[python]pandas로 날짜&시간 데이터 다루기(1)
안녕하세요.
분석할 csv 파일을 읽어올 때 시계열 데이터도 들어있는 경우도 많을 텐데요,
이때 전처리나 기본 분석을 할 때 도움이 될 수 있도록
날짜 및 시간 데이터를 pandas에서 다루는 방법에 대해 포스팅 하려고 합니다.
그럼 시작하겠습니다!
데이터 준비
데이터로는 공공데이터 API를 통해 생성한 코로나 확진자 관련 csv 파일을 준비해 보았습니다.
데이터 파일 만드는 방법은 아래의 링크를 참고해 주세요 :)
https://wonhwa.tistory.com/16?category=996518
[python] 공공데이터 OPEN API의 xml 을 DataFrame으로 변환하기(feat. 코로나 확진자 수)
안녕하세요~! 오늘은 공공데이터 openAPI의 xml을 Pandas DataFrame으로 변환하여 보도록 하겠습니다. json에서 DataFrame으로의 변환은 여기를 클릭해서 확인해 주세요 :) step1. 데이터 활용신청하기 공공데
wonhwa.tistory.com
저는 전에 만들어 둔 2020년 01월 20일부터 2022년 02월 23일까지의 시도별 코로나 확진자 현황 파일을 사용하였습니다.
파일이 필요하신 분은 위에서 다운받아 실습 진행하시면 됩니다!
csv 불러오기 및 데이터 타입 확인하기
그럼 위에서 다운받은 csv파일을 불러와 보도록 하겠습니다.
그리고, dtypes를 사용하여 파일 전체 열에 대해 데이터 타입이 어떻게 설정되어 있는지 확인합니다.
#데이터 불러오기
import pandas as pd
covid_df = pd.read_csv('Covid19Korea(200120220223).csv')
covid_df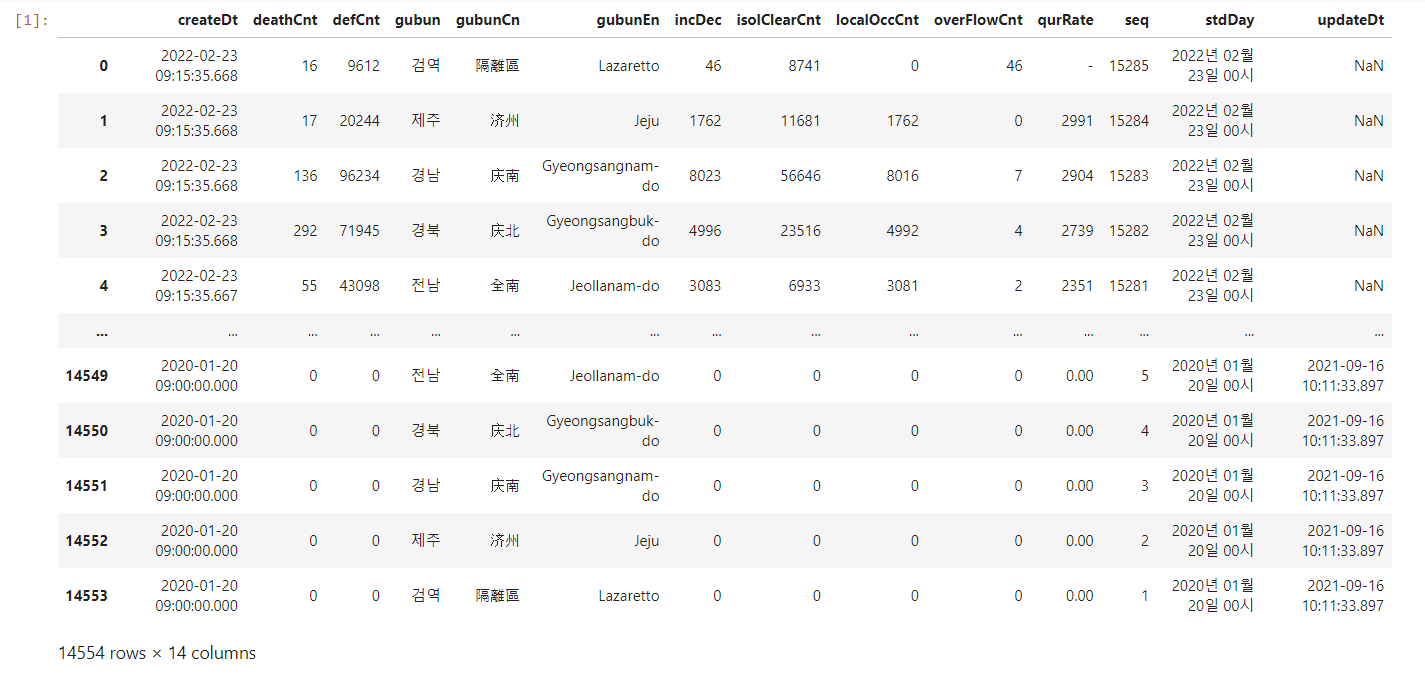
14454행 x 14열 을 가진 데이터 프레임이 불러와졌습니다.
