[NLP] LDA를 활용하여 토픽 트렌드 보기
안녕하세요.
저번 sklearn LDA 토픽 모델링 게시물에 이어서 이번에는 선정한 토픽에 대해
기간별로 어떻게 변화하는지를 확인해 보도록 하겠습니다.
데이터 준비
데이터는 저번 게시물에서 사용한 데이터를 사용하겠습니다.
- 데이터: 공공데이터 포탈의 '공정거래위원회_소비자 민원학습데이터 처리기관별 소비자 상담내역'
링크 들어가셔서
'공정거래위원회_소비자 민원학습데이터 처리기관별 소비자 상담내역_20211227.csv'
파일을 다운받아 주세요.
import pandas as pd
df = pd.read_csv('공정거래위원회_소비자 민원학습데이터 처리기관별 소비자 상담내역_20211227.csv',encoding='cp949')
print(df.head())
print(df.shape)
약 5만개의 행으로 이루어져 있습니다.
이 데이터에서 날짜 데이터도 있고 기타 데이터도 많지만,
토픽 모델링은 사건 제목을 가지고 해보도록 하겠습니다.
#토픽 토크나이저를 위해 필요한 부분 (사건제목) 추출
contents= df['사건제목(ACCIDENT_TITLE)']
contents
텍스트 토크나이징 및 카운트 벡터화
이제 이 텍스트를 가지고 sklearn을 사용하여 텍스트 토큰화 및 카운트 벡터화를 하겠습니다.
카운트 벡터는 sklearn.feature_extraction.text.CountVectorizer를 사용하여 생성할 수 있습니다.
저번 게시글과 마찬가지로, max_df=0.5로, min_df를 5로 지정하고 max_features 최대 2000개까지만 카운트벡터를 생성해 보겠습니다.
from konlpy.tag import Okt
from sklearn.feature_extraction.text import CountVectorizer
###형태소 분석###
okt = Okt()
def tokenizer(text):
#명사 추출, 2글자 이상 단어 추출
return [ word for word in okt.nouns(text) if len(word)>1]
Count_vector = CountVectorizer(tokenizer=tokenizer,
max_df = 0.5,
min_df = 5,
max_features = 2000)
%time minwon_cv = Count_vector.fit_transform(contents)
print(minwon_cv[:5])
print(minwon_cv.shape)
이렇게 minwon_cv라는 민원 제목과 관련된 카운트벡터를 만들었습니다.
최적 토픽 수 선정하기
이번에는 토픽 수를 선정해 보겠습니다.
sklearn를 사용하는 경우, 혼란도만 제공하고 있는데, tmtoolkit을 사용하면 응집도도 구할 수 있습니다.
토픽에 따른 혼란도, 응집도 및 토픽 내용을 print해주는 함수를 하나 만들어 실행해 보도록 하겠습니다.토픽 수는 3에서 10까지 늘려 값을 확인해 보겠습니다.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import LatentDirichletAllocation
from tmtoolkit.topicmod.evaluate import metric_coherence_gensim
# 토픽별 단어를 보여주는 함수
def print_top_words(model, feature_names, n_top_words):
for topic_idx, topic in enumerate(model.components_):
print("토픽 #%d: " % topic_idx, end='')
print(", ".join([feature_names[i]
for i in topic.argsort()[:-n_top_words -1:-1]]))
# 혼란도 및 응집도 구하는 함수
def calc_pv_coherence(countVector,vocab, start=5, end=30, max_iter=10,topic_wp=0.1, doc_tp=1.0):
num = []
per_value = []
cor_value = []
for i in range(start,end+1):
lda = LatentDirichletAllocation(n_components=i,max_iter=max_iter,
