오늘은 머신러닝의 기초가 되는 알고리즘 중 하나인 회귀를 사용하여 문제를 해결하는 방법을 알아보도록 하겠습니다.
머신 러닝(Machine Learning)이란?
머신러닝은 기계학습이라고도 합니다.
수많은 데이터를 컴퓨터에게 학습시켜 그 속에 있는 패턴을 찾아내서 데이터를 사람의 도움 없이 분류하거나 미래를 예측하는 방법이라고도 할 수 있습니다.
머신러닝에서는 지도학습 비지도 학습, 강화학습 등으로 나뉘는데
회귀는 그 중에서도 지도학습에 속합니다.
머신러닝의 흐름
기계학습을 할 때는 보통 아래와 같은 흐름을 가지고 진행합니다.
- 데이터 수집 전처리
- 데이터 저장
- 데이터 학습(학습방법 선택, 매개변수 조정, 학습반복 등)
- 평가 및 검증
지도학습 이란?
지도학습은 간단히 말해서 기계를 학습할 때 정답을 같이 알려주어 학습하는 방법입니다.
사람이 공부를 할 때 문제지를 읽고 답을 채점하여 학습하는 것처럼
기계도 마찬가지로 어떤 데이터가 있으면 그것의 답을 같이 알려주어 학습을 시키는 방법입니다.
그리고 학습된 내용을 토대로 하여 다른 데이터의 답을 스스로 구할 수 있도록 합니다.

회귀(Regression)란?
지도학습에서 회귀(Regression)는 수치예측을 할때 쓰입니다.
정확히는 선형회귀(Linear Regression)가 쓰이는데 선형회귀는 아래와 같은 수식으로 나타낼 수 있습니다.
여기서 a는 기울기(slope), b는 절편(intercept)을 의미합니다.
회귀는 바로 위의 1차함수의 a,b값을 찾아 y값을 찾아내는 방법을 말합니다.
x는 독립변수가 되고 x에 의해 y가 정해지기 때문에 y는 x의 종속변수가 됩니다.
회귀 예제 - 학습 시간에 따른 시험 점수 예측
오늘은 회귀 예제로 학습시간에 따른 시험점수를 예측해 보도록 하겠습니다.
이번에 사용할 데이터는 kaggle에서 제공하는 단순한 공부 시간 및 점수를 가지고 학습 및 예측을 진행해 보겠습니다.
1. 데이터 준비
아래의 링크에서 csv파일을 다운받아 주세요.
https://www.kaggle.com/jahidsizansani/students-study-hour
Students Study Hour
www.kaggle.com
2. 데이터 확인
그럼 이제 pandas의 .shape() 와 head()를 사용하여 데이터를 확인해 보도록 하겠습니다.
## 판다스로 데이터 확인 ##
import pandas as pd
study = pd.read_csv('Student Study Hour V2.csv')
print(study.shape)
study.head()Student Study Hour V2.csv 는 28개의 행을 가지고 2개의 열(Hours(공부시간), Scores(점수))을 가졌음을 확인 가능합니다.
3. 독립 및 종속변수 설정
회귀를 사용할 때는 x, y값을 정해 주어야 하기 때문에 x(독립변수)는 공부시간, 우리가 구하고자 하는 점수를 y(종속변수)로 사용하도록 하겠습니다.
## 독립 및 종속변수 설정 ##
x_study = study[['Hours']]
y_study = study[['Scores']]
print(x_study.shape, y_study.shape)
print(x_study.head(2))
print(y_study.head(2))이렇게 28행 x 1열의 독립(x) 변수 및 종속(y) 변수를 설정하였습니다.
4. 모델 생성
이제 예측 값을 구하기위한 학습을 진행해 보겠습니다.
학습을 진행하려면 모델을 만들어 그 모델로 학습을 진행하게 됩니다.
우리는 간단히 경력이라는 데이터를 넣어 연봉 값을 구하고자 하기 때문에,
입력 = 1 크기의 층을 넣어주어 출력값(점수) 1개를 가지는 모델을 만들어 주도록 하겠습니다.
그리고 만들어진 모델에 대한 평가 함수로 MSE(Mean Squared Error, 평균 제곱 오차)를 사용하여 이 오차를 최소로 하는 a(기울기)와 b(절편값)를 찾아보도록 하겠습니다.
MSE는 수치예측 모델 평가 시에 주로 사용하며
x에 대한 (실제 y값- 예측값) 을 제곱하고 모두 더하여 평균을 구하는 함수입니다.
tensorflow를 사용하여 모델을 만들어 보겠습니다.
tensorflow가 설치가 안되어있다면
!pip install tensorflow 를 입력하여 설치 후 사용해 주세요.
