[NLP/영어] 사전학습된 BERT 모형의 기본 사용법 : pipeline()
안녕하세요.
오늘 포스팅은 전에 알아보았던 BERT의 사전학습된 모형을 사용하는 간단한 방법을 알아보도록 하겠습니다.
BERT 사전학습 모델은 허깅페이스(Hugging Face)에서 제공해서 사이트를 이용해보도록 하겠습니다.
1. 라이브러리 설치
anaconda prompt 또는 기타 터미널 창을 열어 transformers 라이브러리를 설치해 주세요.
CPU환경에서 사용할 것이므로 아래의 명령어를 입력해 줍니다.
pip install transformers
만약 다운로드 중 권한 오류가 있다면 관리자 권한으로 실행하시길 바랍니다.
가상환경으로 실행하고 싶은 분들은 사용할 가상환경 activate 후 설치하시면 됩니다.
2. transformers 파이프라인(pipeline)
transformers 라이브러리에서는 pipeline(파이프라인) 클래스를 제공하는데요,
이 클래스를 사용하면 알아서 입력값을 토크나이저를 이용해 BERT에 맞는 입력으로 변환하여 주고,
BERT 사전학습 모델에 전달하여 예측값을 반환합니다.
때문에 코드 몇 줄 만으로 간단히 사전학습 모델을 사용할 수 있습니다.
pipeline에서 지원하는 사전학습 모델 종류는 아래와 같습니다.
1. Sentiment-analysis : 감정분석
2. Text-generation : 텍스트 생성
3. NER(Named entity recognition): 개체명 인식
4. Question-answering : 기계독해
5. Fill-mask : 빈칸 예측하기
6. Summarization : 문서 요약하기
7. Translation : 번역하기
이번에 입력하는 텍스트는 영어로 입력하여야 합니다.
이제 위의 7가지 사전학습 모델 간단 사용법을 각각 알아보도록 하겠습니다.
참고로, 각 모델을 사용하며 입력한 문장 몇개들은 위키피디아에서 가져왔습니다.
2.1 감정분석
감정분석은 텍스트에 대해 긍정적인 감정을 담고 있는지 부정적인 감정을 담고 있는지 예측하는 모델입니다.
예시)
1. 이 영화는 재미있다 -> positive(긍정)
2. 이 음식은 맛없다. -> negative(부정)
사용방법: pipeline('sentiment-analysis')
from transformers import pipeline
# text classification : 감정분석
classifier= pipeline('sentiment-analysis')
sentence = "I can't wait for watching this movie!" #감성분석하고 싶은 문장 입력
result = classifier(sentence)[0]
print("입력문장: ",sentence)
print('감성분석결과: %s, 감성스코어: %0.2f'%(result['label'],result['score']))
여기서는 I can't wait for watching this movie!(이 영화를 빨리 보고 싶어!) 라는 문장을 예시로 넣어 보았습니다.
그 후 분석결과와 감성 스코어를 소숫점 2자리수까지 출력하도록 설정하였습니다.
그 결과 이 문장은 POSITIVE(긍정적)인 문장이며 점수 역시 1.00이 나왔습니다.
점수는 0~1 사이로, 점수가 1에 가까워질수록 긍정적이라고 할 수 있습니다.
2.2 텍스트 생성
텍스트 생성은 어느 한 텍스트를 입력 받아 그 뒤의 문장을 만들어 줍니다.
예시)
입력 문장: 나는 사과를 먹었다.
텍스트 생성: 나는 사과를 먹었다. 그래도 아직 배가 고파서 바나나를 먹었다.