topic_word_prior=topic_wp,
doc_topic_prior=doc_tp,
learning_method='batch', n_jobs=-1,
random_state=0)
lda.fit(countVector)
num.append(i)
pv = lda.perplexity(countVector)
per_value.append(pv)
coherence_score = metric_coherence_gensim(measure='u_mass',
top_n=10,
topic_word_distrib=lda.components_,
dtm=countVector,
vocab=vocab,
texts=None)
cor_value.append(np.mean(coherence_score))
print(f'토픽 수: {i}, 혼란도: {pv:0.4f}, 응집도:{np.mean(coherence_score):0.4f}')
print_top_words(lda, vocab,10)
plt.plot(num,per_value,'g-')
plt.xlabel("topic_num")
plt.ylabel("perplexity")
plt.show()
plt.plot(num,cor_value,'r--')
plt.xlabel("topic_num")
plt.ylabel("coherence_score")
plt.show()
return per_value,cor_valueper_values, cor_values = calc_pv_coherence(minwon_cv,names,start=3,end=10)
이렇게 토픽 갯수별 토픽 단어들이 나오고,
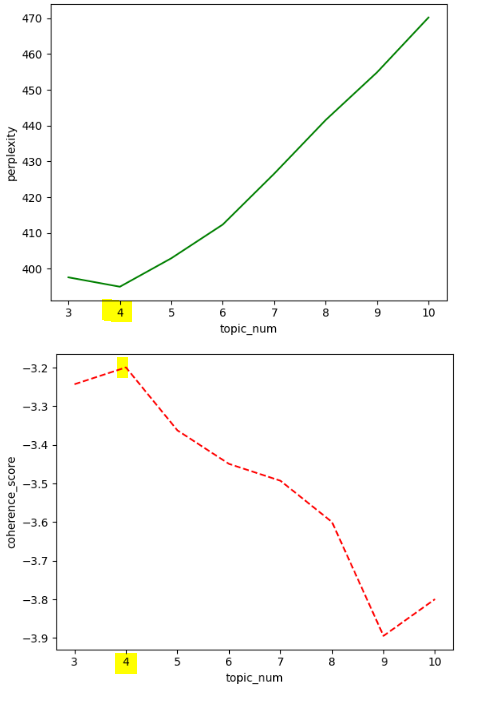
토픽별 혼란도, 응집도를 확인했을 때 최적의 토픽 수는 4 로 보입니다.
선정된 토픽 갯수로 LDA 토픽 모델링 하기
sklearn LDA를 사용해서 4개의 토픽을 가지고 있는 모델을 만들어 보겠습니다.
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(n_components=4,
n_jobs= -1,
random_state=0,
max_iter=10,
topic_word_prior=0.1,
doc_topic_prior=1.0,
learning_method='batch',
)minwon_topics = lda.fit_transform(minwon_cv)토픽 모델링 한 결과는 아래와 같습니다. 각 토픽별로 상위 20개 단어를 보도록 하겠습니다.
print_top_words(lda, Count_vector.get_feature_names_out(),20)
트렌드 확인하기
이제 이 민원 토픽들을 가지고 시간별로 어떤 종류의 토픽이 많이 나왔는지 확인하기 위한 트렌드 분석을 진행해 보겠습니다.
날짜 데이터는 '등록일자(RCPT_YMD)' 컬럼에 있습니다.
행이 5만개가 되기 때문에 날짜를 월단위까지만 자른 데이터를 토픽 분포 데이터와 합치도록 하겠습니다.
from sklearn.feature_extraction.text import CountVectorizer
trend_data = pd.DataFrame(minwon_topics,columns=['토픽'+str(i) for i in range(1,5)])
trend_data = pd.concat([trend_data,df['등록일자(RCPT_YMD)'].map(lambda x:x[:7])], axis=1)
trend_data.head()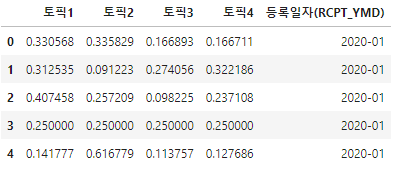
이후 groupby를 사용하여 월 단위로 토픽의 평균을 구해보겠습니다.
#월별 평균 구하기
trend = trend_data.groupby(['등록일자(RCPT_YMD)']).mean()
trend.head()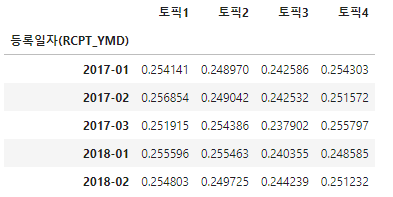
이제 월별로 토픽 비중이 어떻게 변했는지 확인하기 위해 matplotlib을 사용하여 그래프를 그려 보도록 하겠습니다.
matplotlib의 AutoDateLocator를 사용하여 x축은 6개월 단위로 눈금 및 값을 표시해서 보여주도록 하겠습니다.
