[python] 네이버 뉴스 크롤러(날짜,링크,제목, 본문)
안녕하세요. 정말 오랜만의 포스팅입니다.
그동안 올렸던 네이버 뉴스 크롤러 최신 버전을 공유드리고자 합니다.
그 전 버전인 아래 포스팅에서는
https://wonhwa.tistory.com/46#comment18426434
[python] 원하는 검색어로 네이버 뉴스 기사 제목 및 내용만 크롤링하기
안녕하세요! 크롤링 포스팅을 오랜만에 진행하네요~ 이번에는 네이버 뉴스 검색 결과중 네이버 뉴스에 기사가 있는 링크들만 가져와 크롤링을 진행해 보도록 하겠습니다. 지난 크롤러에서 아쉬
wonhwa.tistory.com
Selenium을 사용하여 크롤러를 만들었지만 날짜 내용이 빠지고 Selenium을 가동 시간이 길어 다소 불편한 점도 있었습니다.
그래서 이번에는 Selenium을 사용하지 않고 바로 주소를 파싱하여 네이버 뉴스 크롤링 하는 방법을 공유드리고자 합니다.
크롤링 제작의 자세한 내용은 그 전 포스팅에 나와있으니
자세한 설명이 필요하신 분들은 제 블로그 Crawling 카테고리에서 확인해 주시면 됩니다:)
그럼 시작하도록 하겠습니다.
1. 라이브러리 불러오기
#크롤링시 필요한 라이브러리 불러오기
from bs4 import BeautifulSoup
import requests
import re
import datetime
from tqdm import tqdm
import sys
2. 크롤링 시 필요한 함수 만들기
# 페이지 url 형식에 맞게 바꾸어 주는 함수 만들기
#입력된 수를 1, 11, 21, 31 ...만들어 주는 함수
def makePgNum(num):
if num == 1:
return num
elif num == 0:
return num+1
else:
return num+9*(num-1)
# 크롤링할 url 생성하는 함수 만들기(검색어, 크롤링 시작 페이지, 크롤링 종료 페이지)
def makeUrl(search, start_pg, end_pg):
if start_pg == end_pg:
start_page = makePgNum(start_pg)
url = "https://search.naver.com/search.naver?where=news&sm=tab_pge&query=" + search + "&start=" + str(start_page)
print("생성url: ", url)
return url
else:
urls = []
for i in range(start_pg, end_pg + 1):
page = makePgNum(i)
url = "https://search.naver.com/search.naver?where=news&sm=tab_pge&query=" + search + "&start=" + str(page)
urls.append(url)
print("생성url: ", urls)
return urls
# html에서 원하는 속성 추출하는 함수 만들기 (기사, 추출하려는 속성값)
def news_attrs_crawler(articles,attrs):
attrs_content=[]
for i in articles:
attrs_content.append(i.attrs[attrs])
return attrs_content
# ConnectionError방지
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/98.0.4758.102"}
#html생성해서 기사크롤링하는 함수 만들기(url): 링크를 반환
def articles_crawler(url):
#html 불러오기
original_html = requests.get(i,headers=headers)
html = BeautifulSoup(original_html.text, "html.parser")
url_naver = html.select("div.group_news > ul.list_news > li div.news_area > div.news_info > div.info_group > a.info")
url = news_attrs_crawler(url_naver,'href')
return url
3. 크롤링할 네이버 뉴스 URL 추출하기
#####뉴스크롤링 시작#####
#검색어 입력
search = input("검색할 키워드를 입력해주세요:")
#검색 시작할 페이지 입력
page = int(input("\n크롤링할 시작 페이지를 입력해주세요. ex)1(숫자만입력):")) # ex)1 =1페이지,2=2페이지...
print("\n크롤링할 시작 페이지: ",page,"페이지")
#검색 종료할 페이지 입력
page2 = int(input("\n크롤링할 종료 페이지를 입력해주세요. ex)1(숫자만입력):")) # ex)1 =1페이지,2=2페이지...