데이터 열에 관련해서는 아래를 참고해 주세요.
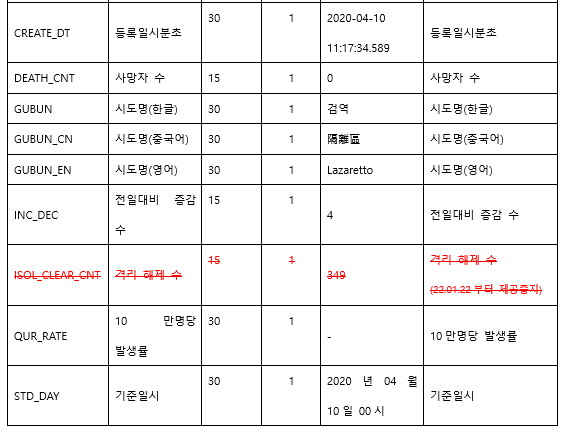
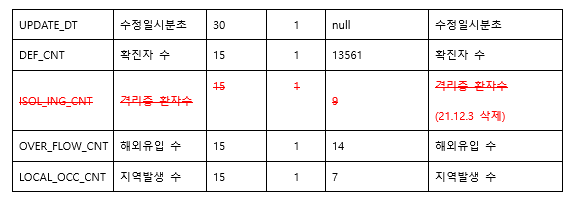
#데이터 타입 확인
covid_df.dtypes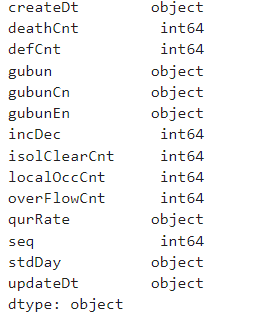
데이터 타입을 확인해 보면, createDt(등록일시분초), std_day(기준일시) 등은 날짜형인데도 object로 설정되어있는 것을 확인할 수 있습니다.
(눈으로 볼때는 날짜형으로 보여도 실제 데이터 타입은 다를 수 있으니 항상 사전에 확인해 보시길 바랍니다.)
pandas에서 날짜 계산이나 추출을 위해서는 해당 열을 datetime 형으로 바꿔주어야 올바른 계산이 가능합니다.
때문에 날짜데이터로 형변환을 해 주도록 하겠습니다.
datetime으로 데이터 타입 변경하기
날짜 데이터로 변경할 때
1. to_datetime으로 변경하는 방법
및
2. parse_dates=[col_idx]
의 2가지 방법으로 변경이 가능합니다.
createDt열을 datetime으로 변경해 보도록 하겠습니다.
아래는 pd.to_datetime을 사용하여 변경하는 방법입니다.
#createDt열 날짜 데이터 타입으로 변경하기
covid_df['createDt'] = pd.to_datetime(covid_df['createDt'])다음으로는 csv를 불러올 때 parse_dates = [열인덱스]를 사용하여 변경하는 방법입니다.
코로나csv 파일에서 createDt가 0번째 열이므로 [0] 을 입력해 줍니다.
그후 데이터 타입을 출력해 봅니다.
#createDt열 날짜 데이터 타입으로 변경방법 2: parse_dates=[col_idx]사용
covid_df2 = pd.read_csv('Covid19Korea(200120220223).csv', parse_dates=[0])
covid_df2.dtypes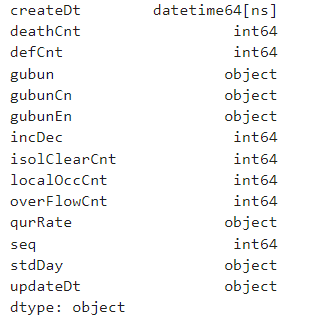
그럼 아까 object였던 createDt열이 datetime으로 변경된 것을 확인할 수 있습니다.
추가로, stdDay도 datetime으로 바꿔보도록 하겠습니다.
다만, stdDay는

위처럼 한글이 섞여 있어 '년','월','일','시'를 제거 후 datetime으로 변경해 주겠습니다.
# stdDay열은 한글이 섞여 있으므로 한글 제거 후 datetime으로 변경
covid_df['stdDay'] = covid_df['stdDay'].replace(['년','월','일','시'],"",regex=True)
covid_df[['stdDay']]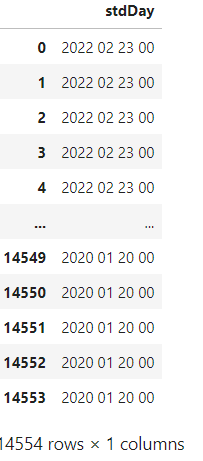
replace를 사용하여 한글을 제거해 주었습니다.
