안녕하세요.
크롤러를 만들다 보면,
내가 가져오고 싶은 부분이 어디에 위치해 있는지 알아야 할 때가 있습니다.
그 때 개발자도구를 사용하면 해당 사이트 html의 어느 부분에 있는지 금방 파악이 가능합니다.
지금부터 그 방법을 같이 알아보도록 하겠습니다.
여기에서 사용할 예시 사이트는 네이버 뉴스의 어느 한 기사 입니다.
- 예시 사이트: https://n.news.naver.com/article/666/0000019702
위의 사이트를 클릭해서 들어가 주세요.
위와 같은 기사가 보일 것입니다.
1. F12키를 눌러 개발자 도구 열기
우리가 만약 기사 제목을 수집하고 싶다고 가정해 봅시다.
제목을 가져오려면 html에 어디에 제목이 위치해 있는지 알아야 할 것입니다.
이 때 개발자 도구를 열어줍니다.
개발자 도구는 F12키를 누르면 확인할 수 있습니다.

위와 같이 우측에 창이 생길 것입니다.
하지만 소스 코드 전체를 한눈에 보기엔 어려움이 있습니다.
제목 또한 어디에 있는지 알기 어렵습니다.
이럴 때는 요소를 클릭하면 바로 알 수 있습니다.
2. 요소 선택하기
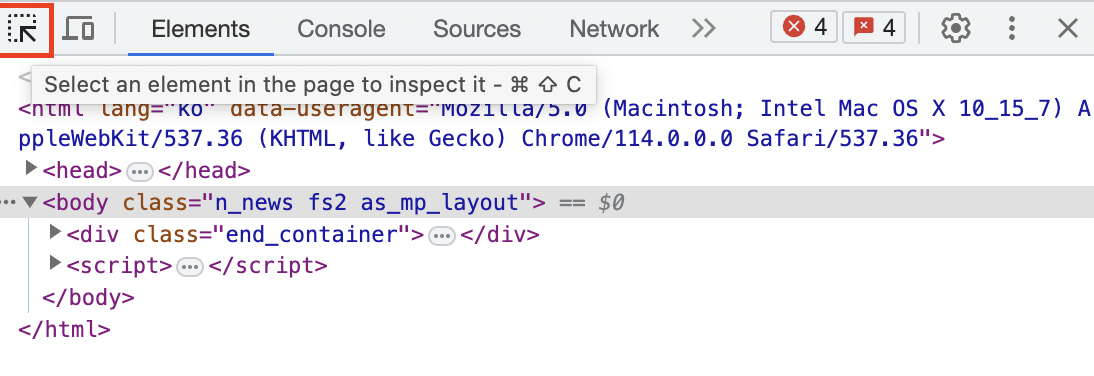
위의 개발자 도구 창을 보면 좌측 상단에 커서 아이콘이 보입니다.
이 아이콘은 페이지에서 요소를 선택해 검사할 수 있는 기능을 가지고 있습니다.
위의 사진에서 빨간색 박스로 표시된 아이콘을 클릭 후 왼쪽에 기사에 내가 확인하고 싶은 기사에 커서를 가져가면
아래 사진과 같이 파란색으로 표시가 됩니다.