print("\n크롤링할 종료 페이지: ",page2,"페이지")
# naver url 생성
url = makeUrl(search,page,page2)
#뉴스 크롤러 실행
news_titles = []
news_url =[]
news_contents =[]
news_dates = []
for i in url:
url = articles_crawler(url)
news_url.append(url)
#제목, 링크, 내용 1차원 리스트로 꺼내는 함수 생성
def makeList(newlist, content):
for i in content:
for j in i:
newlist.append(j)
return newlist
#제목, 링크, 내용 담을 리스트 생성
news_url_1 = []
#1차원 리스트로 만들기(내용 제외)
makeList(news_url_1,news_url)
#NAVER 뉴스만 남기기
final_urls = []
for i in tqdm(range(len(news_url_1))):
if "news.naver.com" in news_url_1[i]:
final_urls.append(news_url_1[i])
else:
pass
4.뉴스 본문 및 날짜 크롤링하기
# 뉴스 내용 크롤링
for i in tqdm(final_urls):
#각 기사 html get하기
news = requests.get(i,headers=headers)
news_html = BeautifulSoup(news.text,"html.parser")
# 뉴스 제목 가져오기
title = news_html.select_one("#ct > div.media_end_head.go_trans > div.media_end_head_title > h2")
if title == None:
title = news_html.select_one("#content > div.end_ct > div > h2")
# 뉴스 본문 가져오기
content = news_html.select("article#dic_area")
if content == []:
content = news_html.select("#articeBody")
# 기사 텍스트만 가져오기
# list합치기
content = ''.join(str(content))
# html태그제거 및 텍스트 다듬기
pattern1 = '<[^>]*>'
title = re.sub(pattern=pattern1, repl='', string=str(title))
content = re.sub(pattern=pattern1, repl='', string=content)
pattern2 = """[\n\n\n\n\n// flash 오류를 우회하기 위한 함수 추가\nfunction _flash_removeCallback() {}"""
content = content.replace(pattern2, '')
news_titles.append(title)
news_contents.append(content)
try:
html_date = news_html.select_one("div#ct> div.media_end_head.go_trans > div.media_end_head_info.nv_notrans > div.media_end_head_info_datestamp > div > span")
news_date = html_date.attrs['data-date-time']
except AttributeError:
news_date = news_html.select_one("#content > div.end_ct > div > div.article_info > span > em")
news_date = re.sub(pattern=pattern1,repl='',string=str(news_date))
# 날짜 가져오기
news_dates.append(news_date)
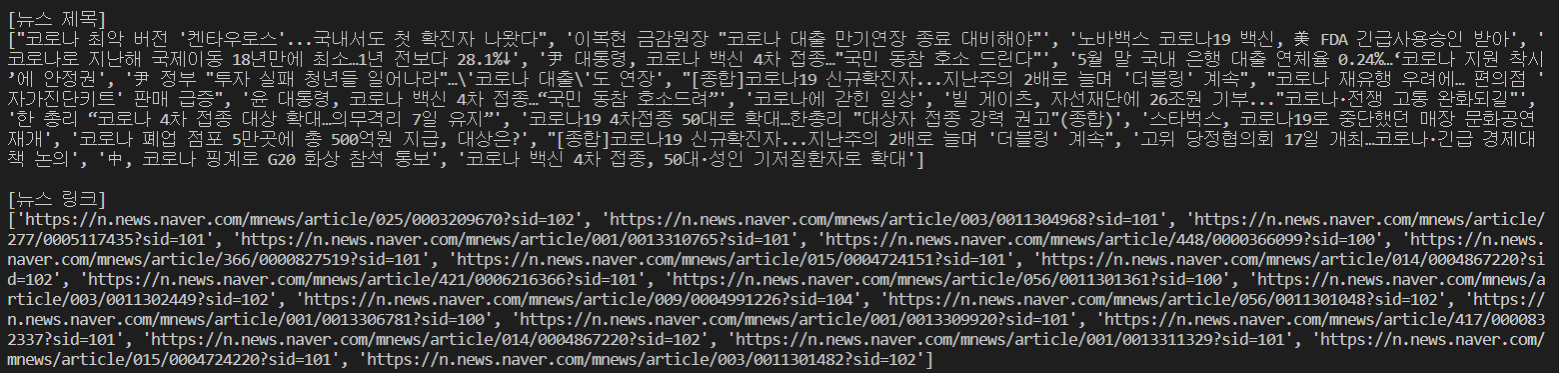
print("검색된 기사 갯수: 총 ",(page2+1-page)*10,'개')
print("\n[뉴스 제목]")
print(news_titles)
print("\n[뉴스 링크]")
print(final_urls)
print("\n[뉴스 내용]")
print(news_contents)
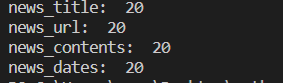
print('news_title: ',len(news_titles))
print('news_url: ',len(final_urls))
print('news_contents: ',len(news_contents))
