[NLP] 감성분석이란?
안녕하세요! 포스팅을 오랜만에 하네요.
오늘은 감성분석이 무엇인지, 또 어떤 방법으로 감성분석을 할 수 있는지 같이 알아보도록 하겠습니다.
감성분석(Sentiment Analysis)이란?
감성분석(Sentiment Analysis)은 여러 종류의 글(텍스트) 안에 있는 감성을 분석하는 것입니다.
그렇다면 감성(Sentiment)이란 무엇일까요?
감성(Sentiment)은 감정(Emotion)이라고도 할 수 있고, 감정은 주관적입니다.
예를 들어, 아래 나비사진을 봅시다.

같은 나비를 보더라도 어떤 사람은 아름답다고 생각하는 긍정적인 반응을 보이는 한편,
곤충을 싫어하는 사람에게는 나비의 무늬가 징그럽다고 생각하는 부정적인 반응을 보일 수 도 있습니다.
또는 아무 생각 없이 그냥 나비구나 하는 사람도 있을 것입니다. 이것을 중립적으로 본다고 하겠습니다.
또한 감성은 텍스트에서도 나타납니다.
"해리포터 책은 마치 마법사가 실존하는 것처럼 생생하게 묘사한다." 라는 문장이 있을 때,
어떤 사람은 이 문장을 긍정적으로 볼 것이며, 어떤 사람은 중립적으로 볼 수도 있을 것입니다.
반면, "이 영화는 재미가 없다."라는 문장은 부정적으로 볼 가능성이 클 것입니다.
감성 분류
텍스트를 감성 분석할 때, 감성을 3가지로 분류할 수 있습니다.
1. 이 텍스트가 긍정(Positive)인지
2. 중립(Neutral)인지
3. 아니면 부정(Negative) 인지
때로는 긍정, 부정 2가지만으로 분류하여 분석할 때도 있습니다.
이런 감성의 정도를 극성(Polarity)라고 합니다.
긍정, 중립, 부정 을 그림으로 나타내면 아래와 같이 표현할 수 있습니다.

0은 중립, +(양수)는 긍정, -(음수)는 부정을 나타냅니다.
감성 분석 방법
감성 분석을 하는 방법은 여러 가지가 있지만 크게 2가지로 나눈다면
1. 감성 사전을 활용한 감성분석
2. 기계학습(Machine Learning)을 사용하는 감성분석
으로 나눌 수 있습니다.
1. 감성사전을 활용한 감성분석
감성 사전은 명사, 형용사, 동사의 모든 단어들을 긍정 또는 부정으로 라벨링 하여 구축할 수 있습니다.
감성 사전은 직접 구축할 수도 있고(시간이 많이 걸립니다.), 기존에 만들어진 사전을 사용할 수도 있습니다.
감성사전을 기반으로 문장의 감성을 파악할 때는 아래와 같이 분류할 수 있습니다.

어떤 문장이 있다면 그 문장을 명사, 동사, 형용사 기준으로 형태소 분석을 하여
사전에 구축된 감성 사전에서 해당 단어와 매칭 되는 점수를 찾아
전부 더해서 최종적으로 나온 점수를 기준으로 문장의 감성을 판단할 수 있습니다.
그렇다면 아래의 문장은 어떻게 판단될까요?
"해리포터 영화의 영상미가 좋다고 해서 영화가 좋은 것은 아니다."
위에서 단순히 사전에서 매칭 되는 단어를 찾아 그 점수를 각각 더한다면

