[NLP] 한국어 토픽 모델링 - LDA 활용방법(sklearn)
안녕하세요. 저번시간에는 토픽 모델링을 할 때 gensim으로 하는 방법을 알아보았는데,
이번에는 sklearn을 활용하여 LDA를 하는 방법을 알아보도록 하겠습니다.
데이터 준비
공공데이터 포탈의 '공정거래위원회_소비자 민원학습데이터 처리기관별 소비자 상담내역' 을 활용하여
LDA를 해보도록 하겠습니다.
아래의 링크에서 csv파일을 다운받아 주세요.
https://www.data.go.kr/data/15098351/fileData.do#tab-layer-file
공정거래위원회_소비자 민원학습데이터 처리기관별 소비자 상담내역_20211227
공정거래위원회의 소비자 민원학습 데이터로, 소비자들의 민원상담을 처리한 기관별 상담데이터를 보여주는 데이터입니다. 이 데이터는 기관명 상위기관을 포함하고 있습니다.
www.data.go.kr
import pandas as pd
df = pd.read_csv('공정거래위원회_소비자 민원학습데이터 처리기관별 소비자 상담내역_20211227.csv',encoding='cp949')
print(df.head())
print(df.shape)
약 5만개의 행으로 이루어져 있습니다.
여기서 사용할 컬럼은 사건 제목을 사용하여 토픽 모델링을 진행해 보도록 하겠습니다.
#토픽 토크나이저를 위해 필요한 부분 (사건제목) 추출
contents= df['사건제목(ACCIDENT_TITLE)']
contents
행별로 처리결과라는 카테고리가 있는데 그것이 몇개 있는지 확인해보도록 하겠습니다.
#카테고리 확인
df.groupby('처리결과명(PRCS_RESULT_NAME)').count()
print(len(df.groupby('처리결과명(PRCS_RESULT_NAME)').count()))27
총 27개의 카테고리가 있습니다.
텍스트 토크나이징 및 카운트 벡터화
이제 이 텍스트를 가지고 sklearn을 사용하여 텍스트 토큰화 및 카운트 벡터화를 하겠습니다.
카운트 벡터는 sklearn.feature_extraction.text.CountVectorizer를 사용하여 생성할 수 있습니다.
tokenizer 함수를 하나 만들어 주고,
CountVectorizer의 tokenizer에 해당 토큰화함수를 입력하고,
max_df는 gensim에서 사용했던 no_above처럼 일정 %이상 빈도가 너무 자주 등장하는 것을 제외하고,
min_df는 no_below처럼 몇 회 미만으로 나온 단어를 제외합니다.
이번에는 max_df=0.5로, min_df를 5로 지정하고 max_features 최대 2000개까지만 카운트벡터를 생성해 보겠습니다.
from konlpy.tag import Okt
from sklearn.feature_extraction.text import CountVectorizer
###형태소 분석###
okt = Okt()
def tokenizer(text):
#명사 추출, 2글자 이상 단어 추출
return [ word for word in okt.nouns(text) if len(word)>1]
Count_vector = CountVectorizer(tokenizer=tokenizer,
max_df = 0.5,
min_df = 5,
max_features = 2000)
%time minwon_cv = Count_vector.fit_transform(contents)
print(minwon_cv[:5])
print(minwon_cv.shape)
이렇게 minwon_cv라는 민원 제목과 관련된 카운트벡터를 만들었습니다.
최적 토픽 수 선정을 위해 혼란도, 응집도 구하기
이번에는 토픽 수를 선정해 보겠습니다.
sklearn의 경우, 혼란도만 제공하고 있는데, tmtoolkit을 사용하면 응집도도 구할 수 있습니다.
tmtoolkit 설치는 아래의 명령어를 입력하여 터미널에서 설치해 주시면 됩니다.
pip install --user tmtoolkitsklearn에서 LDA는 sklearn.decomposition.LatentDirichletAllocation 을 사용하여 구할 수 있습니다.
sklearn LDA의 n_components는 추출할 토픽의 수를 의미하고,
max_iter는 알고리즘의 최대 반복 횟수(gensim의 passes라고 생각하면 됩니다.),
topic_word_prior은 베타값(토픽의 사전 단어분포),
doc_topic_prior은 알파값(문서의 사전 토픽분포),
learning_method는 학습방법으로 online과 batch가 있습니다.
n_jobs는 모델 사용시 사용하는 프로세서의 수를 의미하며 -1로 설정하면 모든 프로세서를 사용할 수 있습니다.
이번에는 max_iter를 10으로 설정하고,
topic_word_prior와 doc_topic_prior은 아래의 논문
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC387300/
Colloquium Paper: Mapping Knowledge Domains: Finding scientific topics
A first step in identifying the content of a document is determining which topics that document addresses. We describe a generative model for documents, introduced by Blei, Ng, and Jordan [Blei, D. M., Ng, A. Y. & Jordan, M. I. (2003) J. Machine ...
www.ncbi.nlm.nih.gov
을 참고하여 각각 0.1, 1.0으로 설정해 보도록 하겠습니다.
random_state는 0으로 설정해준 뒤,
n_components는 5부터 30까지의 값을 넣어 실행한 뒤,
혼란도, 응집도 값을 각각 구해 matplotlib으로 시각화 해보도록 하겠습니다.
