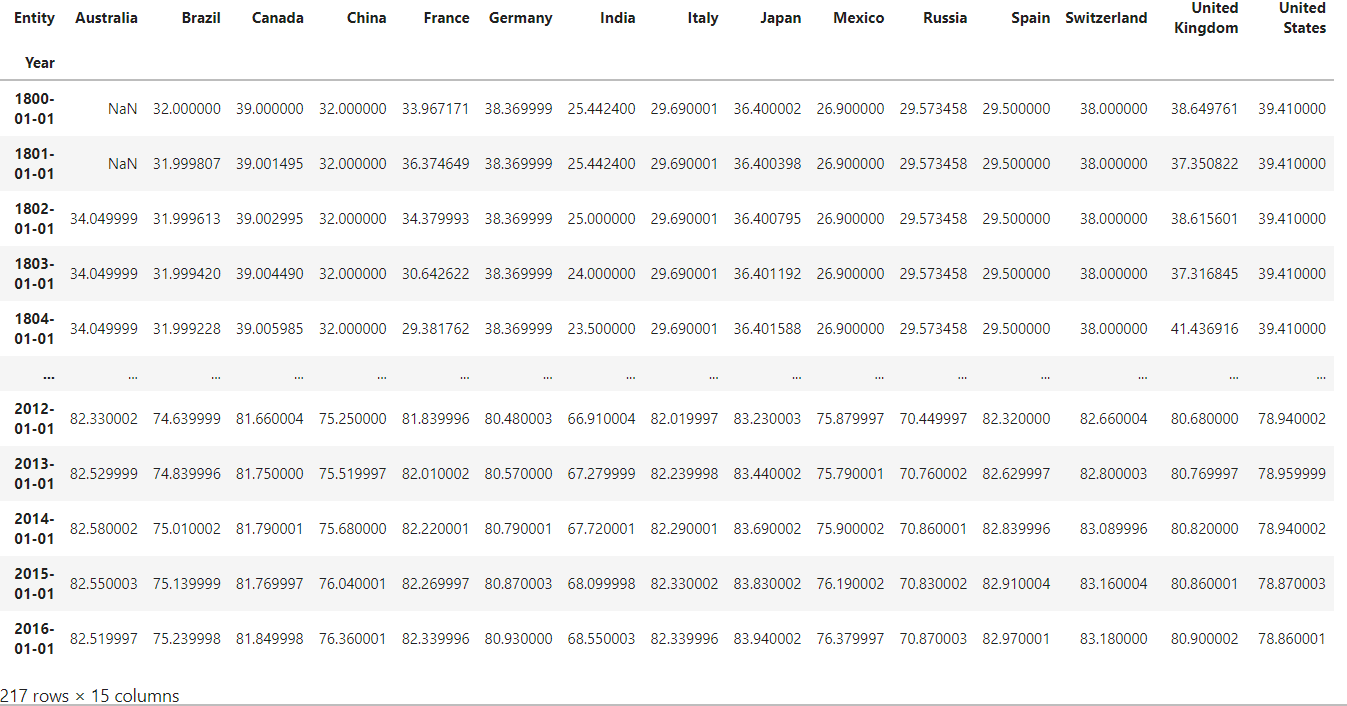
이렇게 원하는 모양의 데이터프레임이 만들어졌습니다 :)
이제 이 csv 파일을 저장 후 다음 예제는 이 파일을 사용해 보도록 하겠습니다.
# 피벗한 테이블 csv 저장
df_pivot.to_csv('LifeExp_pivot.csv')
df_pivot = pd.read_csv('LifeExp_pivot.csv')
날짜 데이터를 분류하기
이 데이터는 1800년부터 2016년도까지의 총 217년의 데이터가 있는데
각 세기별로 나누어 데이터를 확인해 보도록 하겠습니다.
1세기 = 100년 이며
이데이터는 18C~21C까지의 데이터 이므로 컬럼을 하나 만들어 각 세기를 입력해 주도록 하겠습니다.
년도를 세기별로 변환하는 방법으로
1. 함수를 만들기
2. apply함수를 이용한 계산 및 Categorical을 이용하여 범주형으로 입력
이렇게 2가지를 거쳐 쉽게 분류할 수 있습니다.
먼저 아래와 같이 함수를 만들어 각 년도별 해당 세기를 return 하는 함수를 만들어 줍니다.
예를 들어 19C는 1801년~1900년 까지 입니다.
if , elif, else 를 이용하여 만들 수 있습니다.
# 세기별로 나누기
# 18,19,20,21세기
#예) 19세기: 1801-01-01 ~ 1900-12-31
# 년도를 세기별로 변환하는 함수
def to_century(year_num):
century = '21C'
if year_num == 1800:
century = '18C'
elif 1801 <= year_num <= 1900:
century = '19C'
elif 1901 <= year_num <= 2000:
century = '20C'
return century그 뒤 Year을 기준으로 세기가 정해지기 때문에 Year컬럼을 datetime형으로 바꿔준 후,
dt를 사용하여 year에 접근하여 그 값에대해 apply로 위에서 만든 to_century 함수를 적용해 줍니다.
그 값은 'Century'라는 컬럼에 새로 할당해 주면 완성됩니다.