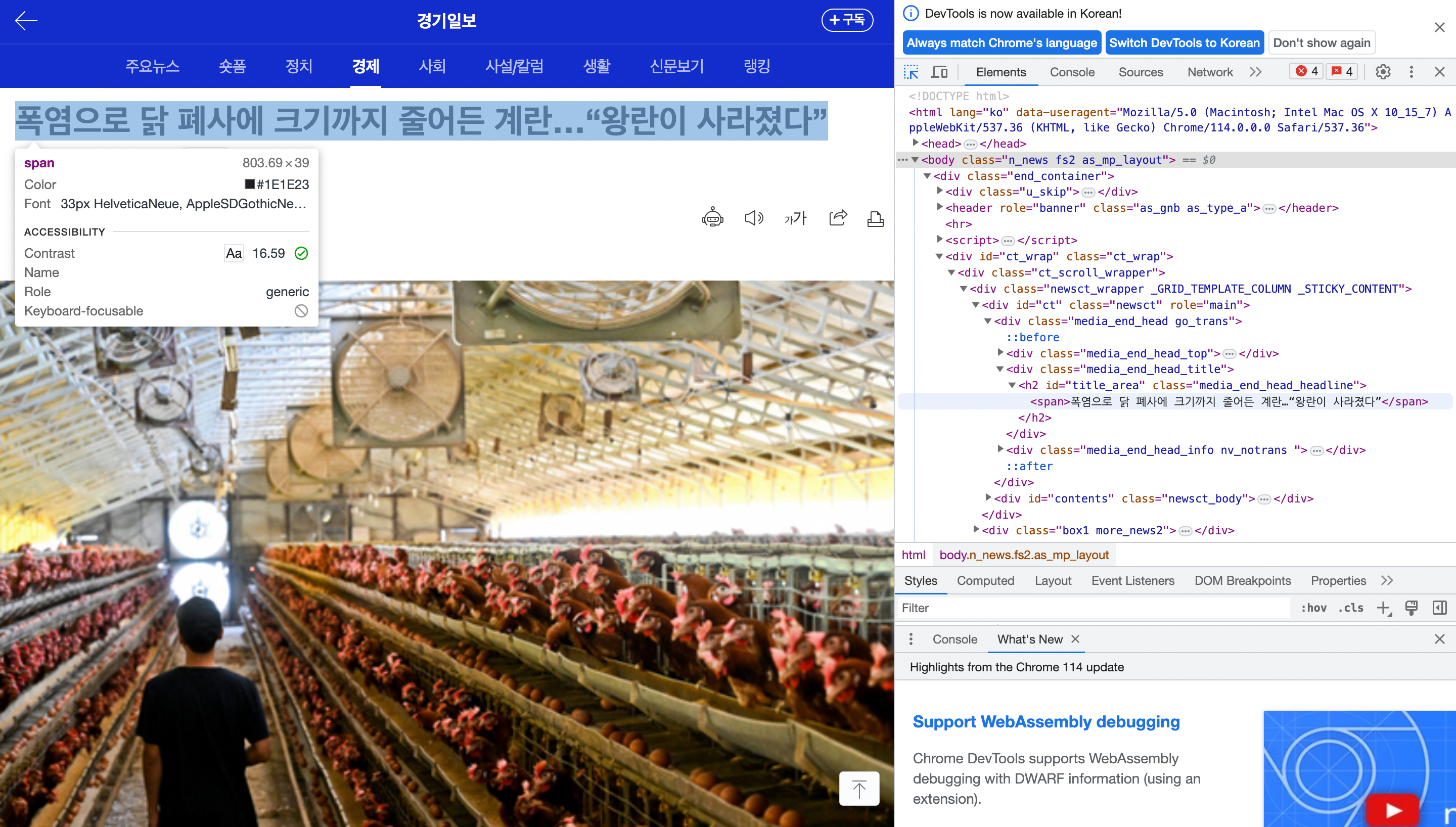
그후 오른쪽 창을 보면 아까는 보이지 않았던 제목 부분이 보입니다.

여기서 원래대로라면 body 밑에 div class name이 end_container인것 밑에 div ct_wrap 밑에 ct_scroll_wrapper 밑에 newsct... 밑에 이런 식으로 쭉쭉 타고 내려가서 h2에 span 에 제목이 위치해 있는 것을 확인할 수 있겠습니다만 귀찮고 복잡합니다.
이렇게 하나하나 눈으로 봐도 되지만 이 대신에 copy selector를 사용하면
더 간단하게 Beautiful Soup의 html selector를 사용해서 바로 가져올 수 있습니다.
