[python] 공공데이터 OPEN API의 xml 을 DataFrame으로 변환하기(feat. 코로나 확진자 수)
안녕하세요~! 오늘은 공공데이터 openAPI의 xml을 Pandas DataFrame으로 변환하여 보도록 하겠습니다.
json에서 DataFrame으로의 변환은 여기를 클릭해서 확인해 주세요 :)
step1. 데이터 활용신청하기
공공데이터 포털
국가에서 보유하고 있는 다양한 데이터를『공공데이터의 제공 및 이용 활성화에 관한 법률(제11956호)』에 따라 개방하여 국민들이 보다 쉽고 용이하게 공유•활용할 수 있도록 공공데이터(Datase
www.data.go.kr
위 사이트에 접속 후 로그인하여 주세요.
여기서 '코로나'를 검색해 주세요.
그 후 스크롤 다운을 하셔서 아래의 내용을 찾으신 후 API 활용신청을 해 주세요.

https://www.data.go.kr/data/15043378/openapi.do
공공데이터활용지원센터_보건복지부 코로나19 시·도발생 현황
코로나19감염증으로 인한 시.도별 신규확진자,신규사망자,격리중인환자수,격리해제환자수등에 대한 현황자료 (이 제공자료는 관련 발생 상황에 대한 정보를 신속 투명하게 공개하기 위한 것으
www.data.go.kr
또는 위의 링크를 클릭하셔도 됩니다 :)
활용신청을 했다면 마이페이지에 들어가 주세요 :)
오픈 API > 개발계정> 공공데이터 활용지원센터_보건복지부 코로나19 시.도 발생 현황을 클릭해 주세요.
그 후 상세설명 클릭하여 요청 값 및 출력 값(컬럼)을 확인해 주세요.
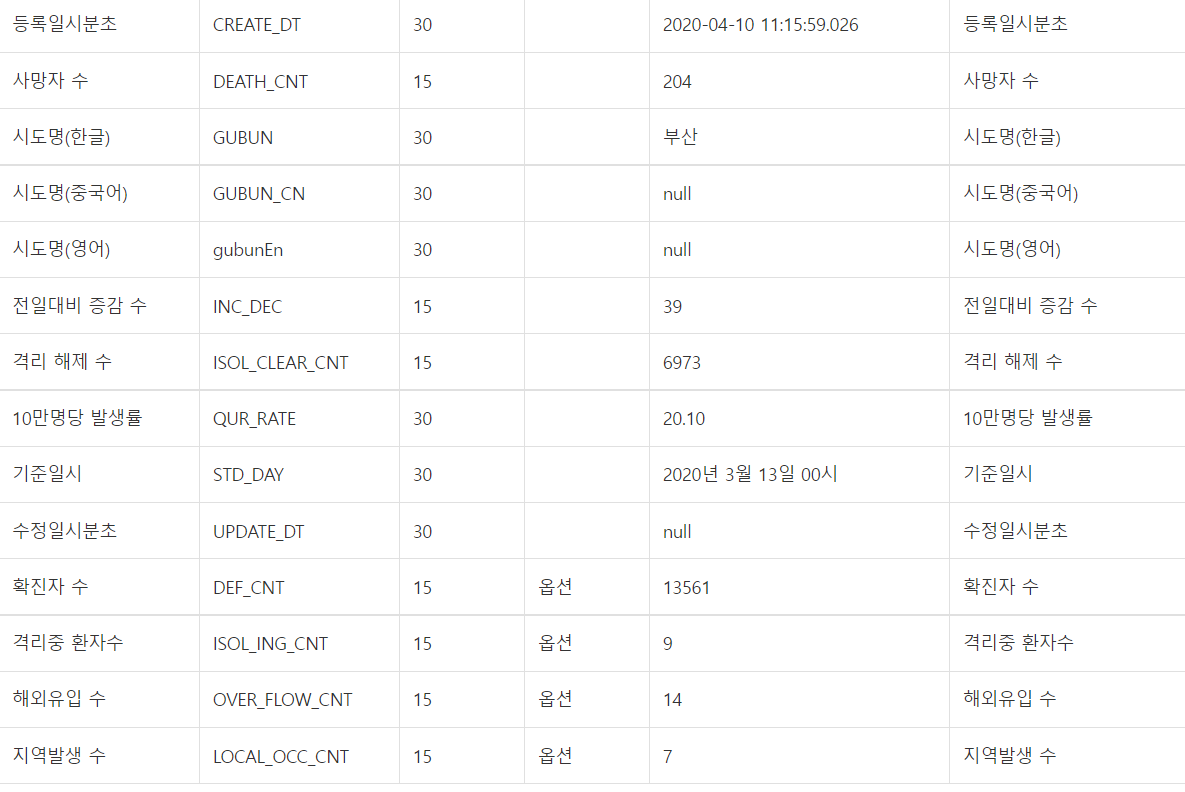
각각의 컬럼 값에 어떤 내용이 있는지 확인하기 위해서 꼭 필요하기 때문에 잘 읽어주세요.