그후 데이터 타입을 변경해 주는데,
pandas에서는 format으로 시간형식 지정자를 입력하여 데이터 타입 변경도 가능합니다.
format='%Y-%m-%d %H:%M'
등으로 지정 가능하며 의미는 아래와 같습니다.
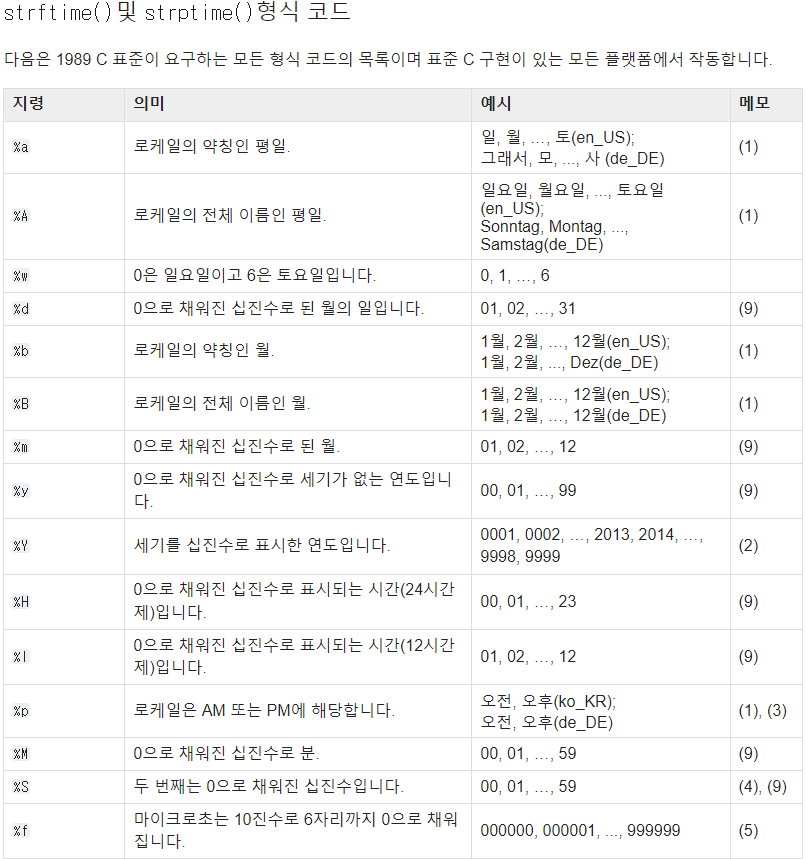
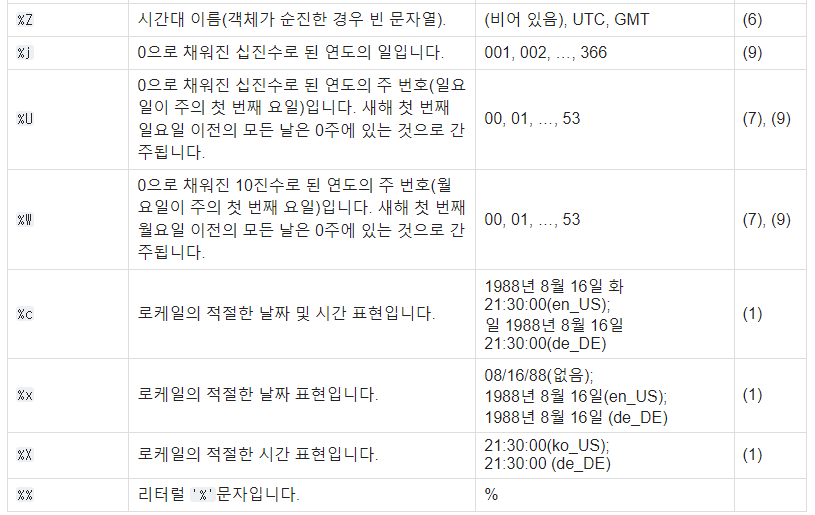
예시 부분은 영어를 한국어로 번역한 것이라 내용이 어색할 수 있습니다.
때문의 자세한 내용은 아래 링크에서 확인해 주세요.
https://docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior
datetime — Basic date and time types — Python 3.10.7 documentation
datetime — Basic date and time types Source code: Lib/datetime.py The datetime module supplies classes for manipulating dates and times. While date and time arithmetic is supported, the focus of the implementation is on efficient attribute extraction for
docs.python.org
stdDay는 시간까지의 정보가 있으므로 시간단위까지 format으로 지정해 주겠습니다.
covid_df['stdDay'] = pd.to_datetime(covid_df['stdDay'],format='%Y-%m-%d %H')이렇게 stdDay열도 datetime으로 변경되었습니다.
세부날짜(년, 월, 일) 추출하기
datetime형의 데이터는 년, 월, 일 등을 각각 뽑아낼 수 있습니다.
