텍스트 유사도란?
빅스비나 시리에게 아래와 같은 내용을 물어본다고 가정합시다.
- (시리야,빅스비야) 이 요리의 레시피가 뭐야?
- (시리야,빅스비야) 이 요리 어떻게 만들어?
이때 두 문장은 같은 의미를 가지고 있지만 컴퓨터는 두 문장을 각각 다른 문장이라 볼 것입니다.
물어보는 내용은 살짝 다르지만 핵심 의미는 같아 시리나 빅스비가 대답을 할 때는 요리 방법을 알려주는 내용을 똑같이 알려주면 될 것입니다.
이렇듯 의미가 비슷한 두 문장이 얼마나 비슷한지 알아보는 것을 '텍스트 유사도(Text Similarity)'라고 합니다.
또한 위와 같은 질문들을 컴퓨터가 인식하려면 두 문장이 서로 얼마나 비슷한지 측정하는 과정을 거쳐야 합니다.
이런 상황에서 여러 텍스트 유사도 측정 방법을 사용하여 두 문장 사이의 유사도를 측정할 수 있습니다.
오늘 포스팅은 딥러닝 기반의 텍스트 유사도 측정 방법을 알아보도록 하겠습니다.
이 방법은 텍스트를 벡터화(임베딩) 후 각 문장의 유사도를 측정하는 방식입니다.
텍스트 벡터화란?
텍스트 벡터(vector)화는
사람이 사용하는 자연어를 기계가 알아들을 수 있도록 0과 1로 수치화하여 나타내는 것을 말합니다.
문장 안에 단어들을 벡터화시키는 방법 중 기본 방법은 원-핫 인코딩(one-hot encoding)이 있습니다.
예를 들어, 컴퓨터에게 요리, 주방, 칼, 포크 이렇게 4 단어를 알려준다고 가정해 봅시다.
이때 원핫인코딩을 사용하면 벡터의 크기는 아래와 같이 4가 됩니다.
| 요리 | 주방 | 칼 | 포크 |
4 단어의 4벡터값
여기서 각 단어를 그 단어에 해당하는 벡터 값의 인덱스를 1로 표현해 주면 그 단어의 벡터 값이 만들어집니다.
요리 = [1, 0, 0, 0]
주방 = [0, 1, 0, 0]
칼 = [0, 0, 1, 0]
포크 = [0, 0, 0, 1]
이런 식으로 각 단어가 원핫 인코딩이 됩니다.
유사도를 구할 때는 Tfidf 벡터 값을 사용하여 측정해 보겠습니다.
TF-IDF란?
- TF(Term Frequency): 한 단어가 하나의 데이터 안에서 등장하는 횟수
- DF(Document Frequency): 문서 빈도 값, 어떤 단어가 다른 문장에도 자주 등장하는지 알려주는 지표.
- IDF(Inverse Document Frequency): DF값의 역수
- TF-IDF = TF x IDF
TF-IDF는 한 단어가 해당 문서에 자주 등장하지만 다른 문서에는 없는 단어일수록 높은 값을 가집니다.
일반 빈도 계산으로는 조사(은/는/이/가), 지시대명사(그, 그것, 이)등의 카운트가 가장 높이 잡히는데
(워드 클라우드에서는 이런 값이 많이 잡히면 불용어 처리를 해줍니다.)
TF-IDF는 이런 조사 값이 많을수록 점수가 낮아져 일반 빈도 계산에서의 문제를 해결해 줍니다.
이제 유사도를 구하는 방법을 알아보도록 합시다.
유사도 측정을 위한 라이브러리 설치
우선 딥러닝, 머신러닝을 사용하기 위해 아래의 명령어를 사용하여 tensorflow와 사이킷런 라이브러리를 설치해 줍니다.
pip install tensorflow #텐서플로우 설치
pip install sklearn #사이킷런 설치
코사인 유사도
코사인 유사도는 두 개의 문장의 벡터 값에서 코사인 각도를 구하는 방법입니다.
-1~1 사이의 값을 가지며
-1 --------------------------------------------------- 1
다름 완전일치
위와 같이 1에 가까울수록 두 문장이 유사함을 나타냅니다.