사용방법: pipeline('text-generation')
# text generation : 문장 생성
text_generator = pipeline('text-generation')
sentence = "I was sitting on my bed."
result = text_generator(sentence)
print("생성된 문장: ",result[0]['generated_text'])
입력 문장으로
"I was sitting on my bed."(나는 내 침대 위에 앉아 있었다.)를 입력 후
텍스트 생성을 하니,
I was sitting on my bed. I could see the moon and it was beautiful. I was sitting on my pillow. It was gorgeous. I looked at my bed. I was wearing my jeans at the side and the top. It was so nice
(나는 침대 위에 앉아 있었다. 나는 달을 볼 수 있었고 그것은 아름다웠다. 나는 베개 위에 앉아있었다. 정말 황홀했다. 나는 침대를 바라봤다. 나는 청바지를 입고 있었다. 너무 좋았다.)
입력된 문장에 이어서 위와 같은 문장을 출력하였습니다.
출력 결과는 실행할 때마다 매번 달라집니다.
2.3 개체명 인식
개체명 인식(NER: Named entity recognition)이란 입력된 텍스트 속에 사람 이름, 단체 이름 등과 같이 고유한 의미가 있는 단어를 찾아 분류하는 기술입니다.
예시)
입력 -> 영희는 이번에 애플에서 새로 출시한 아이폰을 샀다.
출력 -> 영희: 사람 이름, 애플: 회사 이름, 아이폰: 물건 이름
transformers에서 인식하는 개체는 아래와 같습니다.
[토큰 설명]
O : Outside of a named entity (NER에서 인식범위를 벗어난 개체)
B-MIS : Beginning of a miscellaneous entity right after another miscellaneous entity
(기타 개체 바로 뒤에 오는 기타 개체의 시작)
I-MIS : Miscellaneous entity(기타 개체)
B-PER : Beginning of a person’s name right after another person’s name
(사람 이름 바로 뒤에 오는 사람 이름의 시작)
I-PER : Person’s name(사람 이름)
B-ORG : Beginning of an organisation right after another organisation
(단체 이름 바로뒤에오는 단체 이름의 시작)
I-ORG : Organisation (단체)
B-LOC : Beginning of a location right after another location(지리적 위치 바로 뒤에 오는 위치의 시작)
I-LOC : Location (지리적 위치)
사용방법: pipeline('ner')
ner = pipeline('ner')
sentence = 'BTS is a South Korean boy band formed in 2010 and debuting in 2013 under Big Hit Entertainment.'
result = ner(sentence)
print(sentence)
for i in range(len(result)):
print("-단어: ",result[i]['word'],", 구분: ",result[i]['entity'],end=' ')
입력 문장으로
(BTS는 2010년에 결성된 아이돌이며 빅히트 엔터테인트먼트에서 2013년도에 데뷔하였다.)
라는 문장을 입력하여 아래와 같은 개체명 인식 결과가 나왔습니다.
-단어: BT , 구분: I-ORG
-단어: ##S , 구분: I-ORG
-단어: South , 구분: I-MISC
-단어: Korean , 구분: I-MISC
-단어: Big , 구분: I-ORG
-단어: Hit , 구분: I-ORG
-단어: Entertainment , 구분: I-ORG
BTS, Big Hit Entertaintment를 단체라고 구분하였습니다. South Korean은 기타로 분류하였네요.
2.4 기계독해
기계독해는 우리가 국어 지문을 읽고 문제를 푸는 것처럼
어떠한 문서가 있으면 그것을 입력 값으로 주고 지문과 관련한 질문을 해서 맞추는 것을 말합니다.
예시)
입력: "레몬은 신맛이 나는 과일이다."
질문: "신맛이 나는 과일은?"
답: "레몬"
사용방법: pipeline('question-answering')
# Question answering : 기계독해
question_answering = pipeline("question-answering")
context = """
Shake Shack is an American fast casual restaurant chain based in New York City. It started out as a hot dog cart inside Madison Square Park in 2001, and its popularity steadily grew.
In 2004, it received a permit to open a permanent kiosk within the park, expanding its menu from New York–style hot dogs to one with hamburgers, hot dogs, fries and its namesake milkshakes.
Since its founding, it has been one of the fastest-growing food chains, eventually becoming a public company filing for an initial public offering of stock in late 2014. The offering priced on January 29, 2015; the initial price of its shares was at $21, immediately rising by 123% to $47 on their first day of trading.
