오늘은 Manim을 활용한 시각화 애니메이션 예제를 몇 가지 알아보도록 하겠습니다.
Preview

Manim 설치는 아래의 포스팅을 확인해 주세요 :)
https://wonhwa.tistory.com/36?category=1001573
[python/시각화] Manim을 활용한 애니메이션 시각화(1) - 설치
안녕하세요! 오늘은 Manim을 활용하여 시각하하기 위한 설치를 진행해 보도록 하겠습니다. Preview Manim이란? Manim(mathematical animation engine)은 수학을 보다 쉽게 설명하고 학생들에게 가르치기 위해 개
wonhwa.tistory.com
예제1: 모양이 바뀌는 도형 만들기
첫 번째 예제는 도형을 하나 생성하여(2차원) 그 도형의 모양을 바꾸는 예제입니다.
저번 설치때 만든 manim 폴더에 start.py라는 파이썬 파일을 만들어 준 후, 아래와 같이 코드를 적어줍니다.
from manimlib import *
class SquareToCircle(Scene):
def construct(self):
#원 만들기
circle = Circle()
circle.set_fill(GREEN,opacity=1.0) #색은 바꿀 수 있음 #opacity는 투명도
square = Square()
self.play(ShowCreation(square))
self.wait()
#도형모양 변경부분(네모를 동그라미로)
self.play(ReplacementTransform(square,circle))
self.wait()
# 원늘리기
self.play(circle.animate.stretch(4, 0))
#원 회전하기
self.play(Rotate(circle, 90 * DEGREES))
#도형 이동
self.play(circle.animate.shift(2 * RIGHT).scale(0.25))
#도형 굴곡
circle.insert_n_curves(10)
self.play(circle.animate.apply_complex_function(lambda z: z**2))
#텍스트 입력하기
text = Text("""
Hello World! ^0^
""")
self.play(Write(text))
always(circle.move_to, self.mouse_point)
#애니메이션 종료 후 창을 닫고 싶을때
#exit()사각형과 네모 객체를 만든 후 네모를 원으로 바꾸고,
그 원의 모양을 또 바꾸어 마지막엔 텍스트를 추가하는 예제입니다.
이렇게 코드를 작성 후 저장해 주세요.
그 후 anaconda 프롬프트 창 또는 cmd 창을 열어 주세요.
#1. manim폴더 위치로 이동
cd manim
#2. manim 가상환경 활성화
activate manim
#또는 anaconda prompt 에서 동작 시
conda activate manim
#3. 함수 실행 명령어 입력
manimgl start.py SquareToCircle
#팁: 동영상으로 저장 시
manimgl start.py SquareToCircle -o
#팁2: 애니메이션 종료 시
#실행되고 있는 애니메이션 창 클릭 후
#q 키를 눌러 실행 종료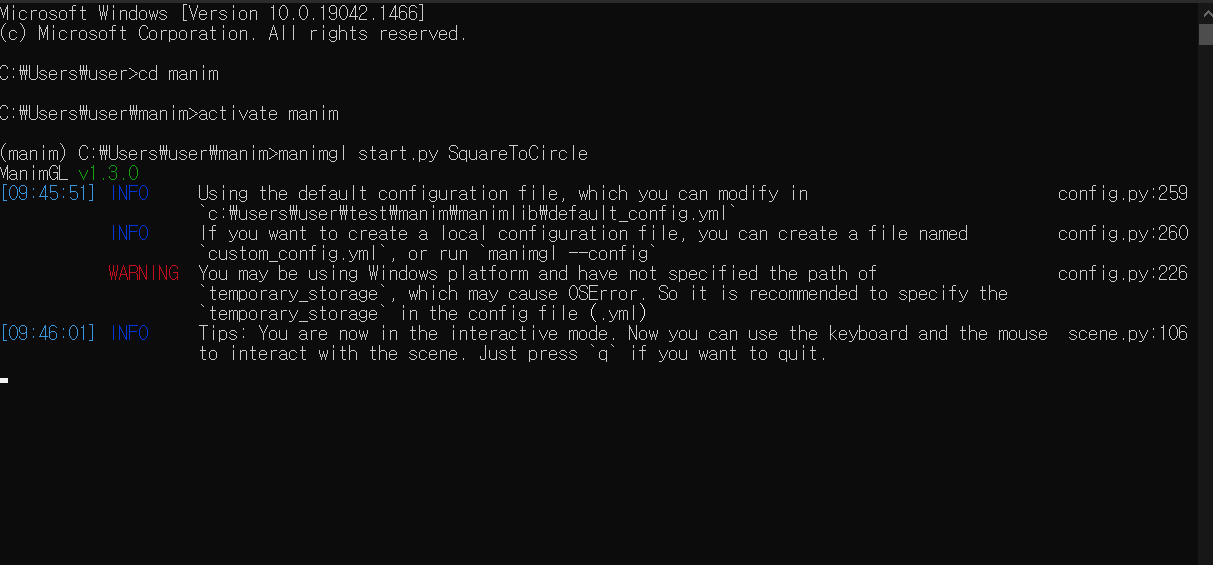
위의 명령어를 입력하면 작성한 코드가 실행이 됩니다.
