안녕하세요!
오늘은 Pandas의 apply 메서드를 사용하는 방법을 알아보도록 하겠습니다.
종종 pandas로 csv 파일을 열어 dataframe을 만들 때,
각 행을 계산한다던가, 열을 계산하여야 할 때가 있습니다.
이때 pandas 의 apply 메서드를 사용하면 만들어 둔 함수를 간편하게 적용하여 계산이 가능합니다.
데이터 준비
데이터는 kaggle의 Lemonade-Orange-stand를 사용해 보겠습니다.
https://www.kaggle.com/datasets/adisak/lemonade-stand
Lemonade-Orange-stand
Lamonade and Orange Stand sales
www.kaggle.com
이 데이터는 각 날짜의 레몬, 오렌지 에이드 판매량을 보여주는 데이터셋입니다.
링크를 들어가서 Lemonade2016-2.csv 파일을 다운받아 줍니다.
그 후 csv파일을 아래와 같이 열어 줍니다.
import pandas as pd
df = pd.read_csv('Lemonade2016-2.csv')
df
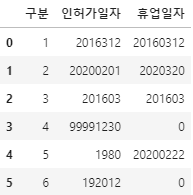
각 컬럼의 의미는 다음과 같습니다.
Date: 날짜
Location: 판매장소(공원/해변가)
Lemon: 레몬에이드 판매량(잔)
Orange: 오렌지에이드 판매량(잔)
Temperature: 기온(화씨/ºF)
Leaflets: 배포한 전단지 수
Price: 가격($)
Series에서 apply 적용하기 - 1개의 인자를 전달받는 함수
°C = (°F−32)×5/9
#화씨->섭씨 함수
# (temperature - 32) * 5 / 9
def to_C(x):
C = (x - 32) * 5 / 9
# 소수 셋째자리에서 반올림
C = round(C,2)
return C그리고 df에서 따로 날짜컬럼만 빼어서 apply 함수 적용 후 새로운 df열에 할당해 주도록 하겠습니다.
# 기온(temperature)을 섭씨(ºC)로 변환
temp = df['Temperature']
# apply 함수 적용 후 새로운 열에 섭씨온도 추가해 주기
df['temp_C'] = temp.apply(to_C)
df
2개의 인자를 전달받는 함수 - 25센트짜리 레몬에이드 판매액을 구하기
# price가 0.25인것만 필터링
cent_25 = df[df['Price'] == 0.25]
cent_25
이렇게 25센트인 날만 추출이 완료되었습니다.
#판매액 을 구하는 함수
def lemon_money(x, price):
total = x * price
return total
cent_25['Lemon'].apply(lemon_money,price=0.25)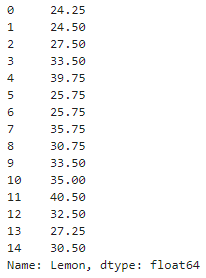
Dataframe에서 apply 적용하기 - 3개의 인자를 입력받아 계산하는 경우
def total(x,y,price):
total_money = (x+y)*price
return total_money#컬럼확인
df.columns
#컬럼 번호 확인
for itr,i in enumerate(df.columns):
print(itr,' : ',i)
# 1개의 인자값을 가지는 함수로 변경
# x=레몬에이드,y=오렌지에이드,price=가격 각각 열 위치로 변수 할당
def total(col):
x = col[2] #Lemon
y = col[3] #Orange
price = col[6] #Price
total_money = (x+y)*price
return total_money#df에 적용하여 리턴값 새 열에 할당
# 열 기준이므로 axis = 1
df['total'] = df.apply(total,axis=1)
df
전체 코드
import pandas as pd
df = pd.read_csv('Lemonade2016-2.csv')
# 기온(temperature)을 섭씨(ºC)로 변환
temp = df['Temperature']
#화씨->섭씨 함수
# (temperature - 32) * 5 / 9
def to_C(x):
C = (x - 32) * 5 / 9
# 소수 셋째자리에서 반올림
C = round(C,2)
return C
# apply 함수 적용 후 새로운 열에 섭씨온도 추가해 주기
df['temp_C'] = temp.apply(to_C)
# price가 0.25인것만 필터링
cent_25 = df[df['Price'] == 0.25]
#판매액 을 구하는 함수
def lemon_money(x, price):
total = x * price
return total
cent_25['Lemon'].apply(lemon_money,price=0.25)
#컬럼확인
df.columns
#컬럼 번호 확인
for itr,i in enumerate(df.columns):
print(itr,' : ',i)
# 1개의 인자값을 가지는 함수로 변경
# x=레몬에이드,y=오렌지에이드,price=가격 각각 열 위치로 변수 할당
def total(col):
x = col[2] #Lemon
y = col[3] #Orange
price = col[6] #Price
total_money = (x+y)*price
return total_money
#df에 적용하여 리턴값 새 열에 할당
# 열 기준이므로 axis = 1
df['total'] = df.apply(total,axis=1)
df코드파일
참고자료
Do it! 데이터 분석을 위한 판다스 입문
마무리
apply는 활용도가 높은 메서드 입니다. 유용히 사용하셨으면 좋겠습니다 ㅎㅎ
+ Blogspot 블로그도 개설하였습니다!
종종 방문해 주시면 좋겠습니다 ㅎㅎ
https://wonhwa1.blogspot.com/2022/10/python-pandas-apply.html
[python] pandas Apply를 사용하여 함수를 한번에 적용하기
Apply 종종 pandas로 csv 파일을 열어 dataframe을 만들 때, 각 행을 계산한다던가, 열을 계산하여야 할 때가 있습니다. 이때 pandas 의 apply 메서드를 사용하면 만들어 둔 함수를 간편하게 적용하여 계산
wonhwa1.blogspot.com
'Python' 카테고리의 다른 글
| [python]pandas csv 'utf-8' 인코딩 저장 후 파일을 열었을 때 한글이 깨지지 않게 설정하는 방법 (2) | 2022.12.14 |
|---|---|
| [python] Selenium 크롬 드라이버 자동 설치 방법 (1) | 2022.11.29 |
| [python]pandas로 날짜&시간 데이터 다루기(2) (0) | 2022.10.12 |
| [python]pandas로 날짜&시간 데이터 다루기(1) (0) | 2022.09.29 |
| [Jupyter lab] 주피터랩에서 anaconda 가상환경 연결하기 (2) | 2022.04.21 |