안녕하세요!
오늘은 konlpy(한국어 형태소 분석기)와 nltk(영어 분석기)를 이용하여
텍스트에 어떤 단어가 많이 나왔는지 알아보도록 하겠습니다.
1. 설치
빈도 분석을 하기 위해서는 konlpy와 nltk를 미리 설치해야 import 하여 사용할 수 있습니다.
- Konlpy설치: KoNLPy 공식문서 참고
설치하기 — KoNLPy 0.5.2 documentation
우분투 Supported: Xenial(16.04.3 LTS), Bionic(18.04.3 LTS), Disco(19.04), Eoan(19.10) Install dependencies # Install Java 1.8 or up $ sudo apt-get install g++ openjdk-8-jdk python3-dev python3-pip curl Install KoNLPy $ python3 -m pip install --upgrade p
konlpy.org
- nltk 설치
pip install nltk
위의 명령어를 프롬프트에서 실행해 주세요.
2. 데이터 준비
설치를 했으면 분석을 하기 위한 데이터가 필요하겠죠?
분석을 위한 영어, 한국어 텍스트를 각각 준비해 줍니다.
저는 한국어 텍스트로는 '황순원 - 소나기'를
영어 텍스트는 스티브 잡스의 유명한 졸업 연설문을 준비하였습니다.
스티브잡스 스탠포드 연설문 mp3 및 steve jobs 연설 스크립트 - 영어천재가 된 홍대리
영어천재가 된 홍대리에서 또 한가지 나왔던 공부하기 좋은 영어회화mp3중 하나가 스티브 잡스 스탠포드 연...
blog.naver.com
다른 분석하고 싶은 텍스트가 있으면 준비하셔서 진행하시면 됩니다. ㅎㅎ
3. 텍스트 읽어오기
####텍스트 읽어오기####
##한국어 텍스트##
f = open("./소나기.txt",'rt',encoding='utf-8')
lines = f.readlines()
line = []
for i in range(len(lines)):
line.append(lines[i])
f.close()
print(line)
##영어 텍스트##
f = open("./stevejobs.txt",'rt',encoding='utf-8')
lines2 = f.readlines()
line2 = []
for i in range(len(lines2)):
line2.append(lines2[i])
f.close()
print(line2)출력:
한국어(line)

영어(line 2)

4. 텍스트에서 특수문자 지워주기
텍스트를 보면, "", \n,...... 한자 등과 같은 텍스트 분석 시 필요 없는 부분들이 있습니다.
이런 특수문자 및 기호를 지워 깔끔한 데이터만 남겨 주도록 하겠습니다.
###특수문자 제거하기###
##한국어##
import re
compile = re.compile("[^ ㄱ-ㅣ가-힣]+")
for i in range(len(line)):
a = compile.sub("",line[i])
line[i] = a
print(line)출력:

영어를 다듬을 때는 대소문자를 통일시켜줘야 합니다.
Apple, apple 이렇게 있을 때 파이썬에서는 각각 단어로 인식하기 때문에
lower()을 이용해 소문자로 통일시켜 주겠습니다. 대문자로 통일하고 싶을 때는. upper()을 사용하면 됩니다.
##영어##
compile = re.compile("\W+")
for i in range(len(line2)):
a = compile.sub(" ",line2[i])
line2[i] = a.lower()
print(line2)출력:

5. 불용어 제거하기
불용어는 사용하지 않는 단어로 특수문자와 같이 분석 시 필요 없는 단어를 말합니다.
이었다, 것이다 등등의 불용어를 지워보도록 하겠습니다.
###불용어 제거하기###
##한국어##
stop_word = ["허 참 세상일도", "내면서", "것이다"] #사용하지 않을 단어 또는 문장 추가
line = [i for i in line if i not in stop_word]영어는 불용어(stopwords)를 모아 놓은 리스트가 있는데 그것을 다운로드하여 제거해 보도록 하겠습니다.
nltk import 후 한 번만 실행해 주시어 다운로드하고 주석처리해주시면 됩니다.
다만 지금 제가 사용하고 있는 텍스트는 문장 단위로 구성되어 있어 적용이 어려운데,
추후 단어 리스트로 분석한다면 아래와 같이 사용하시면 됩니다.
##영어##
import nltk
##처음 한번만 실행 후 주석처리##
nltk.download('all')
nltk.download('wordnet')
nltk.download('stopwords')
##############################
from nltk.corpus import stopwords
stop_word_eng = set(stopwords.words('english'))
line2 = [i for i in line2 if i not in stop_word_eng]6. 품사 분석 및 어근이 같은 부분 동일화, 토큰 화하기
텍스트 리스트가 문장으로 되어 형태소 분석으로 품사를 나누어서 단어 빈도수를 세어 주도록 하겠습니다.
영어는 문장을 토큰화 한 다음 어근 동일화 후에 영어 불용어 처리를해 줍니다.
어근 동일화란 eat- ate- eaten 과같이
의미가 같지만 모양이 조금씩 다른 단어들을 컴퓨터가 같은 단어로 인식할 수 있도록
전 처리하는 과정입니다.
그리고 추후 포스팅에 stemming, Part-Of-Speech와 관련한 설명을 하도록 하겠으니 모르셔도 걱정 마세요ㅎㅎ
오늘은 이런 식으로 분석하는구나 라고 감을 잡으시면 됩니다.
한국어는 Okt를 사용하여 명사만 뽑아 주도록 하겠습니다.
###문장분석###
##한국어##
from konlpy.tag import Okt
okt = Okt()
result =[]
result = [okt.nouns(i) for i in line] #명사만 추출
final_result= [r for i in result for r in i]
print(final_result)출력:

영어는 RegexpTokenizer를 이용해 토큰화 해주도록 하겠습니다.
그 후, PorterStemmer를 이용해 어근 동일화를 해 줍니다.
##영어##
import nltk
from nltk.tokenize import RegexpTokenizer
from nltk.stem.porter import PorterStemmer
ps_stemmer = PorterStemmer()
token = RegexpTokenizer('[\w]+')
result2 = [token.tokenize(i) for i in line2]
middle_result2= [r for i in result2 for r in i]
final_result2 = [ps_stemmer.stem(i) for i in middle_result2 if not i in stop_word_eng] # 불용어 제거
print(final_result2)출력:

+ 6.1 어간 추출 대신 표제어 추출(lemmatization)을 사용했을 때(영어)
##영어##
### 표제어 추출 사용 시 ###
import nltk
from nltk.tokenize import RegexpTokenizer
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
token = RegexpTokenizer('[\w]+')
result_pre_lem = [token.tokenize(i) for i in line2]
middle_pre_lem= [r for i in result_pre_lem for r in i]
final_lem = [lemmatizer.lemmatize(i) for i in middle_pre_lem if not i in stop_word_eng] # 불용어 제거
print(final_lem)
7. 단어 수 세기
이렇게 다듬은 단어들을 pandas로 같은 단어를 세어
Series로 텍스트에서 제일 많이 나온 단어 10개만 반환하여 보도록 하겠습니다.
###텍스트에서 많이 나온 단어###
import pandas as pd
##한국어##
korean = pd.Series(final_result).value_counts().head(10)
print("한국어 top 10")
print(korean)
##영어##
english = pd.Series(final_result2).value_counts().head(10)
print("English top 10")
print(english)출력:
한국어