실행 애니메이션을 저장할 수도 있습니다.
명령어 끝에 -o를 붙이면 videos 라는 폴더 안에 동영상이 저장됩니다.
화면 종료 시에는 실행되고 있는 애니메이션 창을 한번 클릭 후 q 키를 눌러 종료합니다.
예제2: 텍스트 애니메이션
다음으로 알아볼 예제는 텍스트 애니메이션입니다.
Manim에서는 텍스트로 애니메이션화할 때 특정 단어만 폰트 및 색상 변경이 가능합니다.
페이드인효과도 줄 수 있습니다.
class TextExample(Scene):
def construct(self):
text = Text("여기에 텍스트가 있습니다.", font="BM DoHyeon", font_size=90) #폰트 변경시 font= 에 원하는 폰트 이름 입력
difference = Text(
"""
Manim에서는 텍스트를 애니메이션으로 시각화가 가능합니다.\n
지금 보고 계시는 폰트는 맑은 고딕인데요\n
폰트 색도 단어마다 변경이 가능합니다.
""",
font="Malgun Gothic", font_size=24,
# 단어마다 색 변경하기(딕셔너리)
t2c={"텍스트": BLUE, "애니메이션": BLUE, "맑은 고딕": ORANGE}
)
VGroup(text, difference).arrange(DOWN, buff=1)
self.play(Write(text))
self.play(FadeIn(difference, UP)) #페이드인 효과
self.wait(3)
fonts = Text(
"또한 폰트를 단어마다 다르게 설정할 수 있습니다.",
font="Gulim",
t2f={"폰트": "BM DoHyeon", "단어": "Malgun Gothic"}, #특정단어에 특정폰트 설정
t2c={"폰트": BLUE, "단어": GREEN} #특정 단어에 색상 설정
)
fonts.set_width(FRAME_WIDTH - 1)
slant = Text(
"물론 이탤릭체와 굵기도 설정 가능합니다.",
font="Malgun Gothic",
t2s={"이탤릭체": ITALIC}, #텍스트 효과 주기
t2w={"굵기": BOLD},
t2c={"이탤릭체": ORANGE, "굵기": RED}
)
VGroup(fonts, slant).arrange(DOWN, buff=0.8)
self.play(FadeOut(text), FadeOut(difference, shift=DOWN))
self.play(Write(fonts))
self.wait()
self.play(Write(slant))
self.wait()한글을 작성할 때는 한글 폰트로 사용하여야 깨짐 현상이 일어나지 않습니다.
마찬가지로 명령창에 아래와 같은 명령어를 입력해주면 실행이 됩니다.
항상 start.py파일을 저장하고 실행해야 최신 상태로 구동이 됩니다.
# 코드실행
manimgl start.py TextExample
# 영상저장
manimgl start.py TextExample -o
#영상 종료
q
예제3: 3차원 도형 및 이미지
마지막 예제로 3차원 도형을 시각화해보겠습니다.
지구 모양의 원을 만들고 이미지를 다운받아 표면을 표현해 줍니다.
그 후 회전을 주어 지구가 회전하는 모습을 보여줍니다.
또한 지구 낮 버전 밤 버전을 번갈아서 나타낼 수 있습니다.
아래의 코드를 입력해 주세요.