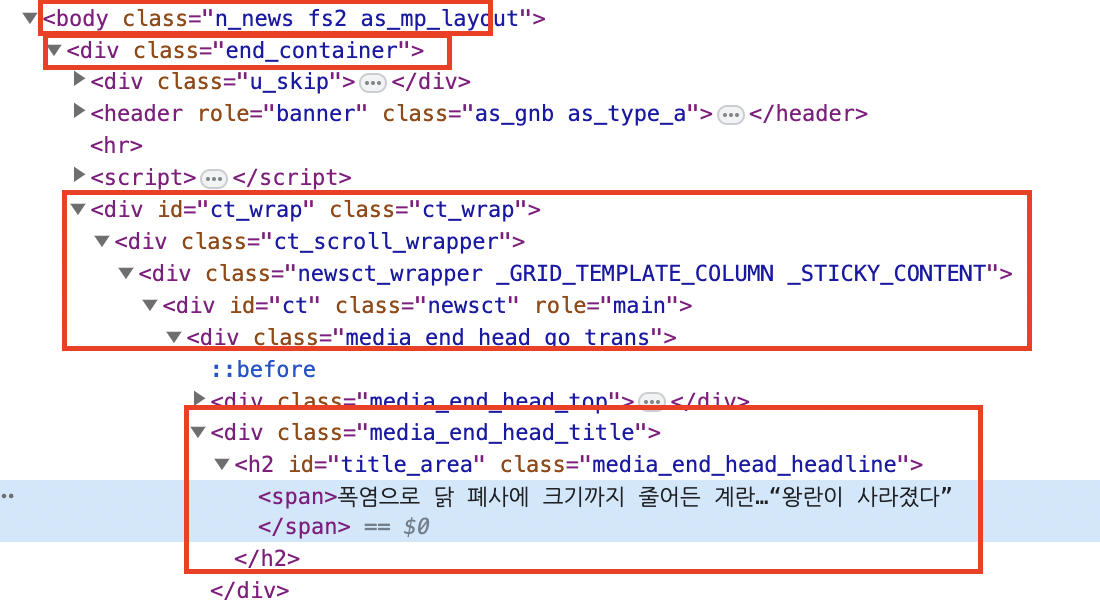
3. selector 복사하기
copy selector는 간단합니다.
아까 찾은 개발자 도구에서 제목부분 우클릭을 하고 Copy(복사) 클릭, Copy selector 클릭하면 복사가 됩니다.

이렇게 하고 Ctrl+V를 해서 붙여넣기를 하면 아래와 같이 복사됩니다.
#title_area > span
위의 뜻은 id가 title_area 아래의 span 태그에 제목이 위치해 있다는 것을 뜻합니다.
이것을 만약 Beautiful Soup의 select로 가져오려면 아래처럼 작성하면 제목을 가져오는 것을 확인할 수 있습니다.
#크롤링시 필요한 라이브러리 불러오기
from bs4 import BeautifulSoup
import requests
#테스트 기사
test_url = "https://n.news.naver.com/article/666/0000019702"
# ConnectionError방지
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/98.0.4758.102"}
news = requests.get(test_url,headers=headers)
news_html = BeautifulSoup(news.text,"html.parser")
title = news_html.select("#title_area > span")
title결과: [<span>폭염으로 닭 폐사에 크기까지 줄어든 계란…“왕란이 사라졌다”</span>]
이런 식으로 다른 부분들도 개발자 도구를 이용하면 간단하게 가져올 수 있습니다.
'Crawling' 카테고리의 다른 글
| [python] 네이버 뉴스 크롤러(날짜,링크,제목, 본문) (89) | 2022.07.14 |
|---|---|
| [python] 원하는 검색어로 네이버 뉴스 기사 제목 및 내용만 크롤링하기 (61) | 2022.02.24 |
| [python] 공공데이터 OPEN API의 xml 을 DataFrame으로 변환하기(feat. 코로나 확진자 수) (31) | 2021.11.04 |
| [python] 원하는 검색어로 네이버 뉴스 크롤링하기(2) (5) | 2021.10.22 |
| [python] Naver 오픈API를 이용하여 원하는 검색어로 블로그 크롤링 하기(제목+본문) (28) | 2021.10.21 |