#!pip install tensorflow
# 모델을 생성합니다.
import tensorflow as tf
X = tf.keras.layers.Input(shape=[1])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss="mse")그럼 이제 학습을 위한 모델 생성이 완료되었습니다.
5. 학습
이제 위에서 만들어진 모델을 가지고 학습을 진행하여 보겠습니다.
학습을 진행할 때에는 tensorflow의 .fit()메서드를 사용하여 학습을 진행합니다.
위에서 정한 독립, 종속 변수를 위에서 만든 모델을 넣고 15000번 학습을 진행해 보겠습니다.
verbose = 0으로 넣어주어 프로그레스를 생략하도록 하겠습니다.
시간이 오래 걸리지만 에포크당 손실이 어떻게 변하는지 확인하고 싶은 분은 verbose=1로 바꾸어 주세요.
# 모델에 데이터를 학습합니다.
model.fit(x_study, y_study, epochs=15000, verbose=0)학습된 모델이 어떻게 기울기와 절편이 설정되었는지 확인해 보고 싶으면, get_weights()를 사용하여 확인 가능합니다.
model.get_weights()[array([[9.676896]], dtype=float32), array([3.2012239], dtype=float32)]
위의 모델은 기울기(a)가 9.676896, 절편(b)가 3.2012239 입니다.
이것을 수식으로 나타내면
y(점수) = 9.676896 * x(공부시간) + 3.2012239 로 나타낼 수 있습니다.
6. 예측
이제 학습된 모델로 예측을 해 보겠습니다.
원래는 테스트셋을 학습, 테스트로 나누어 진행하여야 하지만 데이터셋의 양 자체가 적어 x값을 넣어 주고 그 결과를 잘 맞추었는지 확인하도록 하겠습니다.
# 모델을 이용합니다.
model.predict(x_study)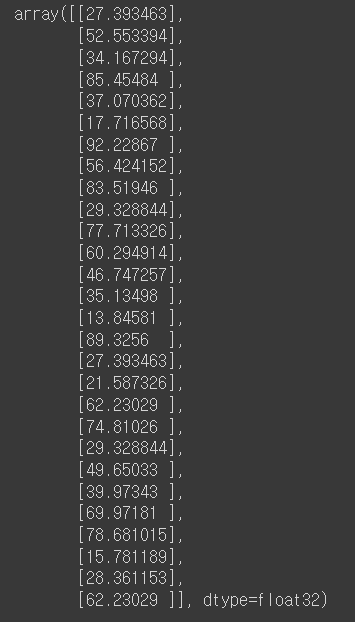
위의가 공부시간(x)에따른 y (점수)값입니다.
실제 y값은 아래와 같습니다.
#실제 y 값
y_salary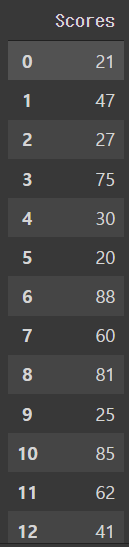
실제와 똑같지는 않지만 비슷하게 예측한 것을 확인할 수 있습니다. 더욱 정확한 예측값을 원한다면
epochs 를 더 늘려서 학습을 진행해 주시면 됩니다 :)
전체 코드
## 판다스로 데이터 확인 ##
import pandas as pd
study = pd.read_csv('Student Study Hour V2.csv')
print(study.shape)
study.head()
## 독립 및 종속변수 설정 ##
x_study = study[['Hours']]
y_study = study[['Scores']]
print(x_study.shape, y_study.shape)
print(x_study.head(2))
print(y_study.head(2))
## 모델을 생성합니다.
X = tf.keras.layers.Input(shape=[1])
Y = tf.keras.layers.Dense(1)(X)
model = tf.keras.models.Model(X, Y)
model.compile(loss="mse")
# 모델에 데이터를 학습합니다.
model.fit(x_study, y_study, epochs=15000, verbose=0)
#가중치 확인
model.get_weights()
# 모델을 이용합니다.
model.predict(x_study)
#실제 y 값
y_salary코드 파일
참고 자료
- https://opentutorials.org/course/4548
머신러닝1 - 생활코딩
수업소개 이 수업은 인공지능을 구현하는 기술인 머신러닝(Machine learning)을 다루는 수업입니다. 수업대상 인공지능과 머신러닝이 궁금한 분들 초등학생부터 어르신까지 누구나 수학과 코딩 때
opentutorials.org
- (책) 정직하게 코딩하며 배우는 딥러닝입문
'ML' 카테고리의 다른 글
| [python/ML] 회귀 - 경사하강법, 오차역전파 (2) | 2021.12.28 |
|---|