class SurfaceExample(Scene):
CONFIG = {
"camera_class": ThreeDCamera,
}
def construct(self):
surface_text = Text(" 3차원으로 도형을 나타낼 수 있습니다.",font="BM DoHyeon")
surface_text.fix_in_frame()
surface_text.to_edge(UP)
self.add(surface_text)
self.wait(0.1)
#원모양 도형 준비
torus1 = Torus(r1=1, r2=1)
torus2 = Torus(r1=3, r2=1)
sphere = Sphere(radius=3, resolution=torus1.resolution)
# 2가지 지구 버전 이미지 준비
day_texture = "https://upload.wikimedia.org/wikipedia/commons/thumb/4/4d/Whole_world_-_land_and_oceans.jpg/1280px-Whole_world_-_land_and_oceans.jpg"
night_texture = "https://upload.wikimedia.org/wikipedia/commons/thumb/b/ba/The_earth_at_night.jpg/1280px-The_earth_at_night.jpg"
surfaces = [
TexturedSurface(surface, day_texture, night_texture)
for surface in [sphere, torus1, torus2]
]
# 그리드(격자 보여주기)
for mob in surfaces:
mob.shift(IN)
mob.mesh = SurfaceMesh(mob)
mob.mesh.set_stroke(BLUE, 1, opacity=0.5)
# Set perspective 특징설정
frame = self.camera.frame
frame.set_euler_angles(
theta=-30 * DEGREES,
phi=70 * DEGREES,
)
surface = surfaces[0]
surface.save_state()
self.play(
FadeIn(surface),
ShowCreation(surface.mesh, lag_ratio=0.01, run_time=3),
)
for mob in surfaces:
mob.add(mob.mesh)
surface.save_state()
self.play(Rotate(surface, PI/2), run_time=2)
for mob in surfaces[1:]:
mob.rotate(PI/2)
# 회전모션 추가
frame.add_updater(lambda m, dt: m.increment_theta(-0.1 * dt))
#밤의 지구버전 보여주기
light_text = Text("2가지 사진을 사용하여 번갈아 가며 나타낼 수도 있습니다.",font="BM DoHyeon")
light_text.move_to(surface_text)
light_text.fix_in_frame()
self.play(FadeTransform(surface_text, light_text))
light = self.camera.light_source
self.add(light)
light.save_state()
self.play(light.animate.move_to(3 * IN), run_time=5)
self.play(light.animate.shift(10 * OUT), run_time=5)
drag_text = Text("d나 s를 누른 상태에서 마우스를 움직여 물체를 이동시켜 보세요.",font="BM DoHyeon")
drag_text.move_to(light_text)
drag_text.fix_in_frame()
self.play(FadeTransform(light_text, drag_text))
self.wait()이번에는 d나 s를 눌러 상호작용이 가능합니다.
d는 도형 내에서 원하는 각도로 변경할 수 있고 s는 도형 자체를 이동시킬 수 있습니다.
# 코드실행
manimgl start.py SurfaceExample
# 영상저장
manimgl start.py SurfaceExample -o
#종료
q
참고자료
- Manim 문서
https://3b1b.github.io/manim/getting_started/quickstart.html
Quick Start - manim documentation
Previous Installation
3b1b.github.io
전체코드
from manimlib import *
class SquareToCircle(Scene):
def construct(self):
#원 만들기
circle = Circle()
circle.set_fill(GREEN,opacity=1.0) #색은 바꿀 수 있음 #opacity는 투명도
square = Square()
self.play(ShowCreation(square))
self.wait()
#도형모양 변경부분(네모를 동그라미로)
self.play(ReplacementTransform(square,circle))
self.wait()
# 원늘리기
self.play(circle.animate.stretch(4, 0))
#원 회전하기
self.play(Rotate(circle, 90 * DEGREES))
#도형 이동
self.play(circle.animate.shift(2 * RIGHT).scale(0.25))
#도형 굴곡
circle.insert_n_curves(10)
self.play(circle.animate.apply_complex_function(lambda z: z**2))
#텍스트 입력하기
text = Text("""
Hello World! ^0^
""")
self.play(Write(text))
always(circle.move_to, self.mouse_point)
#애니메이션 종료 후 창을 닫고 싶을때
#exit()
class TextExample(Scene):
def construct(self):
text = Text("여기에 텍스트가 있습니다.", font="BM DoHyeon", font_size=90) #폰트 변경시 font= 에 원하는 폰트 이름 입력
difference = Text(
"""
Manim에서는 텍스트를 애니메이션으로 시각화가 가능합니다.\n
지금 보고 계시는 폰트는 맑은 고딕인데요\n
폰트 색도 단어마다 변경이 가능합니다.