해당 날짜 데이터 셀.year을 사용하여 아래처럼 년도를 추출할 수 있습니다.
covid_df['stdDay'][0].year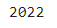
주의할 점은 df프레임에서 바로 .year을 하면 오류가 나고, covid_df['stdDay'][0] 처럼 개별 데이터로 접근 후 .year을 해야
원하는 정보를 찾을 수 있습니다.
열별로 한번에 데이터를 얻고 싶으면 dt를 사용하여 한번에 추출할 수 있습니다.
예시로,
createDt에서 년, 월, 일을 추출해 각각 새로운 컬럼을 만들어 거기에 저장해 주도록 하겠습니다.
데이터프레임열.dt.year
데이터프레임열.dt.month
데이터프레임열.dt.day
를 사용하여 추출할 수 있습니다.
# 년월일 추출하여 새로운 열로 추가하기
covid_df['Year'],covid_df['Month'],covid_df['Day'] = covid_df['createDt'].dt.year, covid_df['createDt'].dt.month, covid_df['createDt'].dt.day
covid_df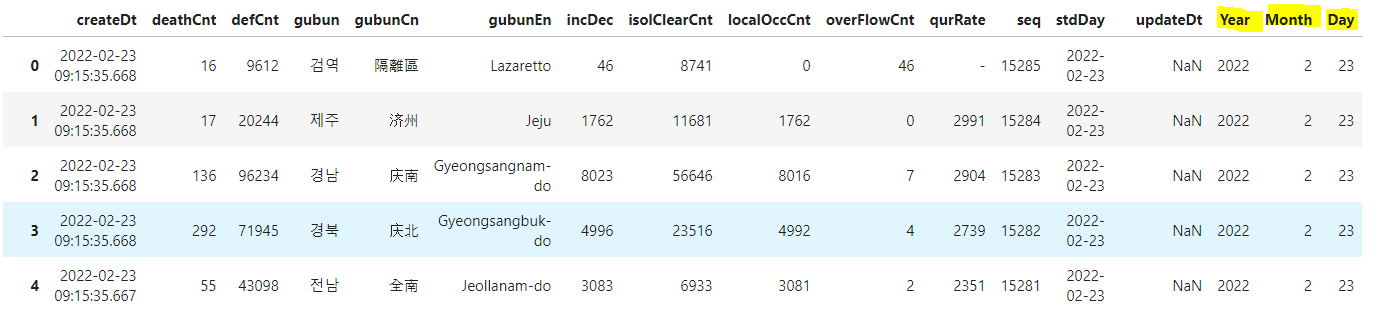
이렇게 끝에 년, 월, 일 3개의 열이 추가가 되었습니다.
날짜의 계산
이번에는 날짜 계산을 해보도록 하겠습니다.
코로나 확진자가 한국에 처음 발생한 날짜를 찾아, 발생일로부터 얼마나 지났는지 계산해 보겠습니다.
코로나 확진자가 최초로 발생한 날은 createDt열의 .min()함수를 사용하여 알 수 있습니다.
# 코로나 최초 발병일로 부터 며칠이 지났는지 계산하기
## 날짜의 계산 ##
# 최초 발생자가 있는 날: 2020년 1월 20일(인천 1명)
covid_df['createDt'].min()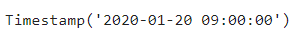
이것을 기준으로 하여 각 행마다 며칠이 지났는지 계산해 보겠습니다.
각 행의 createDt에서 최초 발생일을 빼서 구할 수 있습니다.
outbreak_day = 등록일시 - 최초발생일
# outbreak_day 열을 만들어 발병일로 부터 며칠 지났는지 계산하기
covid_df['outbreak_day'] = covid_df['createDt'] - covid_df['createDt'].min()
covid_df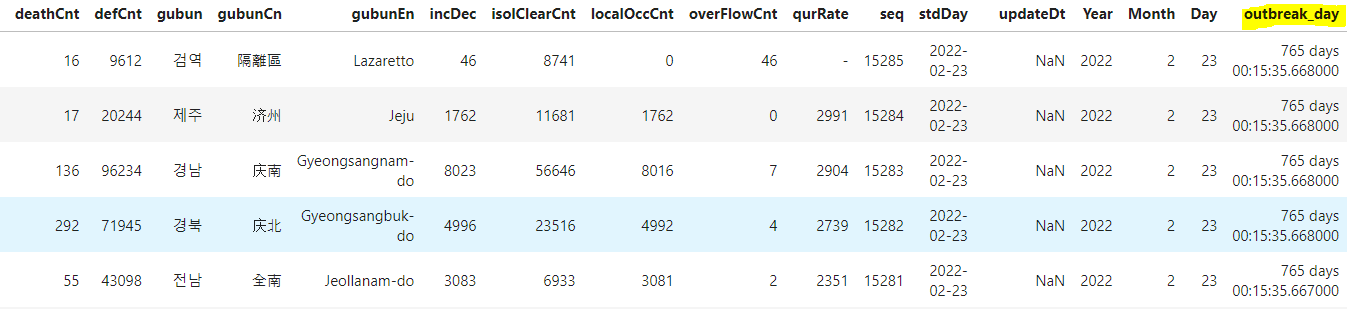
맨 끝 열에 outbreak_day가 추가되었습니다.