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import font_manager,rc
from matplotlib.dates import AutoDateLocator,MonthLocator
# 한글 폰트 설정
font_location = 'C:/Windows/Fonts/MALGUNSL.TTF' #맑은고딕
font_name = font_manager.FontProperties(fname=font_location).get_name()
rc('font',family=font_name)
#날짜설정
locator = AutoDateLocator()
locator.intervald['MONTHLY'] = [6]
print_top_words(lda, Count_vector.get_feature_names_out(),20)
fig,axes = plt.subplots(2,2,figsize=(10,10))
for col,ax in zip(trend.columns.tolist(),axes.ravel()):
ax.set_title(col)
ax.xaxis.set_major_locator(locator)
ax.axes.xaxis.set_visible(True)
ax.plot(trend[col])
plt.show()
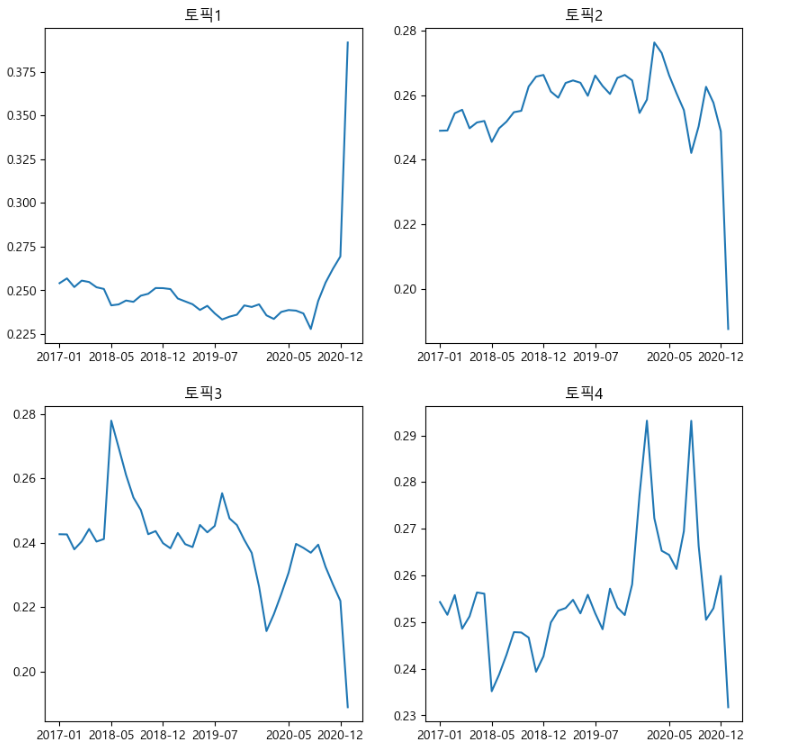
4개의 토픽에서 토픽별로 시간에 따라 분포가 어떻게 변화했는지 확인할 수 있습니다.
각 토픽 주제는 대략적으로
토픽 1: 피해 상담 문의
토픽2: 환불 및 반품 문의
토픽3: 수리 및 보상 문의
토픽4: 계약 해지 문의
이렇게 볼 수 있을 것 같습니다.
토픽1 은 최근에 급격히 비중이 늘어났고, 토픽 3번은 시간에 따라 비중이 줄어들고 있고, 토픽 4번은 후반부에 비중이 늘어남을 확인할 수 있습니다.
참고자료
1. 도서 - 파이썬 텍스트 마이닝 완벽 가이드(위키북스)
sklearn.decomposition.LatentDirichletAllocation
Examples using sklearn.decomposition.LatentDirichletAllocation: Topic extraction with Non-negative Matrix Factorization and Latent Dirichlet Allocation Topic extraction with Non-negative Matrix Fac...
scikit-learn.org
3. https://matplotlib.org/stable/api/dates_api.html
matplotlib.dates — Matplotlib 3.6.3 documentation
matplotlib.dates Matplotlib provides sophisticated date plotting capabilities, standing on the shoulders of python datetime and the add-on module dateutil. By default, Matplotlib uses the units machinery described in units to convert datetime.datetime, and
matplotlib.org