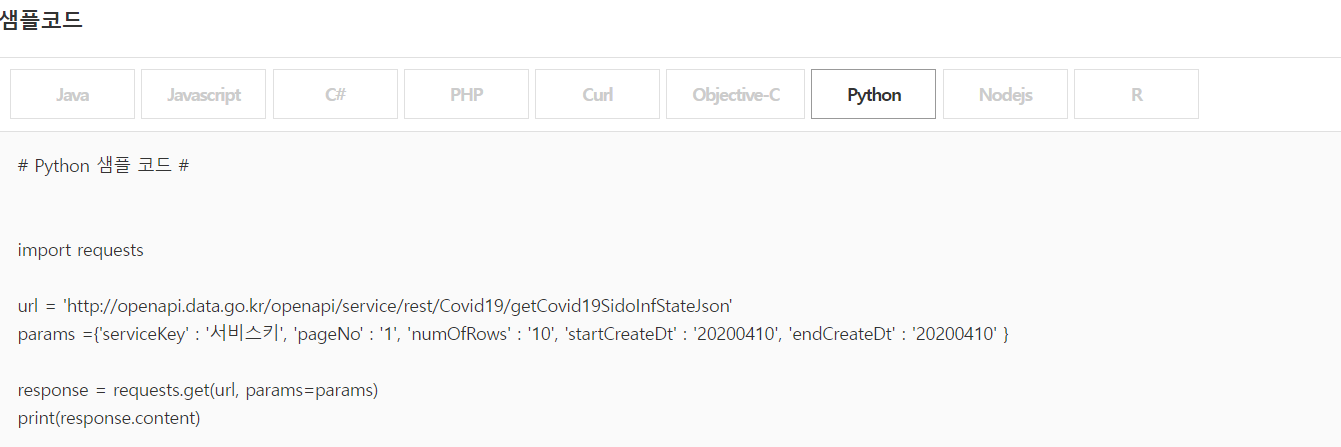
스크롤 다운을 하면 아래의 샘플코드> Python을 클릭하여 코드를 참고하여 xml을 불러오면 됩니다.
step2. API를 사용하여 xml 불러오기
이제부터 데이터를 요청하는 코드를 작성해 보도록 하겠습니다.
# 모듈 import
import requests
import pprint
#인증키 입력
encoding = '발급받은 인코딩 인증키를 복사하여 붙여넣기 해 주세요.'
decoding = '발급받은 디코딩 인증키를 복사하여 붙여넣기 해 주세요.'
#url 입력
url = 'http://openapi.data.go.kr/openapi/service/rest/Covid19/getCovid19SidoInfStateJson'
params ={'serviceKey' : decoding ,
'pageNo' : '1',
'numOfRows' : '10',
'startCreateDt' : '2020',
'endCreateDt' : '20211103' }
response = requests.get(url, params=params)
# xml 내용
content = response.text
# 깔끔한 출력 위한 코드
pp = pprint.PrettyPrinter(indent=4)
#print(pp.pprint(content))위의 내용까지는 전 게시글의 내용과 비슷합니다.