특정 기간의 데이터 추출
이번에는 특정 날짜의 데이터를 loc을 사용하여 추출해 보도록 합시다.
df.loc[df.날짜데이터열이름.dt.(year,month,day) == 해당 (년,월,일)]
위처럼 조건을 지정하여 추출이 가능합니다.
예시로 코로나 데이터의 2021년 데이터만 추출해 보도록 하겠습니다.
## 특정 기간의 데이터 추출
# 2021년 데이터 추출
test1_df = covid_df.loc[covid_df.createDt.dt.year == 2021]
test1_df
두 가지 이상의 조건도 설정 가능합니다.
이때 '&'을 사용하여 and조건을 사용할 수 있습니다.
df.loc[df(조건1) & df( 조건 2 ) ]
#2022년 1월 데이터만 추출(and 조건은 & 로 표시)
test2_df = covid_df.loc[(covid_df.createDt.dt.year == 2021) & (covid_df.createDt.dt.month == 1)]
test2_df
or 조건은 | (Shift+\) 를 사용하여 설정할 수 있습니다.
df.loc[df(조건1) | df( 조건 2 ) ]
#2020년도 또는 2021년도 데이터 추출(or 조건은 | 로 표시)
test3_df = covid_df.loc[(covid_df.createDt.dt.year == 2020) | (covid_df.createDt.dt.year == 2021)]
test3_df
이렇게 데이터를 추출 할 수 있습니다.
다만, 위 사진을 보면 맨 첫행 인덱스가0 이아닌 1026으로 되어 있습니다. 때문에 추후 분석할 때는 인덱스를 0부터 재세팅해주는 과정이 필요합니다.
인덱스 재세팅 방법은 아래 날짜별 값 계산에서 확인해 보도록 하겠습니다.
날짜별 값 계산하기(groupby)
처음 언급했듯이 사용되고 있는 데이터는 2020년부터 2022년 2월까지의 데이터를 담고 있습니다.
그리고 분석 시 년도별 코로나 발생 인원이 몇명인지 알고 싶을 때 groupby를 사용하여 계산을 해 보겠습니다.
우선, 데이터를 보면 시도 데이터 뿐만이 아니라 합계, 검역 같은 데이터 행도 있습니다.
여기서 전체 발생인원을 파악하여야 하니까
'합계' 행만 추출하여 계산하도록 하겠습니다.
우선 원본 df에서 gubun이 '합계'인 행만 추출해 줍니다.
# groupby를 사용하여 년도별 코로나 확진자 수 구하기
# '합계' 를 기준으로 하여 전국 년도별 코로나 확진자 수 구하기
#1. gubun 이 합계인 행만 추출하기
total_df = covid_df.loc[covid_df['gubun']=='합계']
total_df
이렇게 766행이 선택되었습니다.
그런데, 맨 첫 행이 0이 아니라 18 입니다. 때문에 인덱스를 0부터 다시 설정해 줍니다.
# 2. index 재세팅하기
new_idx = [i for i in range(len(total_df))]
total_df.index = new_idx
total_df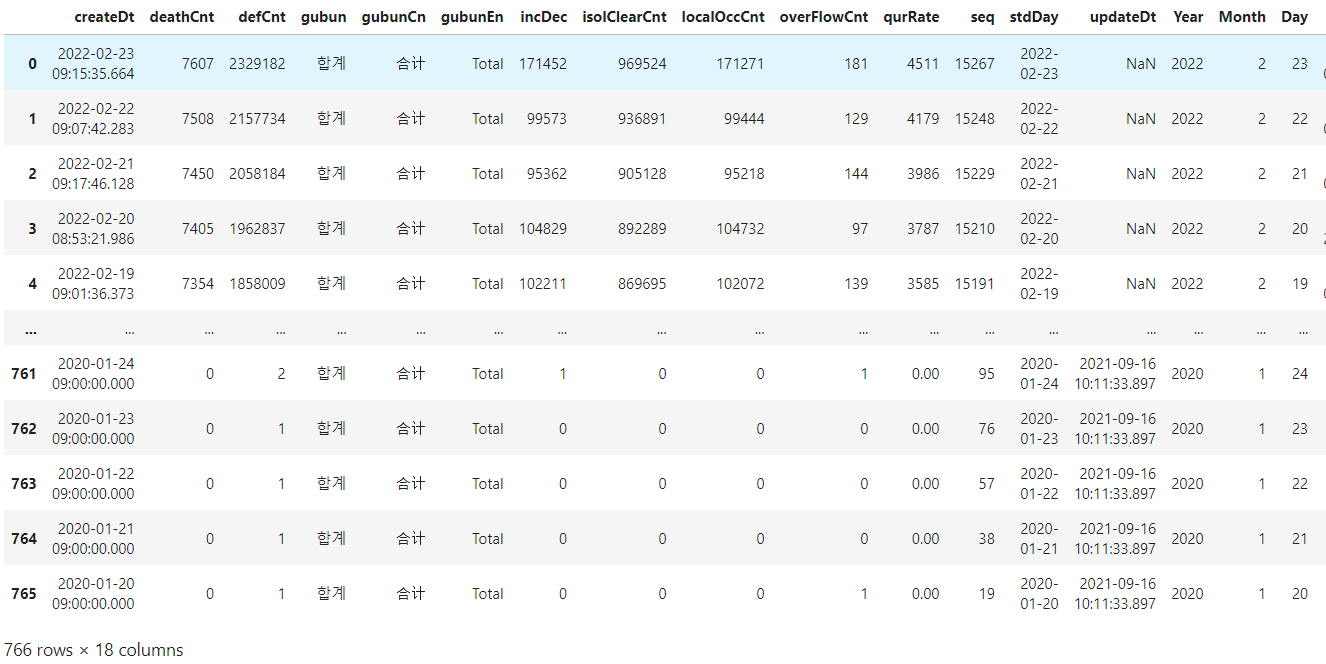
그럼 0부터 765까지 전체 행의 인덱스가 잘 정리되었습니다.