Shake Shack Inc. owns and operates over 400 locations globally.
"""
question = "How many locations Shake Shack Inc. operates?"
result = question_answering(question=question,context=context)
print("지문: ", context)
print("문제: ",question)
print("답: ", result['answer'])
지문으로 셰이크쉑에 대한 위키피디아 지문을 넣었습니다.
그 후 질문으로 "쉐이크쉑은 얼마나 많은 가게를 운영하고 있나?" 라는 질문을 했고
그 결과 "over 400(400개 이상)"이라는 답을 받았습니다.
2.5 빈칸 예측하기
빈칸 예측하기(fill-mask)는 문장에 마스킹 처리를 해 놓고 그 안에 들어갈 단어가 무엇일지 예측하는 모델입니다.
예시)
문장: 나는 자러 [ ]에 간다.
예측 : 나는 자러 [침대]에 간다.
사용방법: pipeline('fill-mask')
transformers에서는 해당 모델 사용 시
마스킹 하는 부분을 fill_mask객체.tokenizer.mask_token 로 설정하여 사용합니다.
# Fill-mask : 빈칸 예측하기
from pprint import pprint
fill_mask = pipeline("fill-mask")
sentence = f"AlphaGo is a computer {fill_mask.tokenizer.mask_token} that plays the board game Go."
result = fill_mask(sentence)
print("문장: ",sentence)
pprint(result)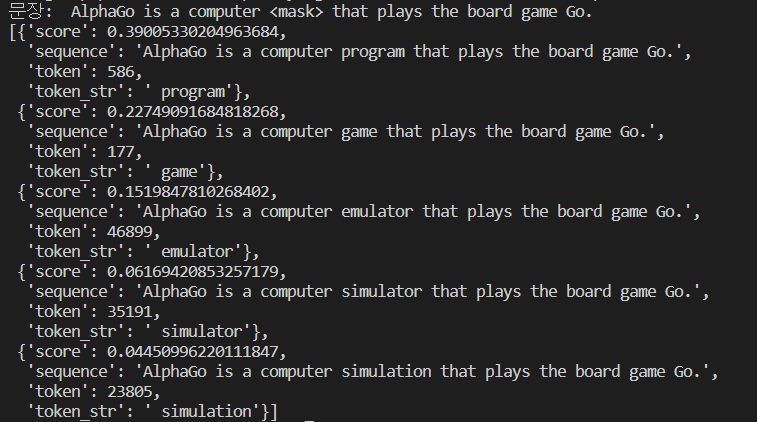
문제로 위키피디아에서 설명하는 알파고에 대한 문장 중 하나를 가져왔습니다.
"알파고는 보드게임 Go 를 하는 컴퓨터 <mask>이다."
라고 입력값을 주었고, 원래 문장은 "알파고는 보드게임 Go 를 하는 컴퓨터 프로그램(program)이다." 였습니다.
그 결과값으로는 빈칸에 들어갈 수 있는 여러 단어가 출력이 되었습니다.
위에서 부터 차례대로 점수가 높은 순이며,
program, game, emulator, simulator, simulation 등의 단어가 들어갈 수 있다고 예측하였습니다.
2.6 문서 요약하기
문서 요약(summarization)은 말 그대로 긴 문서를 몇 문장으로 요약하는 것을 말합니다.
예시)
문서: 전국이 대체로 흐린 가운데 오전 중부지방을 시작으로 눈이 내렸다. 오후서울 등 수도권과 강원 일부 지방은 최대 10㎝ 이상의 많은 눈이 예상돼 대설특보가 발효됐다. 기상청은 이날 "오늘 오전부터 강원중·남부동해안을 제외한 중부지방부터 비 또는 눈이 시작돼 오후부터 전북, 경북북부내륙, 경북남서내륙, 경남서부내륙, 밤부터 전남권북부에 비 또는 눈이 오는 곳이 있겠다"며 "수도권과 충남북부는 늦은 오후에 대부분 그치겠고, 그 밖의 지역은 밤에 대부분 그치겠다"고 밝혔다. (출처: https://n.news.naver.com/mnews/article/003/0011593636?sid=103)
요약: 새벽부터 내린 비나 눈이 점차 확대되면서 경기동부와 강원영서에는 최고 10cm 이상의 많은 눈이 쌓이겠다. 낮 동안 소강상태를 보이는 곳이 많겠으나 저녁부터 다시 강해져 모레 월요일 출근길이 빙판길로 변할 가능성이 높다. 이번 눈이나 비는 짧은 시간 강하게 내리다가 그치는 형태라 강수량보다는 적설량이 많을 것으로 보인다.