print('news_dates: ',len(news_dates))
5. 데이터 프레임 만들고 CSV파일로 저장하기
###데이터 프레임으로 만들기###
import pandas as pd
#데이터 프레임 만들기
news_df = pd.DataFrame({'date':news_dates,'title':news_titles,'link':final_urls,'content':news_contents})
news_df
#중복 행 지우기
news_df = news_df.drop_duplicates(keep='first',ignore_index=True)
print("중복 제거 후 행 개수: ",len(news_df))
#데이터 프레임 저장
now = datetime.datetime.now()
news_df.to_csv('{}_{}.csv'.format(search,now.strftime('%Y%m%d_%H시%M분%S초')),encoding='utf-8-sig',index=False)
이렇게 업그레이드 된 크롤러가 완성이 되었습니다 :)
예시 실행화면



전체 코드
#크롤링시 필요한 라이브러리 불러오기
from bs4 import BeautifulSoup
import requests
import re
import datetime
from tqdm import tqdm
import sys
# 페이지 url 형식에 맞게 바꾸어 주는 함수 만들기
#입력된 수를 1, 11, 21, 31 ...만들어 주는 함수
def makePgNum(num):
if num == 1:
return num
elif num == 0:
return num+1
else:
return num+9*(num-1)
# 크롤링할 url 생성하는 함수 만들기(검색어, 크롤링 시작 페이지, 크롤링 종료 페이지)
def makeUrl(search, start_pg, end_pg):
if start_pg == end_pg:
start_page = makePgNum(start_pg)
url = "https://search.naver.com/search.naver?where=news&sm=tab_pge&query=" + search + "&start=" + str(start_page)
print("생성url: ", url)
return url
else:
urls = []
for i in range(start_pg, end_pg + 1):
page = makePgNum(i)
url = "https://search.naver.com/search.naver?where=news&sm=tab_pge&query=" + search + "&start=" + str(page)
urls.append(url)
print("생성url: ", urls)
return urls
# html에서 원하는 속성 추출하는 함수 만들기 (기사, 추출하려는 속성값)
def news_attrs_crawler(articles,attrs):
attrs_content=[]
for i in articles:
attrs_content.append(i.attrs[attrs])
return attrs_content
# ConnectionError방지
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/98.0.4758.102"}
#html생성해서 기사크롤링하는 함수 만들기(url): 링크를 반환
def articles_crawler(url):
#html 불러오기
original_html = requests.get(i,headers=headers)
html = BeautifulSoup(original_html.text, "html.parser")
url_naver = html.select("div.group_news > ul.list_news > li div.news_area > div.news_info > div.info_group > a.info")
url = news_attrs_crawler(url_naver,'href')
return url
#####뉴스크롤링 시작#####
#검색어 입력
search = input("검색할 키워드를 입력해주세요:")
#검색 시작할 페이지 입력
page = int(input("\n크롤링할 시작 페이지를 입력해주세요. ex)1(숫자만입력):")) # ex)1 =1페이지,2=2페이지...
print("\n크롤링할 시작 페이지: ",page,"페이지")
#검색 종료할 페이지 입력
page2 = int(input("\n크롤링할 종료 페이지를 입력해주세요. ex)1(숫자만입력):")) # ex)1 =1페이지,2=2페이지...