"이 요리의 레시피를 알려줘."
"이 요리 어떻게 만드는지 알려줘."
이 두 문장을 사용하여 문장 사이의 유사도가 얼마나 되는지 측정해 보도록 하겠습니다.
1. 사이킷런 TfidfVectorizer의 객체 생성
2. .fit_transform() 메서드를 사용하여 tfid벡터화
3. 두 문장을 비교하여 유사도 측정
위의 3 과정을 거치는 코드를 작성해 줍니다.
####### 텍스트 유사도 측정 ######
from sklearn.feature_extraction.text import TfidfVectorizer
sentences = ("이 요리 의 레시피 를 알려줘.",
"이 요리 어떻게 만드는 지 알려줘.")
tfidf_vectorizer = TfidfVectorizer()
# 문장 벡터화 하기(사전 만들기)
tfidf_matrix = tfidf_vectorizer.fit_transform(sentences)
### 코사인 유사도 ###
from sklearn.metrics.pairwise import cosine_similarity
# 첫 번째와 두 번째 문장 비교
cos_similar = cosine_similarity(tfidf_matrix[0:1], tfidf_matrix[1:2])
print("코사인 유사도 측정")
print(cos_similar)출력:
코사인 유사도 측정
[[0.41120706]]
두 문장의 코사인 유사도는 0.411입니다.
유클리디언 유사도
유클리디언 유사도는 가장 기본거리를 측정하는 공식입니다.
중고등학교 수학에서 배우는 좌표평면의 두 점 사이의 거리를 구하는 것을 '유클리디언 거리'라고 합니다.
또한 L2거리(L2-Distance)라고도 불립니다.
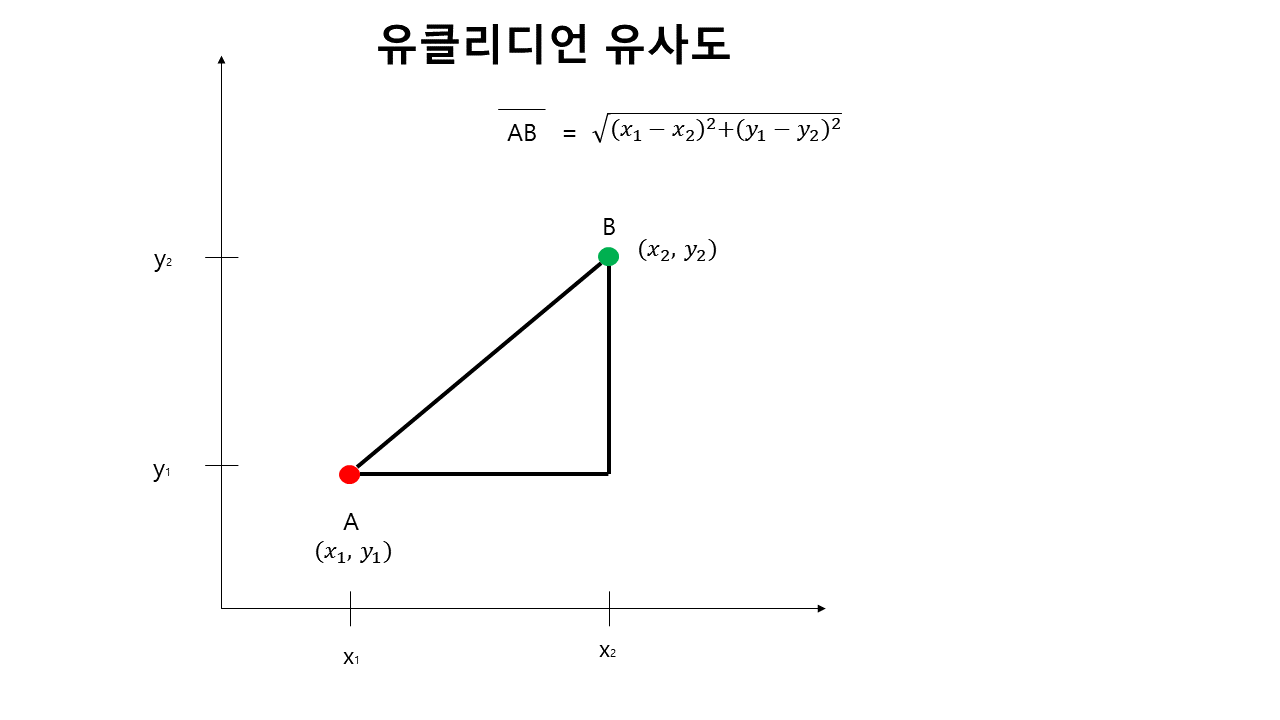
유클리디언 유사도는 거리이기 때문에 결괏값이 1이 넘을 수 있습니다.