위와 같이 최종적으로 1점이 되어 긍정 문장으로 판단이 될 것입니다.
하지만 문장 전체를 보면 과연 긍정적이라고 판단할 수 있을까요?
이러한 오류를 방지하고자 문장을 구로 묶어서 단계적으로 감성을 판단하는 방법을 사용할 수도 있습니다.
이를 청킹(chunking)이라고 합니다.
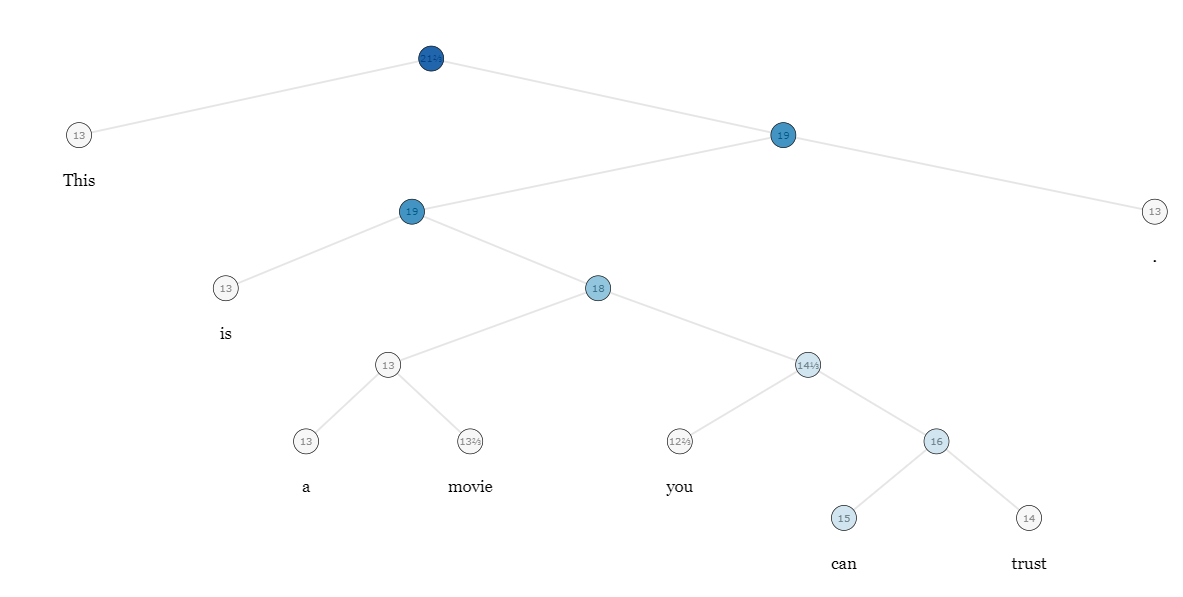
아래는 스탠포드에서 제공하는 트리 감성분석 입니다.
파란색일수록 긍정적이며, 붉을수록 부정적임을 나타냅니다.
https://nlp.stanford.edu/sentiment/treebank.html?w=this%2Cmovie&na=3&nb=10
Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank
Displaying N sentences that satisfy the following criteria.
nlp.stanford.edu
2. 기계학습(Machine Learning)을 사용하는 감성분석
기계학습을 이용하여 감성분석을 할 때에는 학습 셋이 필요합니다.
머신러닝의 지도학습으로, 각 텍스트 데이터에는 긍정인지 부정인지를 구분하는 라벨링을 해주어야 합니다.
각 테스트 데이터는 문제, 라벨 데이터는 답이라고 할 수 있습니다.
그 후 train, test 데이터로 나누어 train 데이터를 가지고 학습을 하고, test 데이터로 학습이 잘 되었는지 검증합니다.
또한 train데이터를 가지고 여러 알고리즘을 사용하여 최적의 학습이 된 모델로
새로운 문장이 긍정인지 부정인지 예측할 수도 있습니다.

기계학습 기반의 감성분석은 학습데이터가 매우 중요합니다.
만약 영화 리뷰를 가지고 학습을 한 모델을 가지고 영화 리뷰와 관련된 문장을 예측하는 것은 예측 정확도가 높을 수 있습니다.
하지만 그 모델을 그대로 의료 서비스 리뷰에 적용을 한다면 이때의 문장 감성분석 정확도는 장담할 수 없습니다.
이럴 때는 주제에 맞게 모델을 수정하여 예측하여야 합니다.
참고자료
위키북스 - 파이썬 텍스트 마이닝 완벽 가이드: 자연어처리 기초부터 딥러닝 기반 BERT 모델까지
마무리
이렇게 간단하게 감성분석에 대해 알아보았습니다.
다음 포스팅에는 python 감성 분석 실습과 관련하여 글을 업로드하도록 하겠습니다.