그 후 groupby를 사용하여 'Year'을 기준으로 합계를 구해 줍니다.
우리가 필요한 정보는 코로나 확진자 정보이므로 'incDec' (전일 대비 코로나 환자 수) 열의 합계만을 출력해 보겠습니다.
#groupby로 년도별 확진자 합계 확인하기(incDec: 전일대비 증감수)(2022년도는2월 23일까지)
defCnt_sum = total_df.groupby(['Year']).sum()
defCnt_sum[['incDec']]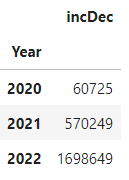
그럼 2020년, 2021년, 2022년(1월~2월 23일까지)의 확진자 수가 집계되었습니다.
위의 데이터를 보면, 2022년도는 1,2월 두달 치의 정보만 있는데도 그 전 년도의 확진자 수를 훨씬 넘어서는 것을 확인할 수 있습니다.
날짜를 인덱스로 설정하기
datetime 을 인덱스로 지정하면 따로 조건을 지정하지 않아도 원하는 날짜 부분의 추출이 바로 가능합니다.
우선 합계 df 인 total_df가 최신 날짜 순으로 지정되어 있어 오래된 날짜 순으로 정렬한 뒤,
인덱스를 datetime 인 createDt열로 바꾸어 보겠습니다.
# 날짜를 인덱스로 설정하기
total_df = total_df.sort_values('createDt') #날짜 오래된 순으로 정렬
#인덱스를 createDt로 변경
total_df.index = total_df['createDt']
total_df
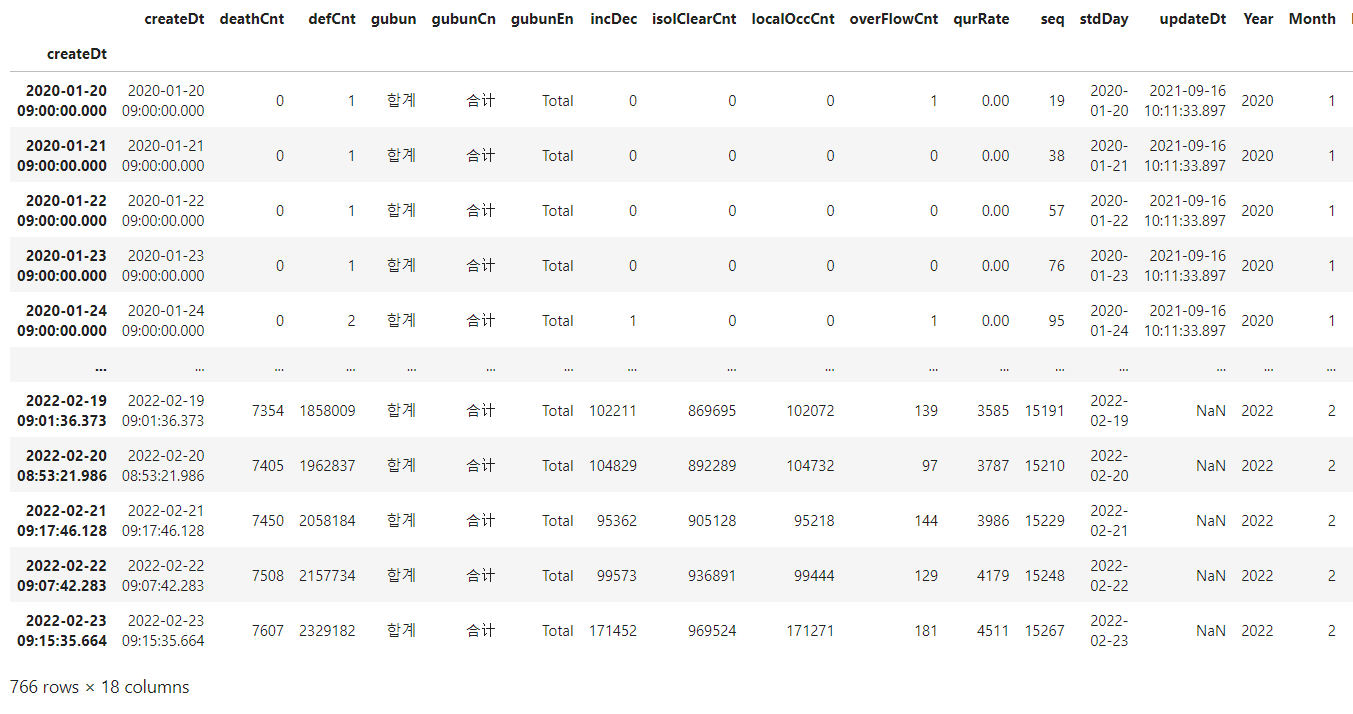
이렇게 createDt로 인덱스가 세팅 되었습니다.