이를 방지하기 위해, 0과 1 사이의 값을 갖도록 만들어 줍니다.
벡터화 시, vector값의 합으로 나누어 정규화 후 유사 값을 구해주도록 하겠습니다.
### 유클리디언 유사도 (두 점 사이의 거리 구하기) ###
import numpy as np
from sklearn.metrics.pairwise import euclidean_distances
## 정규화 ##
tfidf_normalized = tfidf_matrix/np.sum(tfidf_matrix)
##유클리디언 유사도##
euc_d_norm = euclidean_distances(tfidf_normalized[0:1],tfidf_normalized[1:2])
print("유클리디언 유사도 측정")
print(euc_d_norm)유클리디언 유사도 측정
[[0.29486722]]
정규화 후 유클리언 유사도는 0.295가 나왔습니다.
맨하탄 유사도
맨하탄 유사도(Manhattan Similarity)는 맨하탄 거리를 통해 유사도를 구하는 방법을 말합니다.
맨하탄 거리는 사각 격자로 이루어진 지도에서 출발에서 도착까지의 최단 거리를 구하는 공식입니다.
또한 L1거리(L1-Distance)라고도 불립니다.
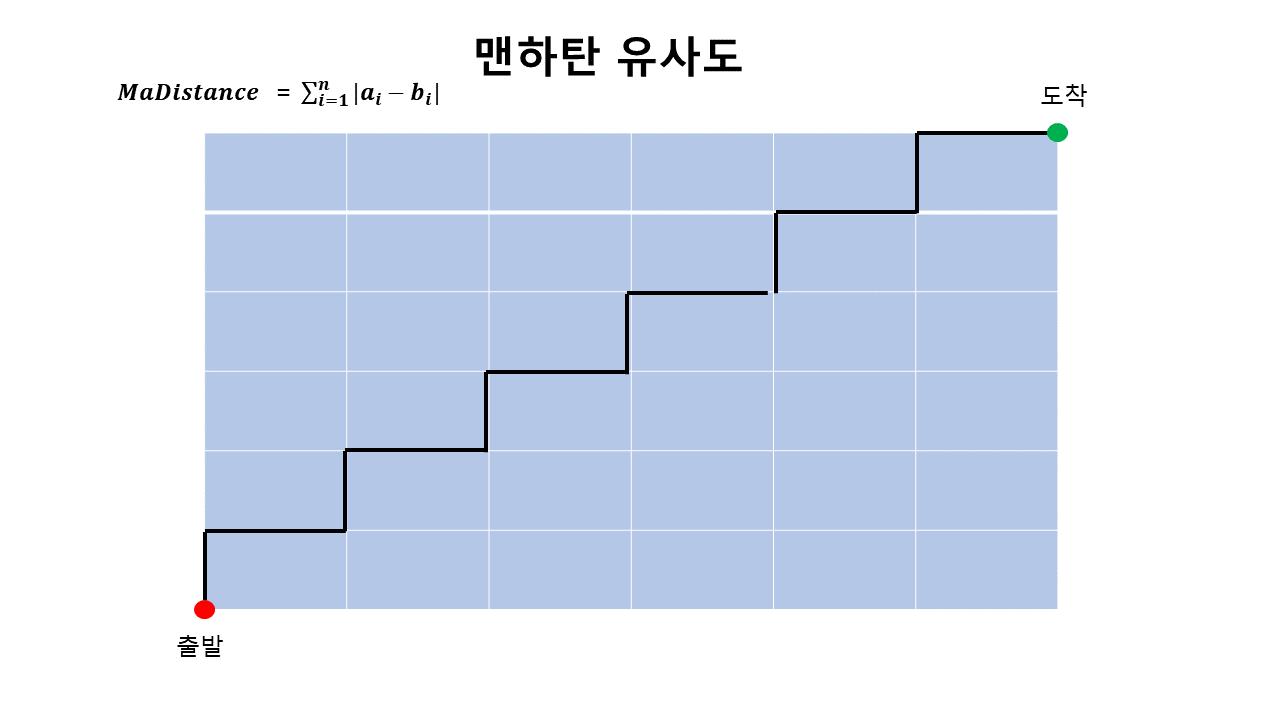
맨하탄 거리도 측정 값이 1이 넘을 수 있어 정규화 된 값을 사용하여 구해주도록 하겠습니다.