서비스키에 들어갈 수 있는 인증키로는 인코딩과 디코딩이 있는데 인코딩으로 실행하였을 때 오류가 나서 디코딩 인증키를 넣어 요청하였습니다.
step3. xml을 DataFrame으로 변환하기
xml 문서는 <item>안에 각 값이 태그 형식<>으로 들어 있습니다.
이 점을 이용해 뷰티플수프를 이용하여 파싱해보도록 하겠습니다.
### xml을 DataFrame으로 변환하기 ###
from os import name
import xml.etree.ElementTree as et
import pandas as pd
import bs4
from lxml import html
from urllib.parse import urlencode, quote_plus, unquote
## 각 컬럼 값 ## (포털 문서에서 꼭 확인하세요)
"""
SEQ : 게시글번호(국내 시도별 발생현황 고유값)
CREATE_DT: 등록일시분초
DEATH_CNT: 사망자 수
GUBUN: 시도명(한글)
GUBUN_CN: 시도명(중국어)
gubunEn: 시도명(영어)
INC_DEC: 전일대비 증감 수
ISOL_CLEAR_CNT: 격리 해제 수
QUR_RATE: 10만명당 발생률
STD_DAY: 기준일시
UPDATE_DT: 수정일시분초
DEF_CNT: 확진자 수
ISOL_ING_CNT: 격리중 환자수
OVER_FLOW_CNT: 해외유입 수
LOCAL_OCC_CNT: 지역발생 수
"""
#bs4 사용하여 item 태그 분리
xml_obj = bs4.BeautifulSoup(content,'lxml-xml')
rows = xml_obj.findAll('item')
print(rows)출력:

위의 내용만으로 한 눈에 어떤 정보가 있는지 보기 힘들기 때문에 데이터 프레임으로 만들기 전 이에 필요한
각각의 행값, 열 이름값, 데이터값을 추출하는 코드를 작성해 보겠습니다.
# 각 행의 컬럼, 이름, 값을 가지는 리스트 만들기
row_list = [] # 행값
name_list = [] # 열이름값
value_list = [] #데이터값
# xml 안의 데이터 수집
for i in range(0, len(rows)):
columns = rows[i].find_all()
#첫째 행 데이터 수집
for j in range(0,len(columns)):
if i ==0:
# 컬럼 이름 값 저장
name_list.append(columns[j].name)
# 컬럼의 각 데이터 값 저장
value_list.append(columns[j].text)
# 각 행의 value값 전체 저장
row_list.append(value_list)
# 데이터 리스트 값 초기화
value_list=[]여기서 name_list는 열 이름들을 가지고 있고, row_list는 한 행의 값을 가지고 있습니다.
이제 위 변수들에 저장된 내용을 가지고 DataFrame으로 만들어 보겠습니다.
#xml값 DataFrame으로 만들기
corona_df = pd.DataFrame(row_list, columns=name_list)
print(corona_df.head(19))가끔 데이터 프레임을 만들 때 Assertion Error가 나는 경우가 있는데 이때는 columns를 사용하지 마시고 df를 만들면 됩니다.
#xml값 DataFrame으로 만들기
#Assertion Error가 난 경우
corona_df = pd.DataFrame(row_list)
# 이후에 컬럼을 설정해 주세요.출력:
깔끔하게 데이터프레임으로 만들어짐을 확인할 수 있습니다 :)
추가로 만들어진DataFrame을 csv파일로 저장하고 싶다면 아래의 코드를 추가하시면 됩니다.