print("\n크롤링할 종료 페이지: ",page2,"페이지")
# naver url 생성
url = makeUrl(search,page,page2)
#뉴스 크롤러 실행
news_titles = []
news_url =[]
news_contents =[]
news_dates = []
for i in url:
url = articles_crawler(url)
news_url.append(url)
#제목, 링크, 내용 1차원 리스트로 꺼내는 함수 생성
def makeList(newlist, content):
for i in content:
for j in i:
newlist.append(j)
return newlist
#제목, 링크, 내용 담을 리스트 생성
news_url_1 = []
#1차원 리스트로 만들기(내용 제외)
makeList(news_url_1,news_url)
#NAVER 뉴스만 남기기
final_urls = []
for i in tqdm(range(len(news_url_1))):
if "news.naver.com" in news_url_1[i]:
final_urls.append(news_url_1[i])
else:
pass
# 뉴스 내용 크롤링
for i in tqdm(final_urls):
#각 기사 html get하기
news = requests.get(i,headers=headers)
news_html = BeautifulSoup(news.text,"html.parser")
# 뉴스 제목 가져오기
title = news_html.select_one("#ct > div.media_end_head.go_trans > div.media_end_head_title > h2")
if title == None:
title = news_html.select_one("#content > div.end_ct > div > h2")
# 뉴스 본문 가져오기
content = news_html.select("article#dic_area")
if content == []:
content = news_html.select("#articeBody")
# 기사 텍스트만 가져오기
# list합치기
content = ''.join(str(content))
# html태그제거 및 텍스트 다듬기
pattern1 = '<[^>]*>'
title = re.sub(pattern=pattern1, repl='', string=str(title))
content = re.sub(pattern=pattern1, repl='', string=content)
pattern2 = """[\n\n\n\n\n// flash 오류를 우회하기 위한 함수 추가\nfunction _flash_removeCallback() {}"""
content = content.replace(pattern2, '')
news_titles.append(title)
news_contents.append(content)
try:
html_date = news_html.select_one("div#ct> div.media_end_head.go_trans > div.media_end_head_info.nv_notrans > div.media_end_head_info_datestamp > div > span")
news_date = html_date.attrs['data-date-time']
except AttributeError:
news_date = news_html.select_one("#content > div.end_ct > div > div.article_info > span > em")
news_date = re.sub(pattern=pattern1,repl='',string=str(news_date))
# 날짜 가져오기
news_dates.append(news_date)
print("검색된 기사 갯수: 총 ",(page2+1-page)*10,'개')
print("\n[뉴스 제목]")
print(news_titles)
print("\n[뉴스 링크]")
print(final_urls)
print("\n[뉴스 내용]")
print(news_contents)
print('news_title: ',len(news_titles))
print('news_url: ',len(final_urls))
print('news_contents: ',len(news_contents))
print('news_dates: ',len(news_dates))
###데이터 프레임으로 만들기###
import pandas as pd
#데이터 프레임 만들기
news_df = pd.DataFrame({'date':news_dates,'title':news_titles,'link':final_urls,'content':news_contents})
#중복 행 지우기
news_df = news_df.drop_duplicates(keep='first',ignore_index=True)
print("중복 제거 후 행 개수: ",len(news_df))
#데이터 프레임 저장
now = datetime.datetime.now()
news_df.to_csv('{}_{}.csv'.format(search,now.strftime('%Y%m%d_%H시%M분%S초')),encoding='utf-8-sig',index=False)
참고자료
https://wonhwa.tistory.com/8?category=996518
[python] 원하는 검색어로 네이버 뉴스 크롤링하기(1)
오늘은 전에 알려드린 오픈 API 사용과 더불어 파이썬으로 크롤러 만드는 방법을 소개하도록 하겠습니다. 네이버 오픈 API의 경우 사용하는 방법을 알면 간편하게 뉴스, 블로그, 카페 등등을 크롤
wonhwa.tistory.com
https://wonhwa.tistory.com/11?category=996518
[python] 원하는 검색어로 네이버 뉴스 크롤링하기(2)
오늘은 저번에 올린 네이버 뉴스 크롤링(1)에서 한 단계 업그레이드된 뉴스 크롤러를 공유하려 합니다 :) 1편에서는 뉴스 1페이지만 크롤링을 할 수 있었는데요 2편에서는 여러 페이지를 크롤링
wonhwa.tistory.com
https://wonhwa.tistory.com/46?category=996518
[python] 원하는 검색어로 네이버 뉴스 기사 제목 및 내용만 크롤링하기
안녕하세요! 크롤링 포스팅을 오랜만에 진행하네요~ 이번에는 네이버 뉴스 검색 결과중 네이버 뉴스에 기사가 있는 링크들만 가져와 크롤링을 진행해 보도록 하겠습니다. 지난 크롤러에서 아쉬
wonhwa.tistory.com
마무리
크롤링 하실때 더 빠르고 편하게 하시길 바랍니다:)
기타 의견이 있으시거나 안되는 부분이 있으시다면 댓글 남겨주세요!
++08/10 날짜 크롤링 에러 오류 및 title 길이 수정
++08/11 오류 수정 및 df 중복 행 제거 추가
++23/08/26 뉴스 내용 가져오는 selector 수정