사용방법: pipeline('summarization')
min/max_length으로 최소/최대 길이를 조정할 수 있습니다.
# Summarization : 문서 요약하기
summerizer = pipeline('summarization')
article = """An apple is an edible fruit produced by an apple tree (Malus domestica). Apple trees are cultivated worldwide and are the most widely grown species in the genus Malus. The tree originated in Central Asia, where its wild ancestor, Malus sieversii, is still found today. Apples have been grown for thousands of years in Asia and Europe and were brought to North America by European colonists. Apples have religious and mythological significance in many cultures, including Norse, Greek, and European Christian tradition.
Apples grown from seed tend to be very different from those of their parents, and the resultant fruit frequently lacks desired characteristics. Generally, apple cultivars are propagated by clonal grafting onto rootstocks. Apple trees grown without rootstocks tend to be larger and much slower to fruit after planting. Rootstocks are used to control the speed of growth and the size of the resulting tree, allowing for easier harvesting.
There are more than 7,500 known cultivars of apples. Different cultivars are bred for various tastes and uses, including cooking, eating raw, and cider production. Trees and fruit are prone to a number of fungal, bacterial, and pest problems, which can be controlled by a number of organic and non-organic means. In 2010, the fruit's genome was sequenced as part of research on disease control and selective breeding in apple production.
Worldwide production of apples in 2018 was 86 million tonnes, with China accounting for nearly half of the total."""
result = summerizer(article,max_length=150,min_length=50)
print("문서: ",article)
print("요약: ",result[0]['summary_text'])
입력 문서로 위키피디아에 '사과' 문서를 사용하였습니다.
요약으로 긴 문장을 3문장 정도로 축약한 것을 확인할 수 있습니다.
2.7 번역
번역(Translation)은 어떠한 나라의 언어에서 다른 나라의 언어로 통역해주는 모델을 말합니다.
예시)
한국어: 나는 사과를 좋아한다.
↓
영어: I like apples.
사용방법: pipeline('translation_언어_to_언어')
transformers에서 제공하는 번역은 영어-독일어(en_to_de), 영어-루마니아어(en_to_ro) 입니다.
여기서는 영어-독일어 번역(translation_en_to_de)을 사용해 보도록 하겠습니다.
# Translation : 번역하기
translator = pipeline('translation_en_to_de')
sentences = "Bitcoin is a decentralized digital currency that can be transferred on the peer-to-peer bitcoin network."
result = translator(sentences, max_length=50)
print("영어: ",sentences)
print("독어: ",result[0]['translation_text'])
영어 입력문장은 위키피디아 비트코인 문서에서 가져온 문장을 사용하였습니다.
출력 값으로 독일어 번역이 된 문장을 반환합니다.
참고자료
https://huggingface.co/docs/transformers/task_summary#translation
Summary of the tasks
>>> from transformers import pipeline >>> text_generator = pipeline("text-generation") >>> print(text_generator("As far as I am concerned, I will", max_length=50, do_sample=False)) [{'generated_text': 'As far as I am concerned, I will be the first to admit
huggingface.co
마무리
이번에 간단하게 사전학습된 BERT모형 사용법을 알아보았습니다.
기본 제공이 영어라 한국어 적용도 해보고 싶어서
다음 포스팅에서는 한국어로 사용할 수 있는 방법을 알려드리도록 하겠습니다.