또는 date_range를 사용해서도 날짜인덱스 설정이 가능한데,
주의할 점은 날짜형의 열을 index로 설정 후 reindex를 해야 한다는 점입니다.
pd.date_range(start = '시작날짜' , end= '종료날짜')
# 날짜 인덱스 설정 방법2(시간 범위): date_range
index_dates = pd.date_range(start=total_df['createDt'].min(), end=total_df['createDt'].max())
# or
index_dates = pd.date_range(start='2020-01-20', end='2022-02-23')
index_dates
# index_dates로 날짜형으로 변경하기
## reindex
# ※date range 사용 시에는 꼭 날짜형인 'createDt'열을 먼저 인덱스로 지정 후 아래와 같이 reindex 하기 ※
total_df.reindex(index_dates)
total_df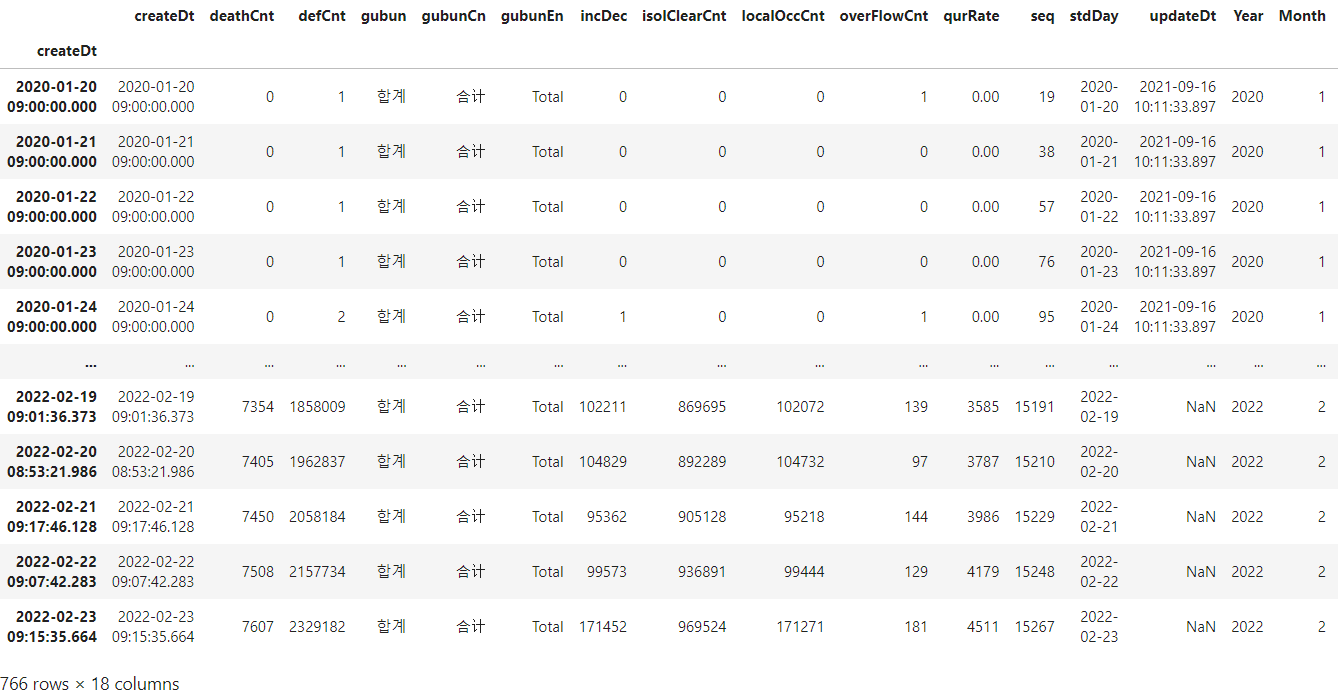
이렇게 인덱스가 날짜형으로 세팅되면 loc을 사용할 필요 없이 df['날짜']로 필요한 부분을 바로 추출할 수 있습니다.