#Year을 datetime64[ns]형변환 하기
df_pivot['Year'] = pd.to_datetime(df_pivot['Year'],format='%Y-%m-%d')
#세기별로 변환하기
df_pivot['Century'] = pd.Categorical(
df_pivot['Year'].dt.year.apply(to_century),
categories=['18C','19C','20C','21C'])
df_pivot
맨 끝에 Century 열이 추가 된 것을 확인할 수 있습니다.
시각화
이제 이것을 가지고 세기별 국가들의 기대수명을 확인해 보도록 하겠습니다.
국가는 Austrailia(호주), Brazil(브라질), Canada(캐나다), China(중국), France(프랑스), Germany(독일), India(인도), Italy(이탈리아), Japan(일본), Mexico(멕시코), Russia(러시아), Spain(스페인), Switzerland(스위스), United Kingdom(영국), United States(미국) 이렇게 15개국이 있습니다.
그리고 데이터에서 세기별로 데이터를 나누고 그 데이터를 시각화해주도록 하겠습니다.
데이터는 100년의 데이터가 다 있는 19C, 20C만 해보도록 하겠습니다.
matplotlib을 사용하여 그래프를 그리고, 국가 수 가 많으므로 범례를 추가해 주고 색도 각자 다른 색으로 추가해 주겠습니다.
matplotlib에서 제공하는 컬러맵은 아래의 링크에서 확인이 가능합니다.
https://matplotlib.org/stable/tutorials/colors/colormaps.html
Choosing Colormaps in Matplotlib — Matplotlib 3.6.0 documentation
Note Click here to download the full example code Choosing Colormaps in Matplotlib Matplotlib has a number of built-in colormaps accessible via matplotlib.colormaps. There are also external libraries that have many extra colormaps, which can be viewed in t
matplotlib.org
import matplotlib.pyplot as plt
import numpy as np
#19C 수명 변화 시각화
Century19 = df_pivot[df_pivot['Century'] == '19C']
fig1 = plt.figure(figsize=(15,15))
ax1 = fig1.add_subplot(111)
ax1.plot(Century19['Year'], Century19.iloc[:,1:16])
colormap = plt.cm.tab20b #컬러맵
colors = [colormap(i) for i in np.linspace(0, 1,len(ax1.lines))]
for i,j in enumerate(ax1.lines):
j.set_color(colors[i])
plt.legend(Century19.columns[1:16])
plt.show()
이 각 나라별로 수명 변동이 있는데 그 중에서 러시아의 수명이 눈에 띕니다.
1848년정도에 기대수명이 18세 정도까지 떨어졌는데
이때 왜 그런지 찾아보니
1848때 헝가리 혁명이 있었고, 그 때 러시아가 많은 사람을 파병했다고 합니다.
이렇게 기대수명이 급감한 년도를 살펴보면 역사적인 사건들과 관련있는 것을 확인할 수 있습니다.
이번에는 20C의 기대수명을 시각화 해보도록 하겠습니다.
#20C 수명 변화 시각화
Century20 = df_pivot[df_pivot['Century'] == '20C']
fig2 = plt.figure(figsize=(15,15))
ax2 = fig2.add_subplot(111)
ax2.plot(Century20['Year'], Century20.iloc[:,1:16])
colormap = plt.cm.tab20b #컬러맵
colors = [colormap(i) for i in np.linspace(0, 1,len(ax2.lines))]
for i,j in enumerate(ax2.lines):
j.set_color(colors[i])
plt.legend(Century20.columns[1:16])
plt.show()
20세기는 1,2차 세계대전이 있었던 만큼 그 시기에 대부분 국가의 기대수명이 낮음을 확인할 수 있습니다.

1914~1918년도에는 제 1차 세계대전이, 1939 ~ 1945년 까지는 2차 세계대전이 있었고 그 시기 기대수명이 확 낮아졌음을 확인할 수 있습니다.
여기서 특이한 점은 인도는 특히 1918년도에 기대수명이 8세정도까지 되지않아
한 번 알아보았는데 이시기에 인도가 스페인독감으로 가장 많은 사상자를 내었다고 합니다. 1천7백만명의 사람이 사망했다고 합니다. 이시기에 다른 국가들로 독감으로 인해 많은 사망자가 나왔음을 확인할 수 있습니다.
전체 코드
참고자료
1. Do it 데이터 분석을 위한 판다스 입문
2. 데이터 전처리 대전
마무리
이번에는 기대수명을 가지고 시간데이터 증감 하는 방법 및 분류 하는 방법도 알아보고
간단한 분석도 해보았는데 저도 하면서 재밌었네요ㅎㅎ
이렇게 역사 공부도 하고 기억에도 잘 남을 것 같습니다.
그리고 다음에 좋은 시계열데이터 예제가 있다면 관련하여 포스팅 하도록 하겠습니다.
'Python' 카테고리의 다른 글
| [python] Selenium 크롬 드라이버 자동 설치 방법 (1) | 2022.11.29 |
|---|---|
| [python] pandas Apply를 사용하여 함수를 한번에 적용하기 (0) | 2022.10.25 |
| [python]pandas로 날짜&시간 데이터 다루기(1) (0) | 2022.09.29 |
| [Jupyter lab] 주피터랩에서 anaconda 가상환경 연결하기 (2) | 2022.04.21 |
| [python] pycharm에 anaconda 연동하기 (2) | 2022.03.16 |