영어

이렇게 많이 나온 단어들을 확인할 수 있습니다.
+ 7.1 lemmatization 사용 시 빈도 순위
###텍스트에서 많이 나온 단어###
###표제어 추출 시#####
import pandas as pd
##영어##
english = pd.Series(final_lem).value_counts().head(10)
print("English top 10")
english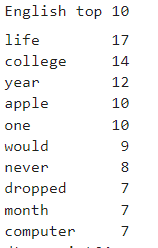
전체 코드
####텍스트 읽어오기####
##한국어 텍스트##
f = open("./소나기.txt",'rt',encoding='utf-8')
lines = f.readlines()
line = []
for i in range(len(lines)):
line.append(lines[i])
f.close()
#print(line)
##영어 텍스트##
f = open("./stevejobs.txt",'rt',encoding='utf-8')
lines2 = f.readlines()
line2 = []
for i in range(len(lines2)):
line2.append(lines2[i])
f.close()
#print(line2)
###특수문자 제거하기###
##한국어##
import re
compile = re.compile("[^ ㄱ-ㅣ가-힣]+")
for i in range(len(line)):
a = compile.sub("",line[i])
line[i] = a
#print(line)
##영어##
compile = re.compile("\W+")
for i in range(len(line2)):
a = compile.sub(" ",line2[i])
line2[i] = a.lower()
#print(line2)
###불용어 제거하기###
##한국어##
stop_word = ["허 참 세상일도", "내면서", "것이다"] #사용하지 않을 단어 또는 문장 추가
line = [i for i in line if i not in stop_word]
#print(line)
##영어##
import nltk
##처음 한번만 실행 후 주석처리##
"""nltk.download('all')
nltk.download('wordnet')
nltk.download('stopwords')"""
##############################
from nltk.corpus import stopwords
stop_word_eng = set(stopwords.words('english'))
line2 = [i for i in line2 if i not in stop_word_eng]
###문장분석###
##한국어##
from konlpy.tag import Okt
okt = Okt()
result =[]
result = [okt.nouns(i) for i in line] #명사만 추출
final_result= [r for i in result for r in i]
#print(final_result)
##영어##
import nltk
from nltk.tokenize import RegexpTokenizer
from nltk.stem.porter import PorterStemmer
ps_stemmer = PorterStemmer()
token = RegexpTokenizer('[\w]+')
result2 = [token.tokenize(i) for i in line2]
middle_result2= [r for i in result2 for r in i]
final_result2 = [ps_stemmer.stem(i) for i in middle_result2 if not i in stop_word_eng] # 불용어 제거
#print(final_result2)
###텍스트에서 많이 나온 단어###
import pandas as pd
##한국어##
korean = pd.Series(final_result).value_counts().head(10)
print("한국어 top 10")
print(korean)
##영어##
english = pd.Series(final_result2).value_counts().head(10)
print("English top 10")
print(english)
#########영어 표제어 추출 시 ###########
##영어##
### 표제어 추출 사용 시 ###
import nltk
from nltk.tokenize import RegexpTokenizer
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
token = RegexpTokenizer('[\w]+')
result_pre_lem = [token.tokenize(i) for i in line2]
middle_pre_lem= [r for i in result_pre_lem for r in i]
final_lem = [lemmatizer.lemmatize(i) for i in middle_pre_lem if not i in stop_word_eng] # 불용어 제거
#print(final_lem)
###텍스트에서 많이 나온 단어###
###표제어 추출 시#####
import pandas as pd
##영어##
english2 = pd.Series(final_lem).value_counts().head(10)
print("English top 10")
english2
코드 파일
+ 영어분석만 있는 코드
참고자료
1. 책 잡아라! 텍스트마이닝 with 파이썬(지금 바로 할 수 있는 데이터 추출과 분석) -서대호
2. 어간 추출과 표제어 추출
03) 어간 추출(Stemming) and 표제어 추출(Lemmatization)
정규화 기법 중 코퍼스에 있는 단어의 개수를 줄일 수 있는 기법인 표제어 추출(lemmatization)과 어간 추출(stemming)의 개념에 대해서 알아봅니다. 또한 이 ...
wikidocs.net
마무리
오늘 이렇게 자연어 처리 텍스트 빈도 분석을 해 보았는데요.
텍스트 양이 더 많고 불용어 처리를 섬세히 해주면 더 좋은 결과가 나올 것 같습니다 ㅎㅎ
좋아하는 가수의 가사나 이런 걸로도 분석해도 재밌을 것 같네요.
다른 아이디어가 있으면 댓글로 남겨주세요 :)
'NLP' 카테고리의 다른 글
| [python] 자연어처리(NLP) - 텍스트 유사도 (0) | 2021.11.26 |
|---|---|
| [python] 자연어처리 - 영어 (nltk, spaCy) (0) | 2021.11.23 |
| [python] 자연어처리(NLP) - Konlpy로 한국어 형태소 분석하기 (0) | 2021.11.22 |
| [python/konlpy] SystemErrorjava.nio.file.InvalidPathException 오류해결 (0) | 2021.11.09 |
| [Python/konlpy] (Jupyter notebook) import konlpy 오류해결(tweepy) (2) | 2021.09.30 |