혼란도는 sklearn LDA 모형의 .perplexity로 값을 구하고,
응집도는 tmtoolkit.topicmod.evaluate.metric.coherence_gensim을 사용하여 구하도록 하겠습니다.
coherence score에서 measure은 'u_mass'를 사용하였습니다.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import LatentDirichletAllocation
from tmtoolkit.topicmod.evaluate import metric_coherence_gensim
def calc_pv_coherence(countVector,vocab, start=5, end=30, max_iter=10,topic_wp=0.1, doc_tp=1.0):
num = []
per_value = []
cor_value = []
for i in range(start,end+1):
lda = LatentDirichletAllocation(n_components=i,max_iter=max_iter,
topic_word_prior=topic_wp,
doc_topic_prior=doc_tp,
learning_method='batch', n_jobs=-1,
random_state=0)
lda.fit(countVector)
num.append(i)
pv = lda.perplexity(countVector)
per_value.append(pv)
coherence_score = metric_coherence_gensim(measure='u_mass',
top_n=10,
topic_word_distrib=lda.components_,
dtm=countVector,
vocab=vocab,
texts=None)
cor_value.append(np.mean(coherence_score))
print(f'토픽 수: {i}, 혼란도: {pv:0.4f}, 응집도:{np.mean(coherence_score):0.4f}')
plt.plot(num,per_value,'g-')
plt.xlabel("토픽 수:")
plt.ylabel("혼란도: ")
plt.show()
plt.plot(num,cor_value,'r--')
plt.xlabel("토픽 수:")
plt.ylabel("응집도: ")
plt.show()
return per_value,cor_value함수를 이렇게 만들고 아래와 같이 호출해 줍니다.
per_values, cor_values = calc_pv_coherence(minwon_cv,Count_vector.get_feature_names_out(),start=5,end=30)시작 토픽은 5, 끝나는 토픽 수는 30으로 설정한 뒤 실행해 줍니다.
여기서 시간이 2~3시간정도 걸릴 수 있습니다.

이렇게 각 토픽에 대한 혼란도, 응집도가 나오고,
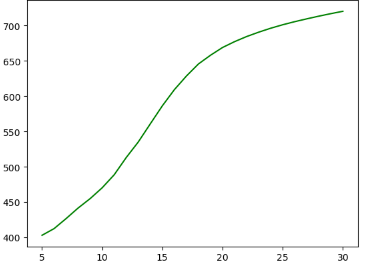
위의 그래프는 토픽 수에 따른 혼란도를,
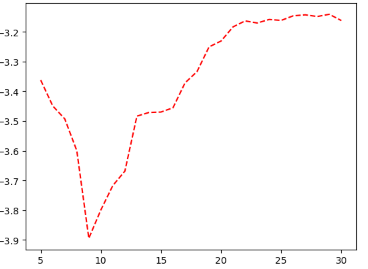
이 그래프는 토픽 수에 따른 응집도(u_mass)를 보여 줍니다.
여기서 적절한 토픽 수 찾기가 좀 어려웠는데요,
혼란도는 적을수록 좋은데 이 그래프에서는 토픽수가 늘어날수록 혼란도도 늘어나고,
응집도는 0에 가까울수롤 좋은데 응집도 그래프에서는 토픽이 29개일 때 응집도가 가장 0에 가깝기 때문입니다.
저는 여기서 응집도를 기준으로 가장 높았던 토픽 수 29로 설정해 보았습니다.
만약 다른 갯수로 설정하고 싶다면 n_components를 해당 토픽 갯수로 바꿔서 진행하면 됩니다.
결정된 토픽 수로 토픽 모델링 하기
lda = LatentDirichletAllocation(n_components=29,
n_jobs= -1,
random_state=0,
max_iter=10,
topic_word_prior=0.1,
doc_topic_prior=1.0,
learning_method='batch')%time minwon_topics = lda.fit_transform(minwon_cv)토픽 수 29로 LDA모델을 만들고 fit한 후 토픽을 뽑아보면,
for topic_idx, topic in enumerate(lda.components_):
print("토픽 #%d: " % topic_idx, end='')
print(", ".join([Count_vector.get_feature_names_out()[i] for i in topic.argsort()[:10]]))
이렇게 결과가 나옵니다. 하지만 이는 비중이 작은 순서라서 다시 가장 비중이 큰 10개만 다시 뽑아보면,
for topic_idx, topic in enumerate(lda.components_):
print("토픽 #%d: " % topic_idx, end='')
print(", ".join([Count_vector.get_feature_names_out()[i] for i in topic.argsort()[:-11:-1]]))
비슷한 단어가 많이 겹치는 것을 확인할 수 있습니다.
단순히 응집도 점수만 봤을 때 이런 결과가 나오니 다른 토픽 수도 확인하여 결정하는 것이 좋을 것 같습니다.
참고자료
1. 도서 - 파이썬 텍스트 마이닝 완벽 가이드(위키북스)
sklearn.decomposition.LatentDirichletAllocation
Examples using sklearn.decomposition.LatentDirichletAllocation: Topic extraction with Non-negative Matrix Factorization and Latent Dirichlet Allocation Topic extraction with Non-negative Matrix Fac...
scikit-learn.org
3. https://alvinntnu.github.io/NTNU_ENC2045_LECTURES/nlp/topic-modeling-naive.html#additional-notes
2. Topic Modeling: A Naive Example — ENC2045 Computational Linguistics
Simple Text Pre-processing Depending on the nature of the raw corpus data, we may need to implement more specific steps in text preprocessing. In our current naive example, we consider: removing symbols and punctuations normalizing the letter case strippin
alvinntnu.github.io