### 맨하탄 유사도(격자로 된 거리에서의 최단거리) ###
from sklearn.metrics.pairwise import manhattan_distances
manhattan_d = manhattan_distances(tfidf_normalized[0:1],tfidf_normalized[1:2])
print("맨하탄 유사도 측정")
print(manhattan_d)맨하탄 유사도 측정
[[0.5544387]]
맨하탄 유사도는 0.554로 3가지의 방법 중 측정값이 제일 크게 나왔습니다.
전체 코드
####### 텍스트 유사도 측정 ######
from sklearn.feature_extraction.text import TfidfVectorizer
sentences = ("이 요리 의 레시피 를 알려줘.",
"이 요리 어떻게 만드는 지 알려줘.")
tfidf_vectorizer = TfidfVectorizer()
# 문장 벡터화 하기(사전 만들기)
tfidf_matrix = tfidf_vectorizer.fit_transform(sentences)
### 코사인 유사도 ###
from sklearn.metrics.pairwise import cosine_similarity
# 첫 번째와 두 번째 문장 비교
cos_similar = cosine_similarity(tfidf_matrix[0:1], tfidf_matrix[1:2])
print("코사인 유사도 측정")
print(cos_similar)
### 유클리디언 유사도 (두 점 사이의 거리 구하기) ###
import numpy as np
from sklearn.metrics.pairwise import euclidean_distances
## 정규화 ##
tfidf_normalized = tfidf_matrix/np.sum(tfidf_matrix)
##유클리디언 유사도##
euc_d_norm = euclidean_distances(tfidf_normalized[0:1],tfidf_normalized[1:2])
print("유클리디언 유사도 측정")
print(euc_d_norm)
### 맨하탄 유사도(격자로 된 거리에서의 최단거리) ###
from sklearn.metrics.pairwise import manhattan_distances
manhattan_d = manhattan_distances(tfidf_normalized[0:1],tfidf_normalized[1:2])
print("맨하탄 유사도 측정")
print(manhattan_d)코드 파일
참고 문서
책- 텐서플로2와 머신러닝으로 시작하는 자연어처리(로지스틱 회귀부터 BERT와 GPT2까지)
마무리
오늘은 텍스트 유사도 측정의 3가지 방법을 알아보았는데요
각 측정법마다 유사도가 크게 다른 것을 확인할 수 있었습니다.
때문에 텍스트 분석 시 분석 방향에 맞는 유사도 측정 방법을 잘 선택하시길 바랍니다( ͡• ͜ʖ ͡• )
'NLP' 카테고리의 다른 글
| [python/NLP] 감정분류(한국어)- 리뷰데이터 학습, 평가, 예측까지 (27) | 2022.01.10 |
|---|---|
| [python] 자연어처리(NLP) - Kmeans, K대푯값 군집 분석 (2) | 2021.12.07 |
| [python] 자연어처리 - 영어 (nltk, spaCy) (0) | 2021.11.23 |
| [python] 자연어처리(NLP) - Konlpy로 한국어 형태소 분석하기 (0) | 2021.11.22 |
| [python] 자연어처리(NLP)-텍스트 빈도 분석 (4) | 2021.11.19 |