""",
font="Malgun Gothic", font_size=24,
# 단어마다 색 변경하기(딕셔너리)
t2c={"텍스트": BLUE, "애니메이션": BLUE, "맑은 고딕": ORANGE}
)
VGroup(text, difference).arrange(DOWN, buff=1)
self.play(Write(text))
self.play(FadeIn(difference, UP)) #페이드인 효과
self.wait(3)
fonts = Text(
"또한 폰트를 단어마다 다르게 설정할 수 있습니다.",
font="Gulim",
t2f={"폰트": "BM DoHyeon", "단어": "Malgun Gothic"}, #특정단어에 특정폰트 설정
t2c={"폰트": BLUE, "단어": GREEN} #특정 단어에 색상 설정
)
fonts.set_width(FRAME_WIDTH - 1)
slant = Text(
"물론 이탤릭체와 굵기도 설정 가능합니다.",
font="Malgun Gothic",
t2s={"이탤릭체": ITALIC}, #텍스트 효과 주기
t2w={"굵기": BOLD},
t2c={"이탤릭체": ORANGE, "굵기": RED}
)
VGroup(fonts, slant).arrange(DOWN, buff=0.8)
self.play(FadeOut(text), FadeOut(difference, shift=DOWN))
self.play(Write(fonts))
self.wait()
self.play(Write(slant))
self.wait()
class SurfaceExample(Scene):
CONFIG = {
"camera_class": ThreeDCamera,
}
def construct(self):
surface_text = Text(" 3차원으로 도형을 나타낼 수 있습니다.",font="BM DoHyeon")
surface_text.fix_in_frame()
surface_text.to_edge(UP)
self.add(surface_text)
self.wait(0.1)
#원모양 도형 준비
torus1 = Torus(r1=1, r2=1)
torus2 = Torus(r1=3, r2=1)
sphere = Sphere(radius=3, resolution=torus1.resolution)
# 2가지 지구 버전 이미지 준비
day_texture = "https://upload.wikimedia.org/wikipedia/commons/thumb/4/4d/Whole_world_-_land_and_oceans.jpg/1280px-Whole_world_-_land_and_oceans.jpg"
night_texture = "https://upload.wikimedia.org/wikipedia/commons/thumb/b/ba/The_earth_at_night.jpg/1280px-The_earth_at_night.jpg"
surfaces = [
TexturedSurface(surface, day_texture, night_texture)
for surface in [sphere, torus1, torus2]
]
# 그리드(격자 보여주기)
for mob in surfaces:
mob.shift(IN)
mob.mesh = SurfaceMesh(mob)
mob.mesh.set_stroke(BLUE, 1, opacity=0.5)
# Set perspective 특징설정
frame = self.camera.frame
frame.set_euler_angles(
theta=-30 * DEGREES,
phi=70 * DEGREES,
)
surface = surfaces[0]
surface.save_state()
self.play(
FadeIn(surface),
ShowCreation(surface.mesh, lag_ratio=0.01, run_time=3),
)
for mob in surfaces:
mob.add(mob.mesh)
surface.save_state()
self.play(Rotate(surface, PI/2), run_time=2)
for mob in surfaces[1:]:
mob.rotate(PI/2)
# 회전모션 추가
frame.add_updater(lambda m, dt: m.increment_theta(-0.1 * dt))
#밤의 지구버전 보여주기
light_text = Text("2가지 사진을 사용하여 번갈아 가며 나타낼 수도 있습니다.",font="BM DoHyeon")
light_text.move_to(surface_text)
light_text.fix_in_frame()
self.play(FadeTransform(surface_text, light_text))
light = self.camera.light_source
self.add(light)
light.save_state()
self.play(light.animate.move_to(3 * IN), run_time=5)
self.play(light.animate.shift(10 * OUT), run_time=5)
drag_text = Text("d나 s를 누른 상태에서 마우스를 움직여 물체를 이동시켜 보세요.",font="BM DoHyeon")
drag_text.move_to(light_text)
drag_text.fix_in_frame()
self.play(FadeTransform(light_text, drag_text))
self.wait()
터미널 명령어 모음
#1. manim폴더 위치로 이동
cd manim
#2. manim 가상환경 활성화
activate manim
#또는 anaconda prompt 에서 동작 시
conda activate manim
#3. 함수 실행 명령어 입력
manimgl start.py SquareToCircle
#팁: 동영상으로 저장 시
manimgl start.py SquareToCircle -o
#팁2: 애니메이션 종료 시
#실행되고 있는 애니메이션 창 클릭 후
#q 키를 눌러 실행 종료
# 예제2 코드실행
manimgl start.py TextExample
# 영상저장
manimgl start.py TextExample -o
#영상 종료
q
# 예제3 코드실행
manimgl start.py SurfaceExample
# 영상저장
manimgl start.py SurfaceExample -o
#종료
q
코드 파일
마무리
오늘은 간단한 Manim 예제 몇가지를 알아보았습니다 ㅎㅎ
마님 문서에 가면 더 다양한 예제를 확인할 수 있습니다.
Manim을 활용하여 시각화하고 싶은 애니메이션이 있다면 댓글로 알려주세요 :)
저도 활용하기 좋은 아이디어가 있으면 포스팅으로 공유하도록 하겠습니다.ㅎㅎ
'시각화(Visualization)' 카테고리의 다른 글
| [python/시각화] Manim을 활용한 애니메이션 시각화(1) - 설치 (0) | 2022.01.21 |
|---|---|
| [python/시각화] seaborn으로 그래프 그리기 (0) | 2021.12.20 |
| [python/시각화] matplotlib으로 그래프 만들기- 다변량그래프, 밀집도그래프, 육각그래프 (0) | 2021.12.15 |
| [python/시각화] matplotlib으로 그래프 만들기- 히스토그램, 산점도, 박스그래프 (0) | 2021.12.15 |
| [python] CCTV,가로등 위치를 folium을 사용하여 clustering 시각화하기 (4) | 2021.11.17 |