#DataFrame CSV 파일로 저장
corona_df.to_csv('corona_kr.csv', encoding='utf-8-sig')
전체 코드
# 모듈 import
import requests
import pprint
#인증키 입력
encoding = '발급받은 인코딩 인증키를 복사하여 붙여넣기 해 주세요.'
decoding = '발급받은 디코딩 인증키를 복사하여 붙여넣기 해 주세요.'
#url 입력
url = 'http://openapi.data.go.kr/openapi/service/rest/Covid19/getCovid19SidoInfStateJson'
params ={'serviceKey' : decoding , 'pageNo' : '1', 'numOfRows' : '10', 'startCreateDt' : '2020', 'endCreateDt' : '20211103' }
response = requests.get(url, params=params)
# xml 내용
content = response.text
# 깔끔한 출력 위한 코드
pp = pprint.PrettyPrinter(indent=4)
#print(pp.pprint(content))
### xml을 DataFrame으로 변환하기 ###
from os import name
import xml.etree.ElementTree as et
import pandas as pd
import bs4
from lxml import html
from urllib.parse import urlencode, quote_plus, unquote
## 각 컬럼 값 ## (포털 문서에서 꼭 확인하세요)
"""
SEQ : 게시글번호(국내 시도별 발생현황 고유값)
CREATE_DT: 등록일시분초
DEATH_CNT: 사망자 수
GUBUN: 시도명(한글)
GUBUN_CN: 시도명(중국어)
gubunEn: 시도명(영어)
INC_DEC: 전일대비 증감 수
ISOL_CLEAR_CNT: 격리 해제 수
QUR_RATE: 10만명당 발생률
STD_DAY: 기준일시
UPDATE_DT: 수정일시분초
DEF_CNT: 확진자 수
ISOL_ING_CNT: 격리중 환자수
OVER_FLOW_CNT: 해외유입 수
LOCAL_OCC_CNT: 지역발생 수
"""
#bs4 사용하여 item 태그 분리
xml_obj = bs4.BeautifulSoup(content,'lxml-xml')
rows = xml_obj.findAll('item')
print(rows)
"""
# 컬럼 값 조회용
columns = rows[0].find_all()
print(columns)
"""
# 각 행의 컬럼, 이름, 값을 가지는 리스트 만들기
row_list = [] # 행값
name_list = [] # 열이름값
value_list = [] #데이터값
# xml 안의 데이터 수집
for i in range(0, len(rows)):
columns = rows[i].find_all()
#첫째 행 데이터 수집
for j in range(0,len(columns)):
if i ==0:
# 컬럼 이름 값 저장
name_list.append(columns[j].name)
# 컬럼의 각 데이터 값 저장
value_list.append(columns[j].text)
# 각 행의 value값 전체 저장
row_list.append(value_list)
# 데이터 리스트 값 초기화
value_list=[]
#xml값 DataFrame으로 만들기
corona_df = pd.DataFrame(row_list, columns=name_list)
###assertion error의 경우###
###corona_df = pd.DataFrame(row_list)
print(corona_df.head(19))
#DataFrame CSV 파일로 저장
corona_df.to_csv('corona_kr.csv', encoding='utf-8-sig')
코드 파일
참고 사이트
Python (파이썬) 공공데이터 수집 (Open API - XML)
Python (파이썬) 공공데이터 수집 (Open API - XML)
공공데이터포털의 특징은 자료를 활용을 요약하자면 1. 회원 가입 후 '사용자 인증키'를 생성해야한다. 2. 이후 원하는 데이터를 '활용 신청'을 해서 승인이 떨어지고 활용 권한을 획득해야한다
greendreamtrre.tistory.com
마무리
저번에는 json -> DataFrame 하는 방법을 공유하였고
이번에는 xml -> DataFrame 하는 방법을 공유하였습니다.
다음 시간에는 위에서 만든 corona_df를 가지고 bar_chart_race로 시각하여 보도록 하겠습니다 ^ㅇ^
이해 가지 않는 내용이나 질문이 있으면 댓글로 남겨 주세요 :)