#2020년도 12월 데이터만 추출하기
total_df['2020-12']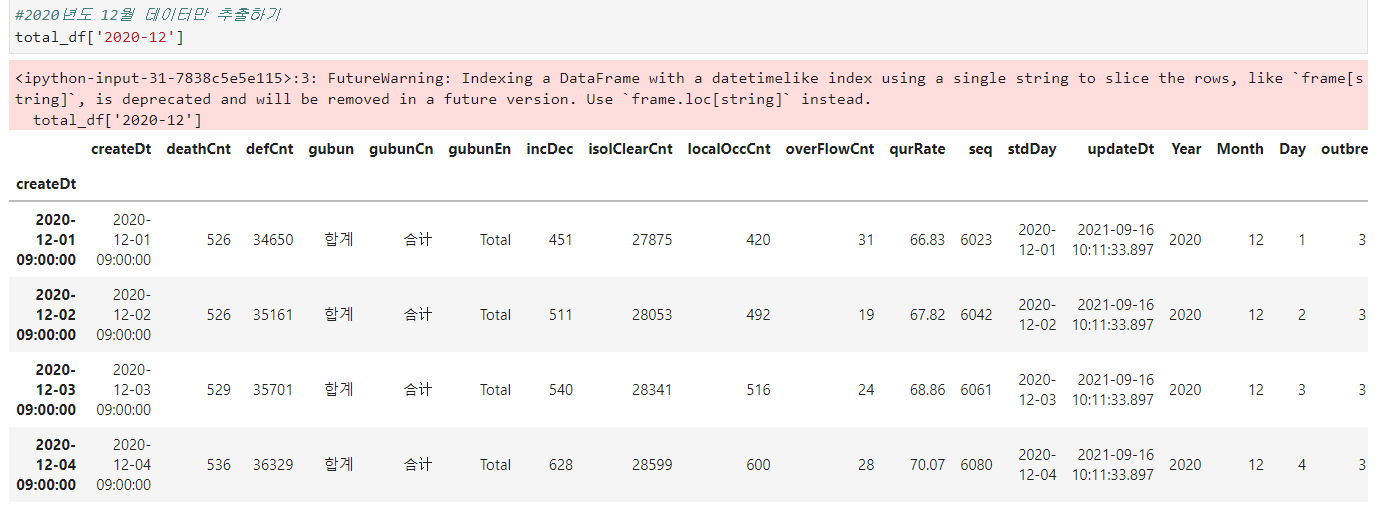
위의 .loc을 사용할 때보다 더욱 간편하게 원하는 기간의 추출이 가능합니다만,
위 사진 빨간 박스에 있는 경고메세지에서는 곧 이 기능이 사라진다고 하니 참고해 주시길 바랍니다.
loc을 사용하라고 권장하고 있네요.
시각화
마지막으로 위의 날짜로 인덱스를 세팅한 데이터프레임에서 전체 기간의 코로나 확진자 수(incDec)를 시각화 해보도록 하겠습니다.
# 확진자 수 시각화
#그래프 그리기
import matplotlib.pyplot as plt
ax = plt.subplots()
ax = total_df['incDec'].plot()
plt.show()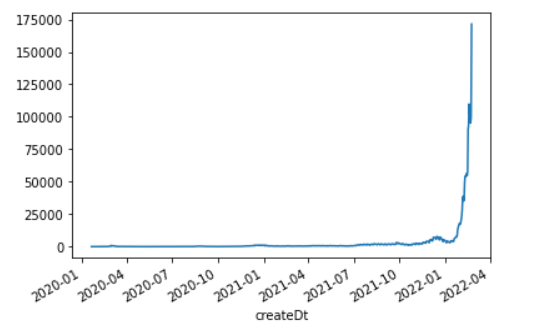
그래프도 볼 수 있듯이 2022년 들어서 확진자가 매우 가파르게 증가하는 것을 확인할 수 있습니다.
전체 코드
참고자료
1. pandas 공식문서
https://pandas.pydata.org/docs/user_guide/timeseries.html
Time series / date functionality — pandas 1.5.0 documentation
Time series / date functionality pandas contains extensive capabilities and features for working with time series data for all domains. Using the NumPy datetime64 and timedelta64 dtypes, pandas has consolidated a large number of features from other Python
pandas.pydata.org
2. [도서] Do it! 데이터 분석을 위한 판다스 입문(이지스 퍼블리싱)
마무리
이렇게 시계열 데이터 다루기 1편의 포스팅을 해 보았습니다.
생각보다 분량이 길어졌지만 시계열 데이터를 다룰 때 많은 도움이 될 것이라 생각합니다 :)